Kubernetes K3S: the simplest high availability cluster between two redundant servers
With the synchronous replication and automatic failover provided by Evidian SafeKit
The solution for Kubernetes K3S
Evidian SafeKit brings high availability to Kubernetes K3S between two redundant servers. This article explains how to implement quickly a Kubernetes cluster on 2 nodes without NFS external storage, without an external configuration database and without specific skills.
Note that SafeKit is a generic product. You can implement with the same product real-time replication and failover of directories and services, databases, Docker, Podman, full Hyper-V or KVM virtual machines, Cloud applications (see the module list).
This clustering solution is recognized as the simplest to implement by our customers and partners. The SafeKit solution is the perfect solution for running Kubernetes applications on premise and on 2 nodes.
We have chosen K3S as the Kubernetes engine because it is a lightweight solution for IoT & Edge computing.
The k3s.safe mirror module implements:
- 2 active K3S masters/agents running pods
- replication of the K3S configuration database (MariaDB)
- replication of persistent volumes (implemented by NFS client dynamic provisionner storage class: nfs-client)
- virtual IP address, automatic failover, automatic failback
How it works?
The following table explains how the solution is working on 2 nodes. Other nodes with K3S agents (without SafeKit) can be added for horizontal scalability.
| Kubernetes K3S components | |
| SafeKit PRIM node | SafeKit SECOND node |
| K3S (master and agent) is running pods on the primary node | K3S (master and agent) is running pods on the secondary node |
NFS Server is running on the primary node with:
|
Persistent volumes are replicated synchronously and in real-time by SafeKit on the secondary node |
MariaDB server is running on the primary node with:
|
The configuration database is replicated synchronously and in real-time by SafeKit on the secondary node |
A simple solution
SafeKit is the simplest high availabiliy solution for running Kubernetes applications on 2 nodes and on premise.
| SafeKit | Benefits |
| Synchronous real-time replication for persistent volumes | No external NAS/NFS storage for persistent volumes |
| Only 2 nodes for HA of Kubernetes | No need for 3 nodes like with etcd database |
| Same simple product for virtual IP address, replication, failover, failback, administration, maintenance | Avoid different technologies for virtual IP (metal-lb, BGP), HA of persistent volumes, HA of configuration database |
| Supports disaster recovery with two remote nodes | Avoid replicated NAS storage |
Partners, the success with SafeKit
This platform agnostic solution is ideal for a partner reselling a critical application and who wants to provide a redundancy and high availability option easy to deploy to many customers.
With many references in many countries won by partners, SafeKit has proven to be the easiest solution to implement for redundancy and high availability of building management, video management, access control, SCADA software...







Step 1. File replication at byte level in a mirror cluster
This step corresponds to the following figure. Server 1 (PRIM) runs the Kubernetes K3S components explained in the previous table. Clients are connected to the virtual IP address of the mirror cluster. SafeKit replicates in real time files opened by the Kubernetes K3S components. Only changes made by the components in the files are replicated across the network, thus limiting traffic (byte-level file replication).
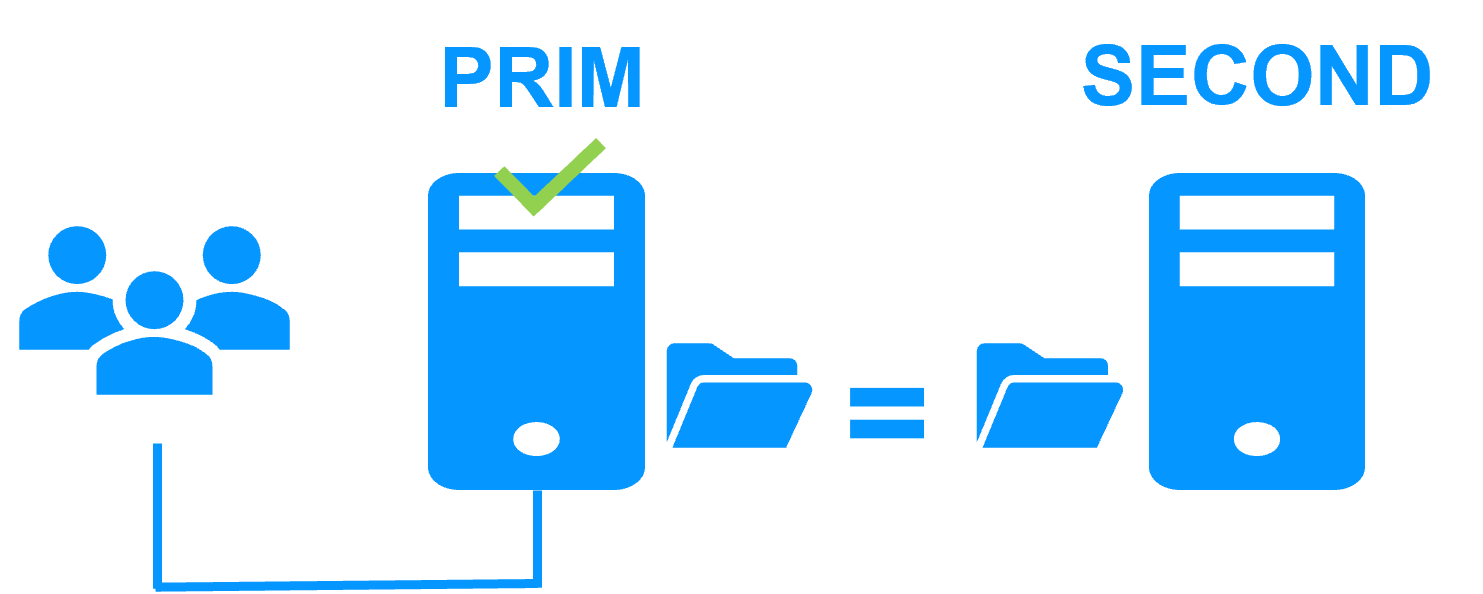
With a software data replication at the file level, only names of directories are configured in SafeKit. There are no pre-requisites on disk organization for the two servers. Directories to replicate may be located in the system disk. SafeKit implements synchronous replication with no data loss on failure contrary to asynchronous replication.
Step 2. Failover
When Server 1 fails, Server 2 takes over. SafeKit switches the cluster's virtual IP address and restarts the Kubernetes K3S components automatically on Server 2. The components find the files replicated by SafeKit uptodate on Server 2, thanks to the synchronous replication between Server 1 and Server 2. The components continue to run on Server 2 by locally modifying their files that are no longer replicated to Server 1.
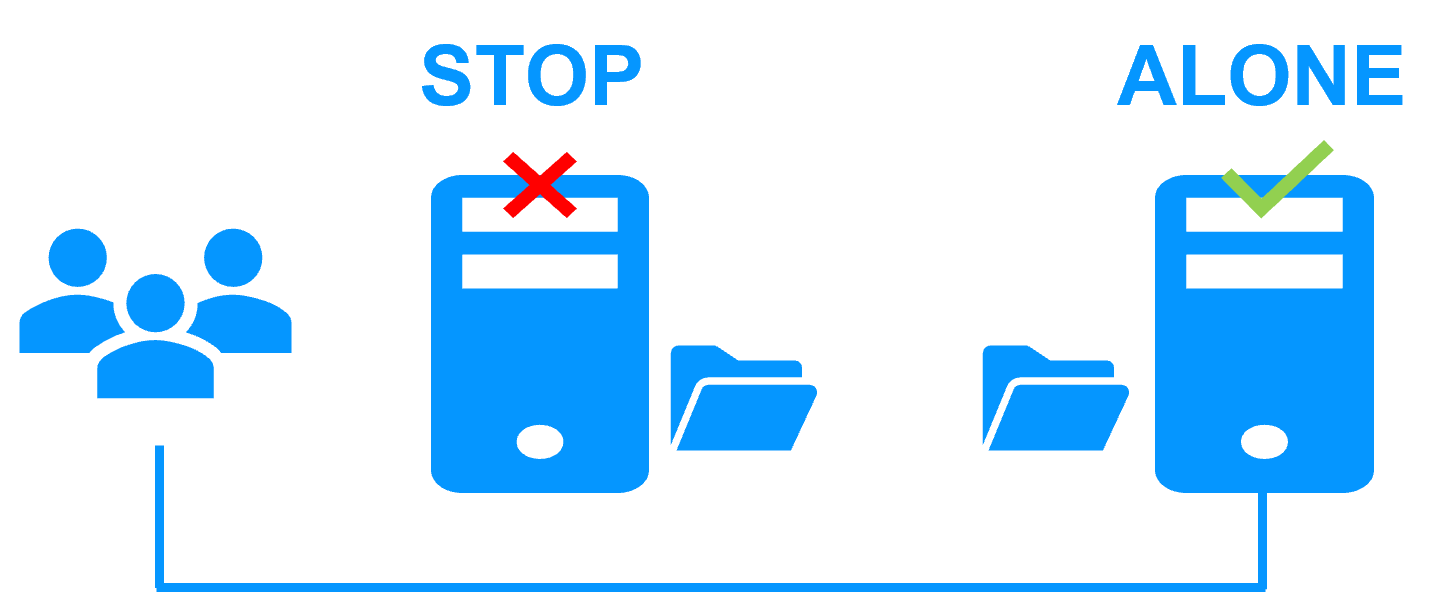
The failover time is equal to the fault-detection time (set to 30 seconds by default) plus the components start-up time. Unlike disk replication solutions, there is no delay for remounting file system and running file system recovery procedures.
Step 3. Failback and reintegration
Failback involves restarting Server 1 after fixing the problem that caused it to fail. SafeKit automatically resynchronizes the files, updating only the files modified on Server 2 while Server 1 was halted. This reintegration takes place without disturbing the Kubernetes K3S components, which can continue running on Server 2.
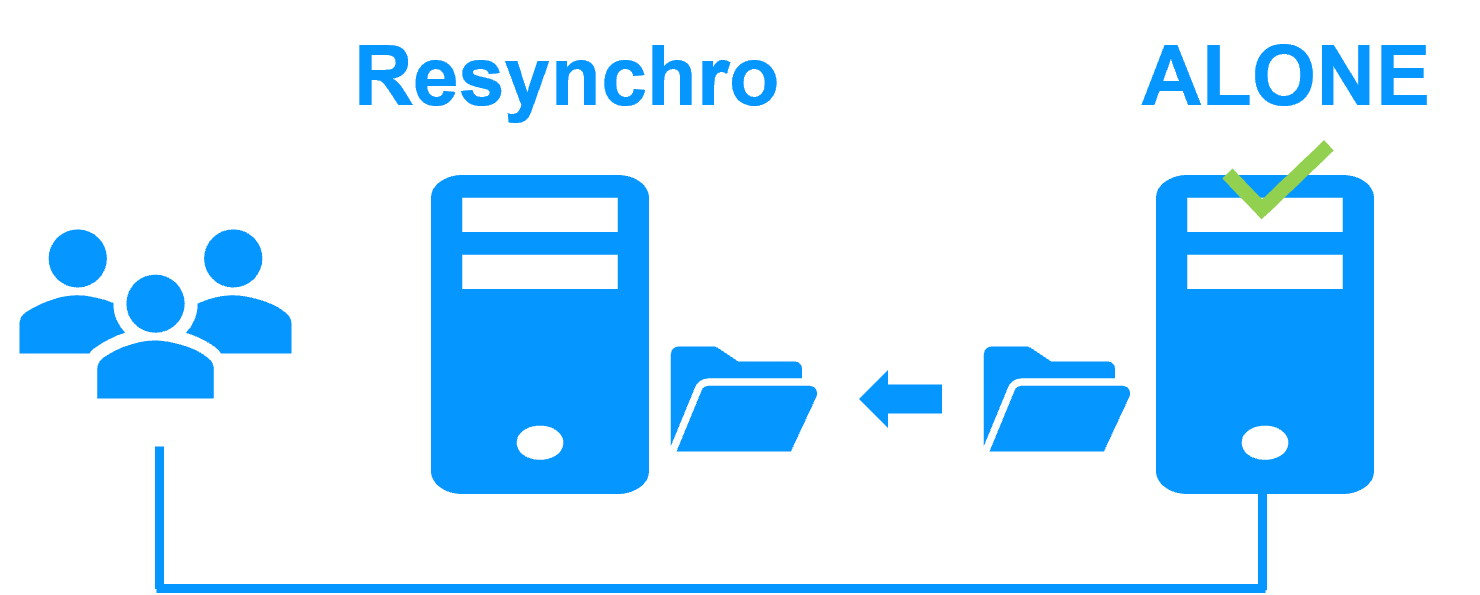
If SafeKit was cleanly stopped on server 1, then at its restart, only the modified zones inside files are resynchronized, according to modification tracking bitmaps.
If server 1 crashed (power off), the modification bitmaps are not reliable and not used. All the files bearing a modification timestamp more recent than the last known synchronization point are resynchronized.
Step 4. Return to byte-level file replication in the mirror cluster
After reintegration, the files are once again in mirror mode, as in step 1. The system is back in high-availability mode, with the Kubernetes K3S components running on Server 2 and SafeKit replicating file updates to the secondary Server 1.
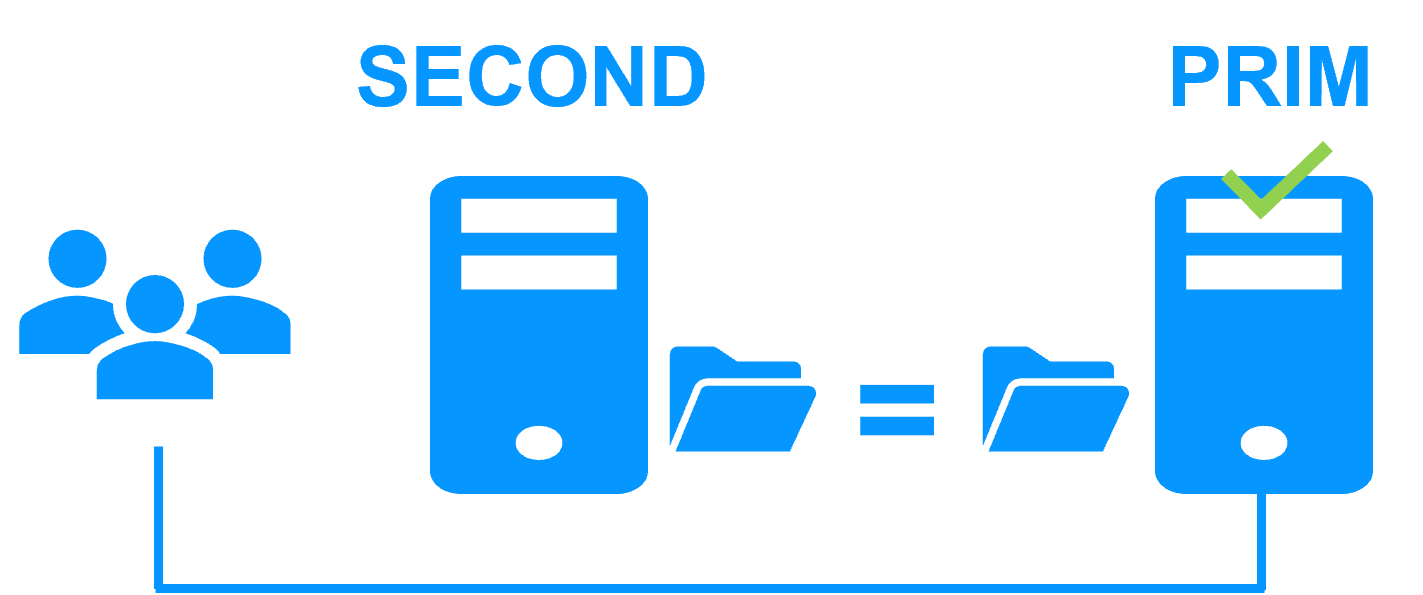
If the administrator wishes the Kubernetes K3S components to run on Server 1, he/she can execute a "swap" command either manually at an appropriate time, or automatically through configuration.
1. Download packages
- Download the free version of SafeKit 7.5 (safekit_xx.bin)
- Download the k3s.safe Linux module
- Download the k3sconfig.sh script
- Documentation (pptx)
Note: the k3sconfig.sh script installs K3S, MariaDB, NFS, SafeKit on 2 Linux Ubuntu 20.04 nodes.
2. First on both nodes
On 2 Linux Ubuntu 20.04 nodes, as root:
- Make sure the node has internet access (could be through a proxy)
- Copy k3sconfig.sh, k3s.safe and the safekit_xx.bin package into a directory and cd into it
- Rename the .bin file as "safekit.bin"
- Make sure k3sconfig.sh and safekit.bin are executable.
- Edit the k3sconfig.sh script and customize the environment variables according to your environment (including a virtual IP)
- Execute on both nodes:
./k3sconfig.sh prereq
The script will:
- Install required debian packages: alien, nfs-kernel-server, nfs-common, mariadb-server
- Secure mariadb installation
- Create directories for file replication
- Prepare the NFS server for sharing replicated directories
- Install SafeKit
3. On the first node
Execute on the first node: ./k3sconfig.sh first
The script will:
- Create the K3S configuration database and the k3s user
- Create the replicated storage volume file (sparse file) and format it as an xfs filesystem
- Create the safekit cluster configuration and apply it
- Install and configure the k3s.safe module on the cluster
- Start the k3s module as "prim" on the first node
- Download, install and start k3s
- Download and install nfs-subdir-external-provisioner Helm chart
- Display K3S token (to be used during second node installation phase)
4. On the second node
Execute on the second node: ./k3sconfig.sh second <token>
- <token> is the string displayed at the end of the "k3sconfig.sh first" execution on the first node
The script will:
- Make sure the k3s module is started as prim on the first node
- Install k3s on the second node
- Start the k3s module
5. Check that the k3s SafeKit module is running on both nodes
Check with this command on both nodes: /opt/safekit/safekit –H "*" state
The reply should be similar to the image.
/opt/safekit/safekit –H "*" state
---------------- Server=http://10.0.0.20:9010 ----------------
admin action=exec
--------------------- k3s State ---------------------
Local (127.0.0.1) : PRIM (Service : Available)(Color : Green)
Success
---------------- Server=http://10.0.0.21:9010 ----------------
admin action=exec
--------------------- k3s State ---------------------
Local (127.0.0.1) : SECOND (Service : Available)(Color : Green)
Success
6. Start the SafeKit web console to administer the cluster
- Connect a browser to the SafeKit web console url
http://server0-IP:9010. - You should see a page similar to the image.
- Check with Linux command lines that K3S is started on both nodes (started in
start_primandstart_second) and that MariaDB is started on the primary node (started instart_prim).

7. Testing
- Stop the PRIM node by scrolling down its contextual menu and clicking
Stop. - Verify that there is a failover on the SECOND node which should become ALONE (green).
- And with command lines on Linux, check the failover of services (stopped on node 1 in the
stop_primscript and started on node 2 in thestart_primscript). MariaDB and K3S should run on node2.
![]()
If ALONE (green) is not reached on node2, analyze why with the module log of node 2.
- click on
node2to display the module log. - example of a SQL Server module log where the service name in
start_primis invalid. The sqlserver.exe process is monitored but as it is not started, at the end the module stops.
![]()
If everything is okay, initiate a start on node1, which will resynchronize the replicated directories from node2.
If things go wrong, stop node2 and force the start as primary of node1, which will restart with its locally healthy data at the time of the stop.

8. Try the cluster with a Kubernetes application like WordPress
You have the example of a WordPress installation in the image: a web portal with a backend database implemented by pods.
You can deploy your own application in the same way.
WordPress is automatically highly available:
- with its data (php + database) in persistent volumes replicated in real-time by SafeKit
- with a virtual IP address to access the WordPress site for users
- with automatic failover and automatic failback
Notes:
- The WordPress chart defines a load balanced service that listens on <service.port> and <service.httpsport> ports.
- WordPress is accessible through the url:
http://<virtual-ip>:<service.port>. - The virtual IP is managed by SafeKit and automatically switched in case of failover.
- By default, K3S implements load balancers with Klipper.
- Klipper listens on <virtual ip>:<service.port> and routes the TCP/IP packets to the IP address and port of the WordPress pod that it has selected.
$ export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm install my-release bitnami/wordpress --set global.storageClass=nfs-client --set service.port=8099,service.httpsPort=4439
9. Support
- For getting support, take 2 SafeKit
Snapshots(2 .zip files), one for each node. - If you have an account on https://support.evidian.com, upload them in the call desk tool.

10. If necessary, configure a splitbrain checker
- See below "What are the different scenarios in case of network isolation in a cluster?" to know if you need to configure a splitbrain checker.
- In the module configuration, click on
Advanced Configuration(see image) to edituserconfig.xml. - Declare the splitbrain checker by adding in the
<check>section ofuserconfig.xml:<service> ... <check> ... <splitbrain ident="witness" exec="ping" arg="witness IP"/> </check> Save and applythe new configuration to redeploy the modified userconfig.xml file on both nodes (module must be stopped on both nodes to save and apply).
Parameters:
ident="witness"identifies the witness with a resource name:splitbrain.witness. You can change this value to identify the witness.exec="ping"references the ping code to execute. Do not change this value.arg="witness IP"is an argument for the ping. Change this value with the IP of the witness (a robust element, typically a router).

A single network
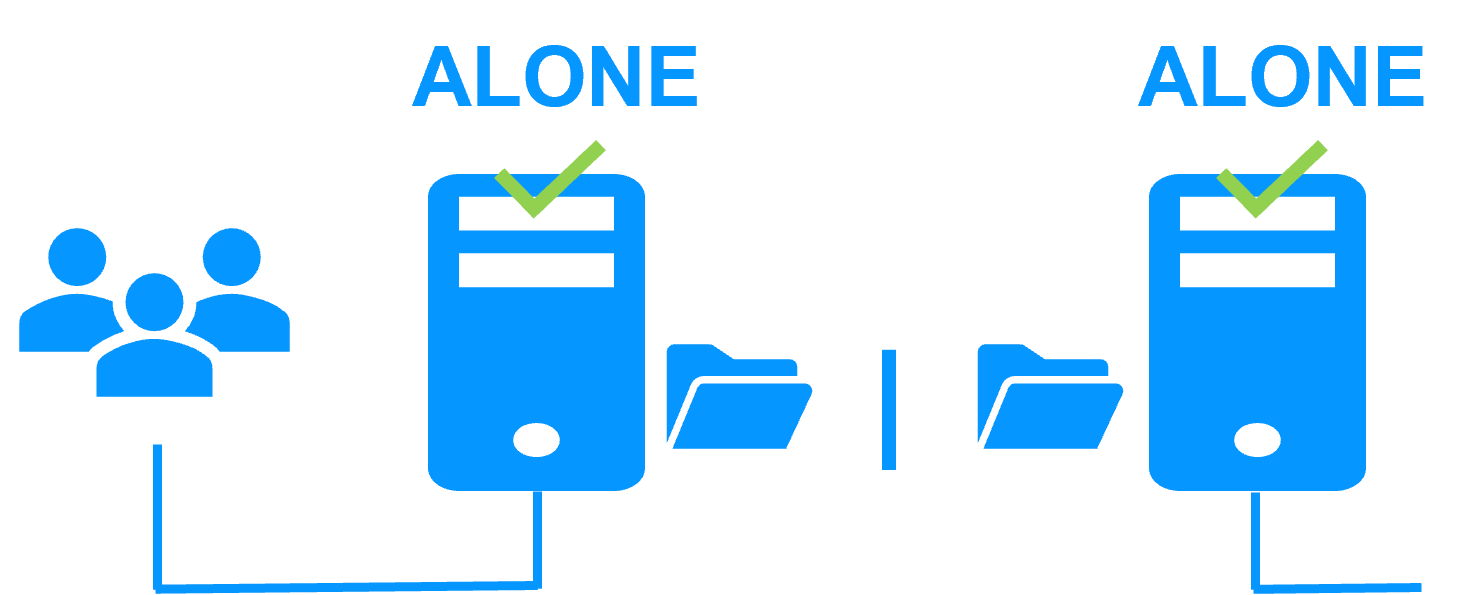
When there is a network isolation, the default behavior is:
- as heartbeats are lost for each node, each node goes to ALONE and runs the application with its virtual IP address (double execution of the application modifying its local data),
- when the isolation is repaired, one ALONE node is forced to stop and to resynchronize its data from the other node,
- at the end the cluster is PRIM-SECOND (or SECOND-PRIM according the duplicate virtual IP address detection made by Windows).
Two networks with a dedicated replication network
When there is a network isolation, the behavior with a dedicated replication network is:
- a dedicated replication network is implemented on a private network,
- heartbeats on the production network are lost (isolated network),
- heartbeats on the replication network are working (not isolated network),
- the cluster stays in PRIM/SECOND state.
A single network and a splitbrain checker
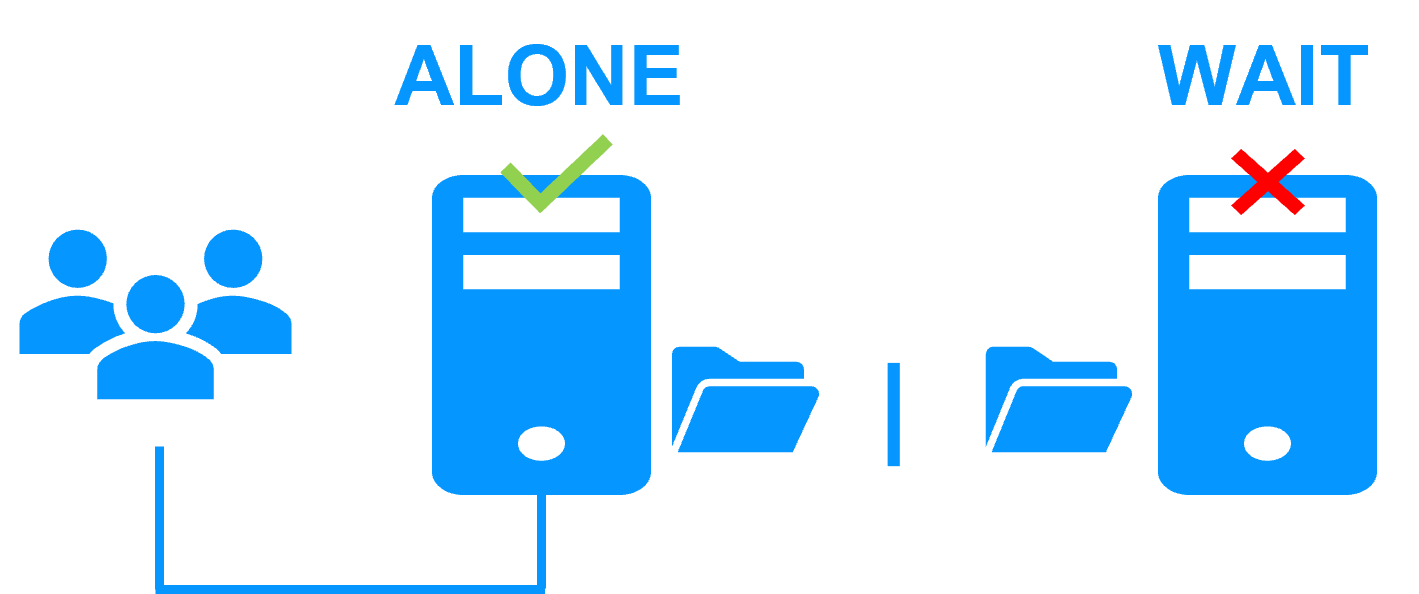
When there is a network isolation, the behavior with a split-brain checker is:
- a split-brain checker has been configured with the IP address of a witness (typically a router),
- the split-brain checker operates when a server goes from PRIM to ALONE or from SECOND to ALONE,
- in case of network isolation, before going to ALONE, both nodes test the IP address,
- the node which can access the IP address goes to ALONE, the other one goes to WAIT,
- when the isolation is repaired, the WAIT node resynchronizes its data and becomes SECOND.
Note: If the witness is down or disconnected, both nodes go to WAIT and the application is no more running. That's why you must choose a robust witness like a router.
Why a replication of a few Tera-bytes?
Resynchronization time after a failure (step 3)
- 1 Gb/s network ≈ 3 Hours for 1 Tera-bytes.
- 10 Gb/s network ≈ 1 Hour for 1 Tera-bytes or less depending on disk write performances.
Alternative
- For a large volume of data, use external shared storage.
- More expensive, more complex.
Why a replication < 1,000,000 files?
- Resynchronization time performance after a failure (step 3).
- Time to check each file between both nodes.
Alternative
- Put the many files to replicate in a virtual hard disk / virtual machine.
- Only the files representing the virtual hard disk / virtual machine will be replicated and resynchronized in this case.
Why a failover ≤ 32 replicated VMs?
- Each VM runs in an independent mirror module.
- Maximum of 32 mirror modules running on the same cluster.
Alternative
- Use an external shared storage and another VM clustering solution.
- More expensive, more complex.
Why a LAN/VLAN network between remote sites?
- Automatic failover of the virtual IP address with 2 nodes in the same subnet.
- Good bandwidth for resynchronization (step 3) and good latency for synchronous replication (typically a round-trip of less than 2ms).
Alternative
- Use a load balancer for the virtual IP address if the 2 nodes are in 2 subnets (supported by SafeKit, especially in the cloud).
- Use backup solutions with asynchronous replication for high latency network.
Network load balancing and failover |
|
| Windows farm | Linux farm |
| Generic Windows farm > | Generic Linux farm > |
| Microsoft IIS > | - |
| NGINX > | |
| Apache > | |
| Amazon AWS farm > | |
| Microsoft Azure farm > | |
| Google GCP farm > | |
| Other cloud > | |
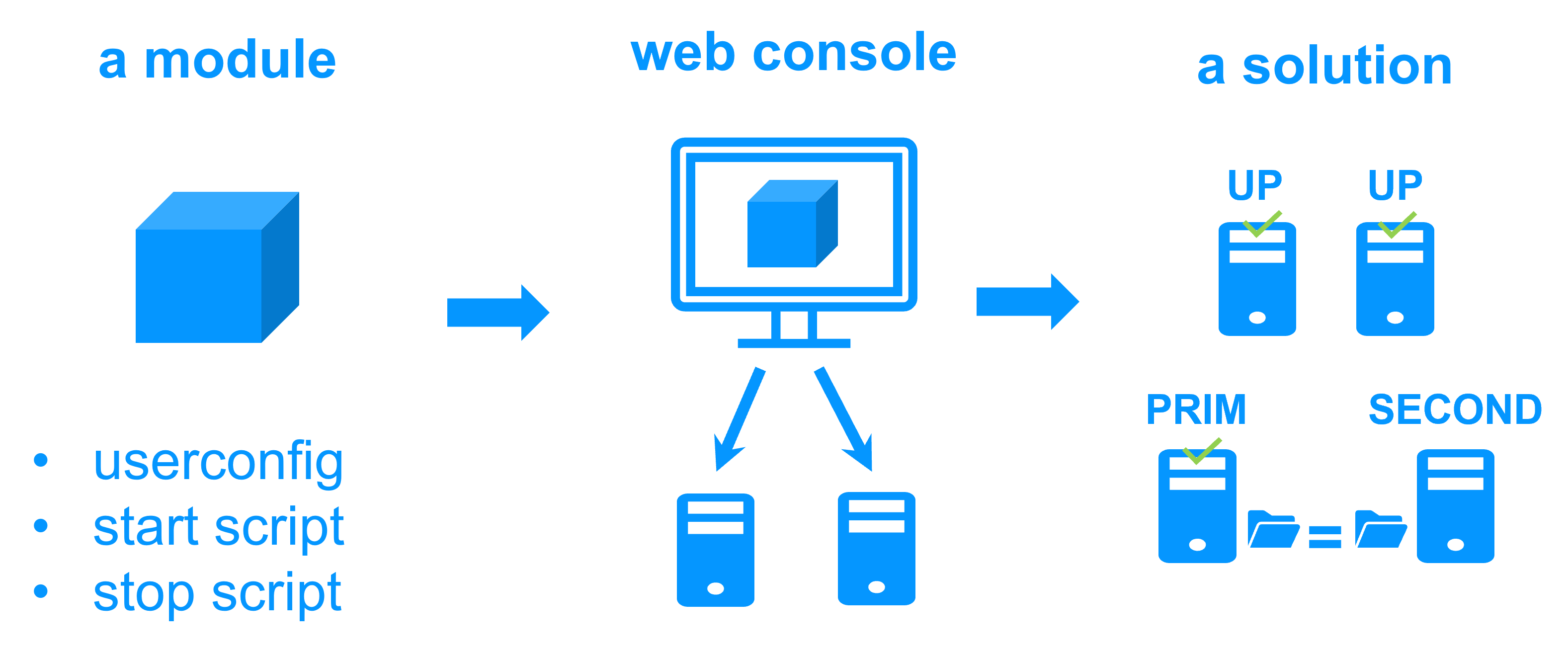
Advanced clustering architectures
Several modules can be deployed on the same cluster. Thus, advanced clustering architectures can be implemented:
- the farm+mirror cluster built by deploying a farm module and a mirror module on the same cluster,
- the active/active cluster with replication built by deploying several mirror modules on 2 servers,
- the Hyper-V cluster or KVM cluster with real-time replication and failover of full virtual machines between 2 active hypervisors,
- the N-1 cluster built by deploying N mirror modules on N+1 servers.

- Demonstration
- Examples of redundancy and high availability solution
- Evidian SafeKit sold in many different countries with Milestone
- 2 solutions: virtual machine cluster or application cluster
- Distinctive advantages
- More information on the web site










Evidian SafeKit mirror cluster with real-time file replication and failover |
|
|
3 products in 1 More info >  |
|
|
Very simple configuration More info >  |
|
|
Synchronous replication More info > 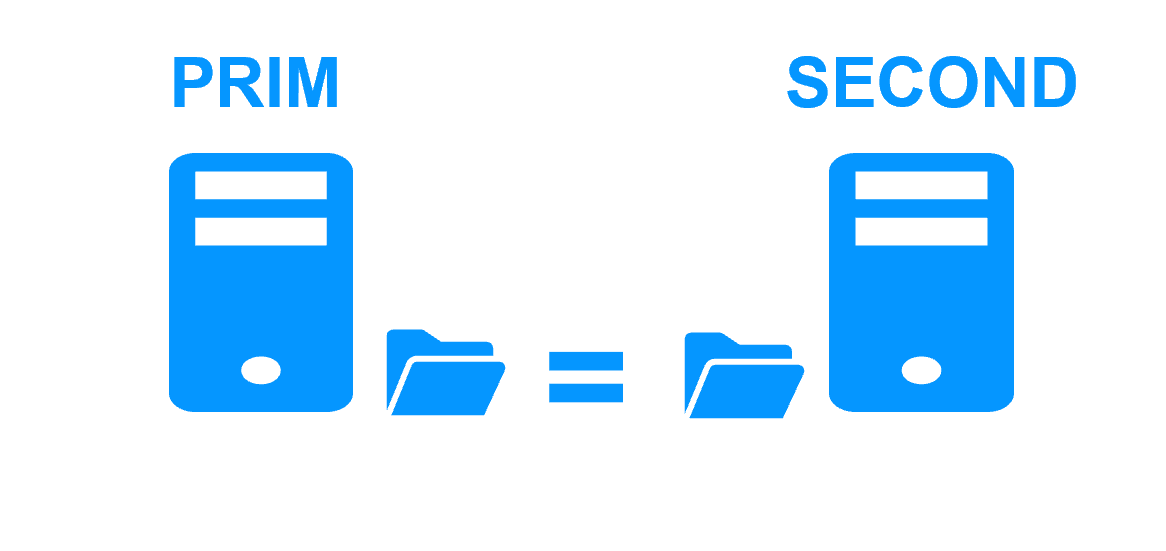 |
|
|
Fully automated failback More info >  |
|
|
Replication of any type of data More info > 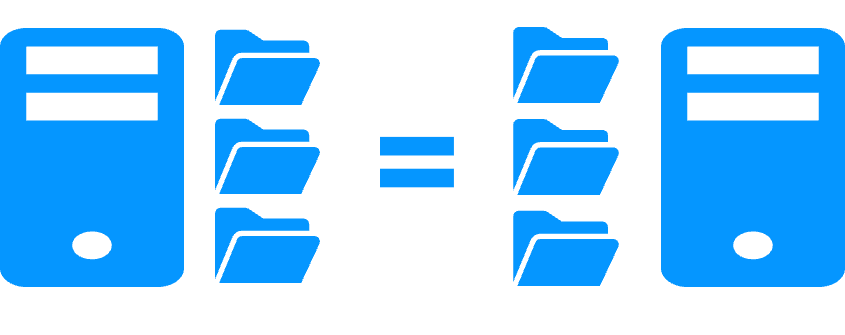 |
|
|
File replication vs disk replication More info >  |
|
|
File replication vs shared disk More info >  |
|
|
Remote sites and virtual IP address More info >  |
|
|
Quorum and split brain More info >  |
|
|
Active/active cluster More info > 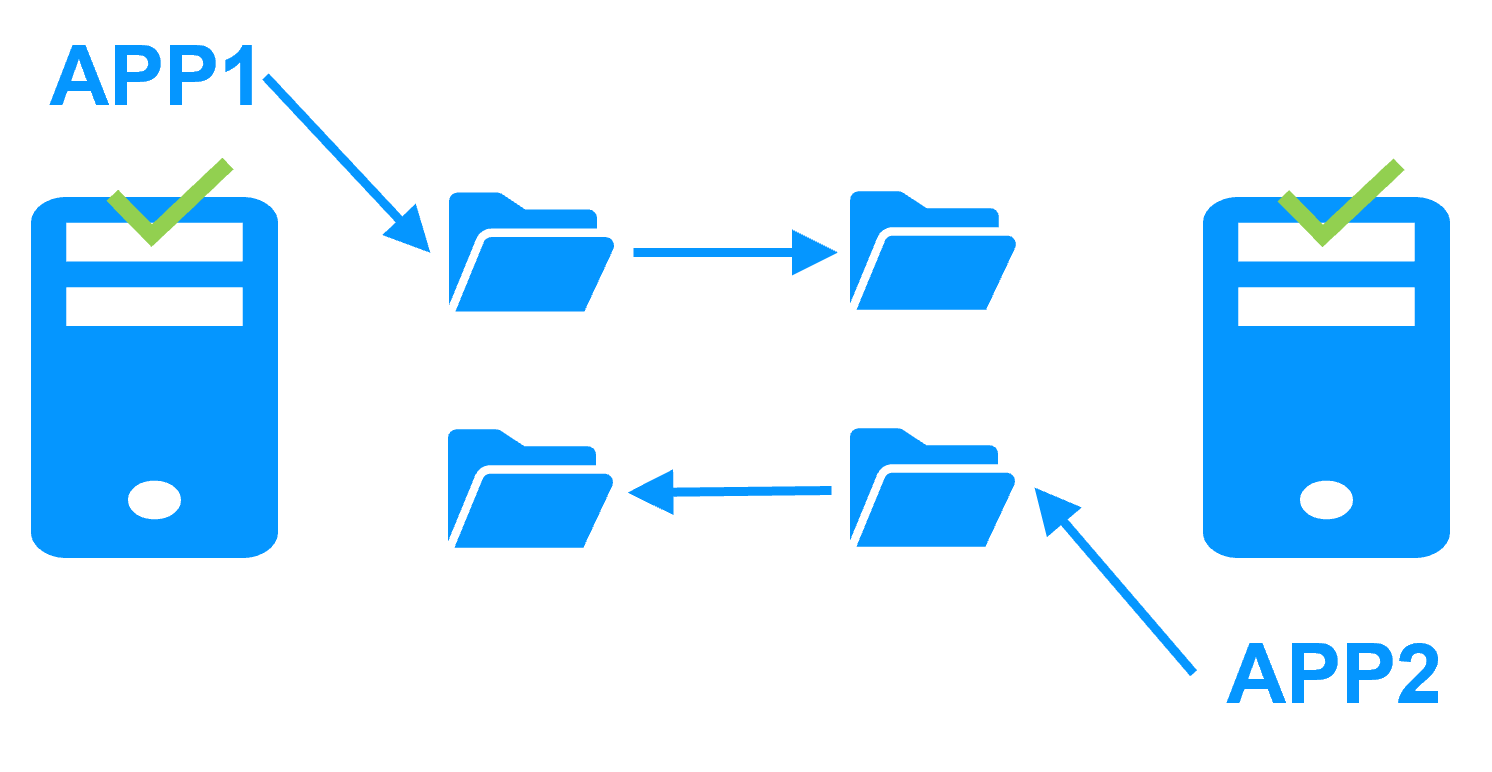 |
|
|
Uniform high availability solution More info > 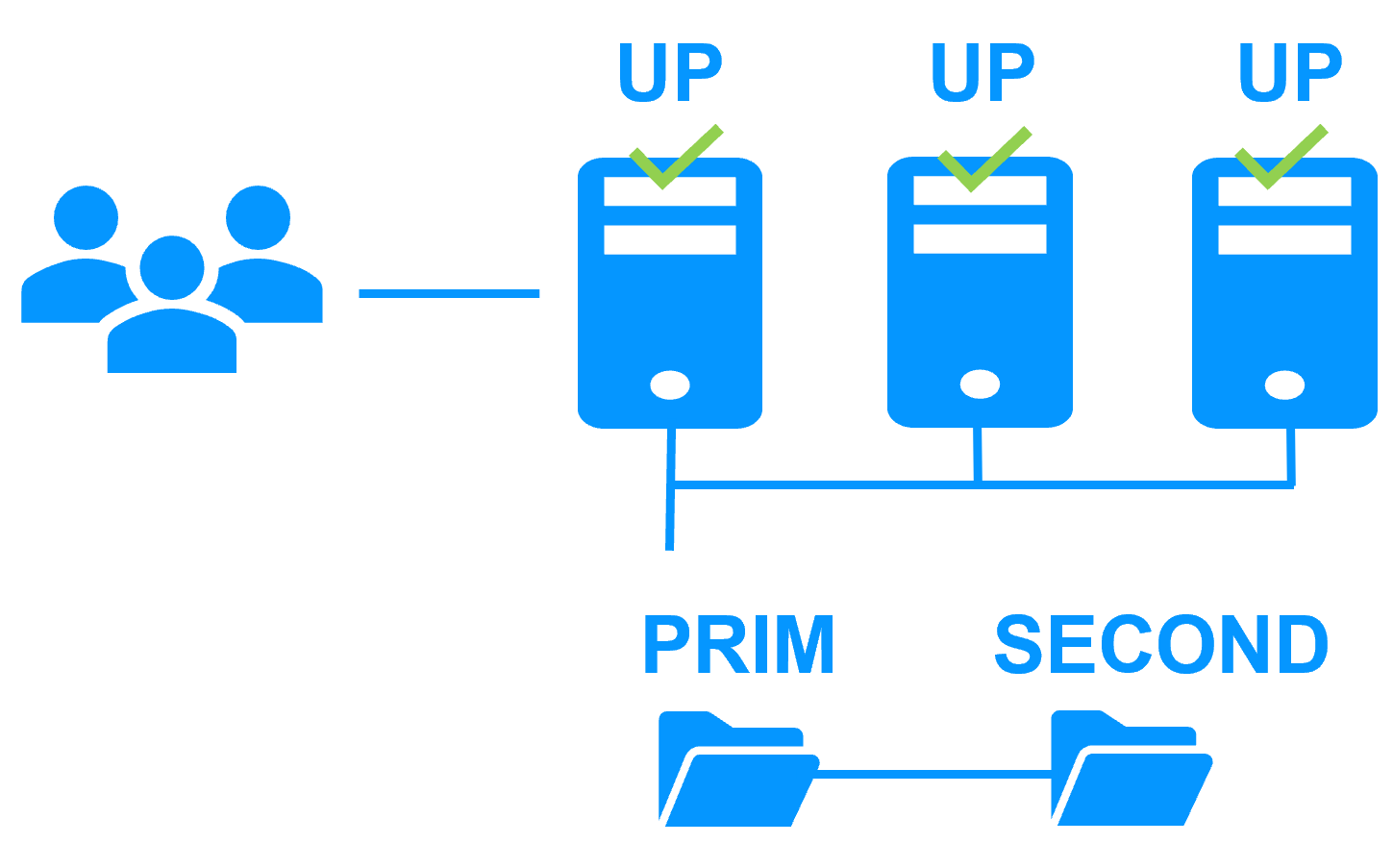 |
|
|
RTO / RPO More info > 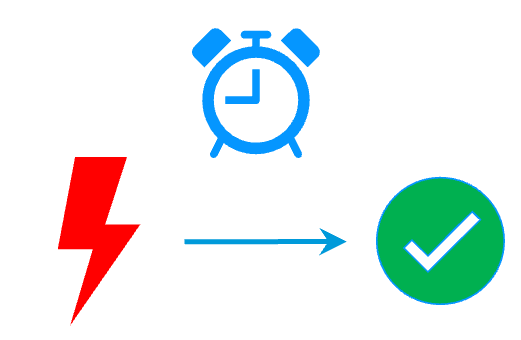 |
|
Evidian SafeKit farm cluster with load balancing and failover |
|
|
No load balancer or dedicated proxy servers or special multicast Ethernet address 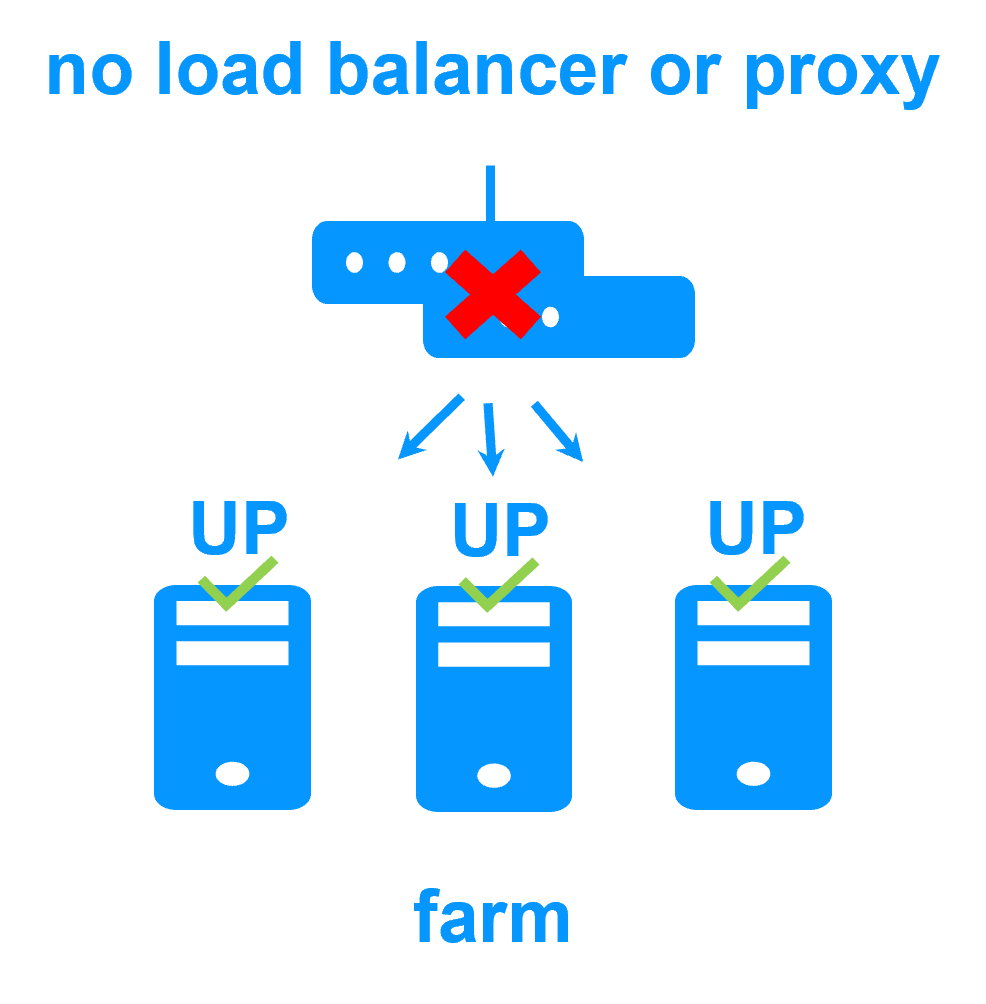
|
|
|
All clustering features
|
|
|
Remote sites and virtual IP address
|
|
|
Uniform high availability solution
|
|
Software clustering vs hardware clustering
|
|
|
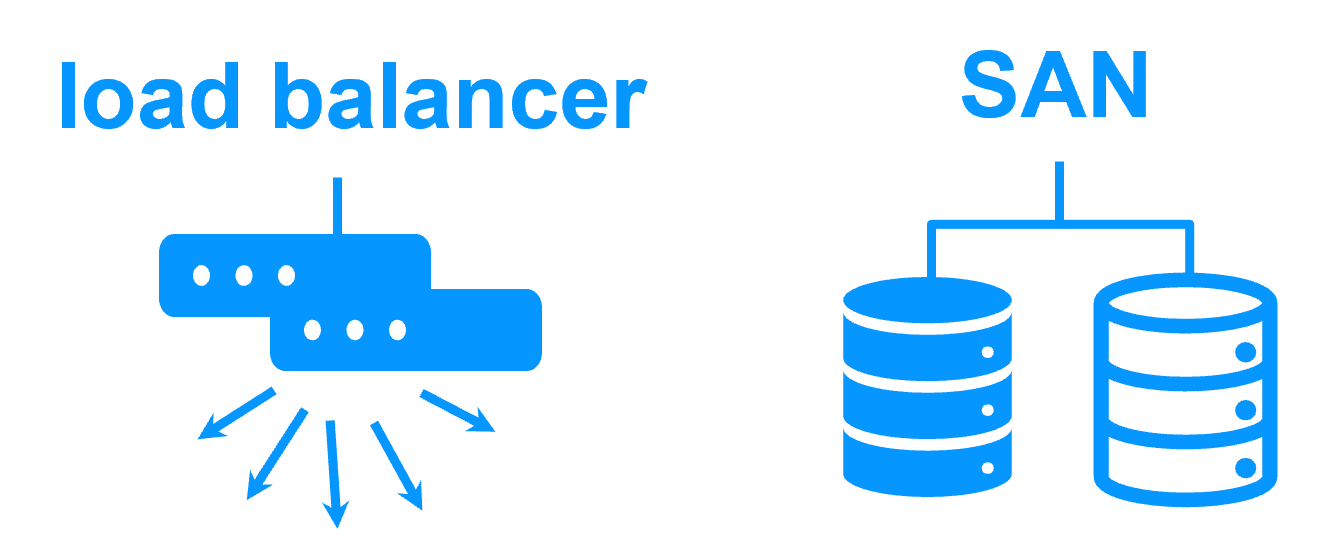
|
Shared nothing vs a shared disk cluster |
|
|
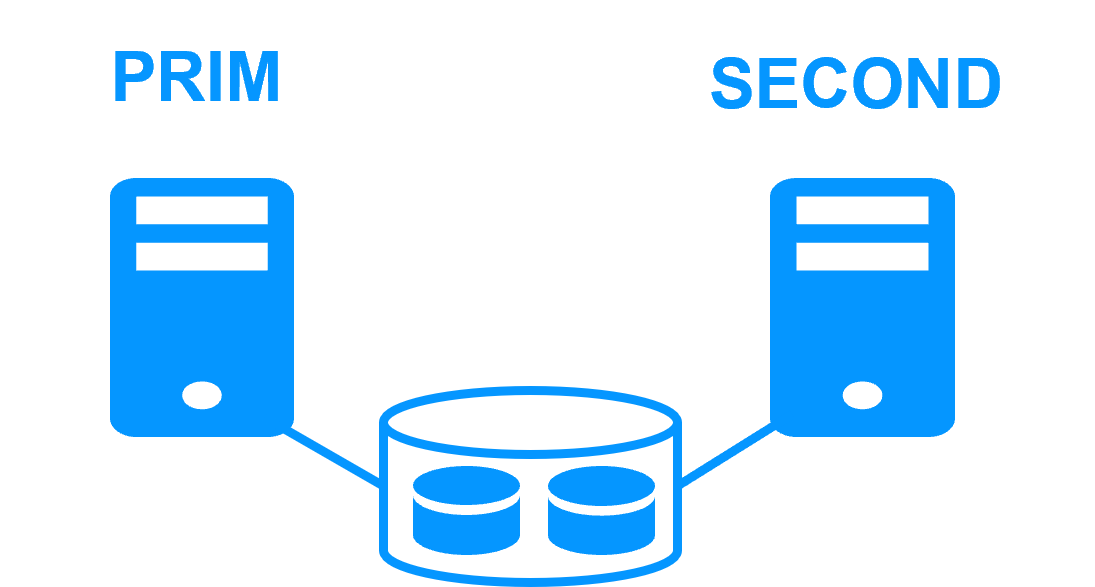
|
Application High Availability vs Full Virtual Machine High Availability
|
|
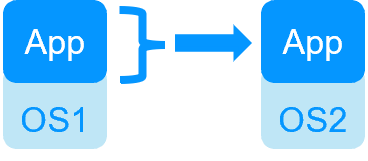
|
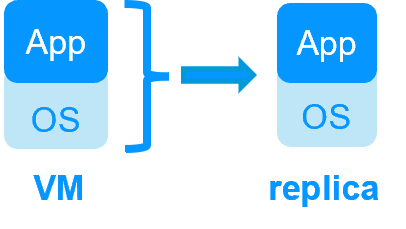
|
High availability vs fault tolerance
|
|
|
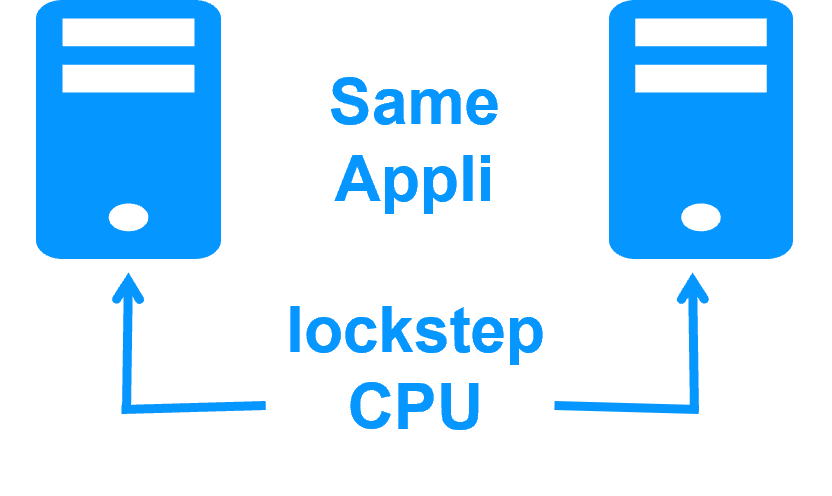
|
Synchronous replication vs asynchronous replication
|
|
|

|
Byte-level file replication vs block-level disk replication
|
|
|
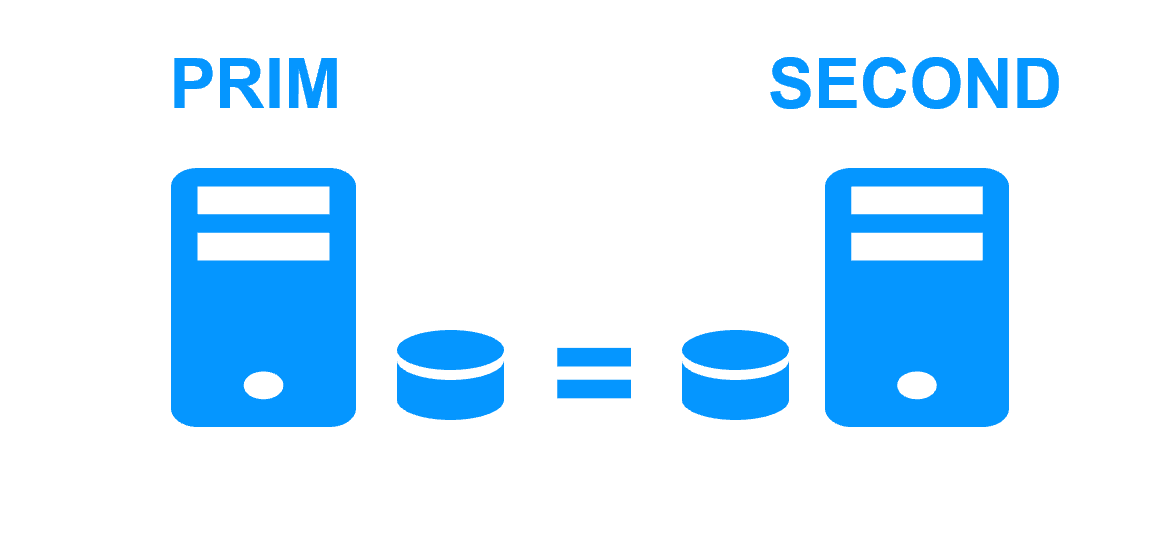
|
Heartbeat, failover and quorum to avoid 2 master nodes
|
|
|
|
Virtual IP address primary/secondary, network load balancing, failover
|
|

|
|
Evidian SafeKit 8.2
All new features compared to SafeKit 7.5 described in the release notes
Packages
- Windows (with Microsoft Visual C++ Redistributable)
- Windows (without Microsoft Visual C++ Redistributable)
- Linux
- Supported OS and last fixes
One-month license key
Technical documentation
Training
Product information
Introduction
-
- Demonstration
- Examples of redundancy and high availability solution
- Evidian SafeKit sold in many different countries with Milestone
- 2 solutions: virtual machine or application cluster
- Distinctive advantages
- More information on the web site
-
- Cluster of virtual machines
- Mirror cluster
- Farm cluster
Installation, Console, CLI
- Install and setup / pptx
- Package installation
- Nodes setup
- Upgrade
- Web console / pptx
- Configuration of the cluster
- Configuration of a new module
- Advanced usage
- Securing the web console
- Command line / pptx
- Configure the SafeKit cluster
- Configure a SafeKit module
- Control and monitor
Advanced configuration
- Mirror module / pptx
- start_prim / stop_prim scripts
- userconfig.xml
- Heartbeat (<hearbeat>)
- Virtual IP address (<vip>)
- Real-time file replication (<rfs>)
- How real-time file replication works?
- Mirror's states in action
- Farm module / pptx
- start_both / stop_both scripts
- userconfig.xml
- Farm heartbeats (<farm>)
- Virtual IP address (<vip>)
- Farm's states in action
Troubleshooting
- Troubleshooting / pptx
- Analyze yourself the logs
- Take snapshots for support
- Boot / shutdown
- Web console / Command lines
- Mirror / Farm / Checkers
- Running an application without SafeKit
Support
- Evidian support / pptx
- Get permanent license key
- Register on support.evidian.com
- Call desk