Overview
This article explores the pros and cons of data replication techniques at database level, disk level and file level for high availability clusters. We are looking at failover, failback, simplicity of implementation.
The following comparative tables explain in detail the data replication techniques implemented by SafeKit, a high availability software product.
Evidian SafeKit mirror cluster with real-time file replication and failover |
|
|
3 products in 1 More info >  |
|
|
Very simple configuration More info >  |
|
|
Synchronous replication More info > 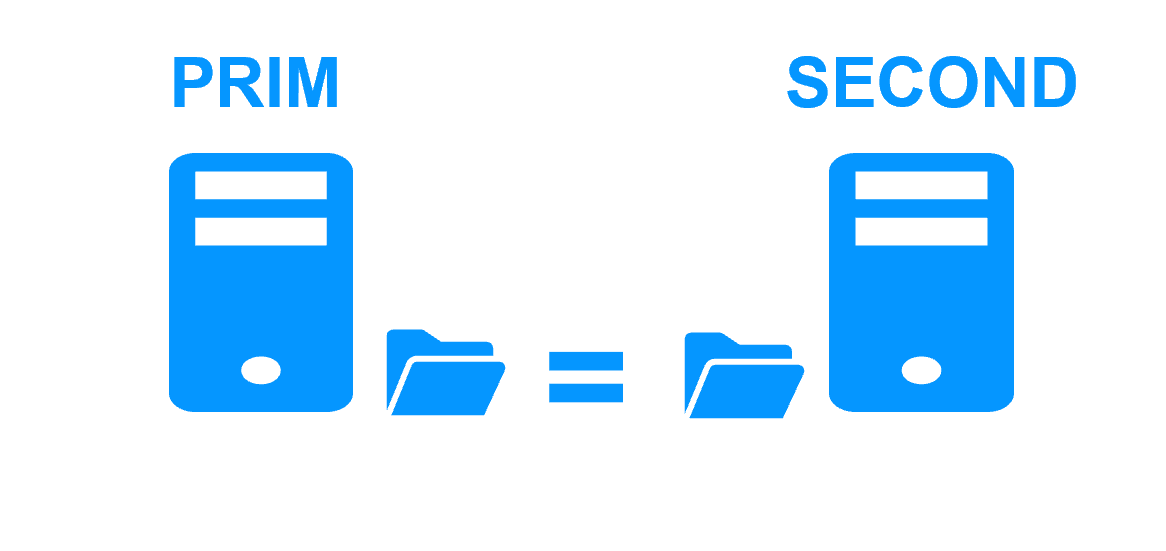 |
|
|
Fully automated failback More info >  |
|
|
Replication of any type of data More info >  |
|
|
File replication vs disk replication More info >  |
|
|
File replication vs shared disk More info >  |
|
|
Remote sites and virtual IP address More info >  |
|
|
Quorum and split brain More info >  |
|
|
Active/active cluster More info >  |
|
|
Uniform high availability solution More info > 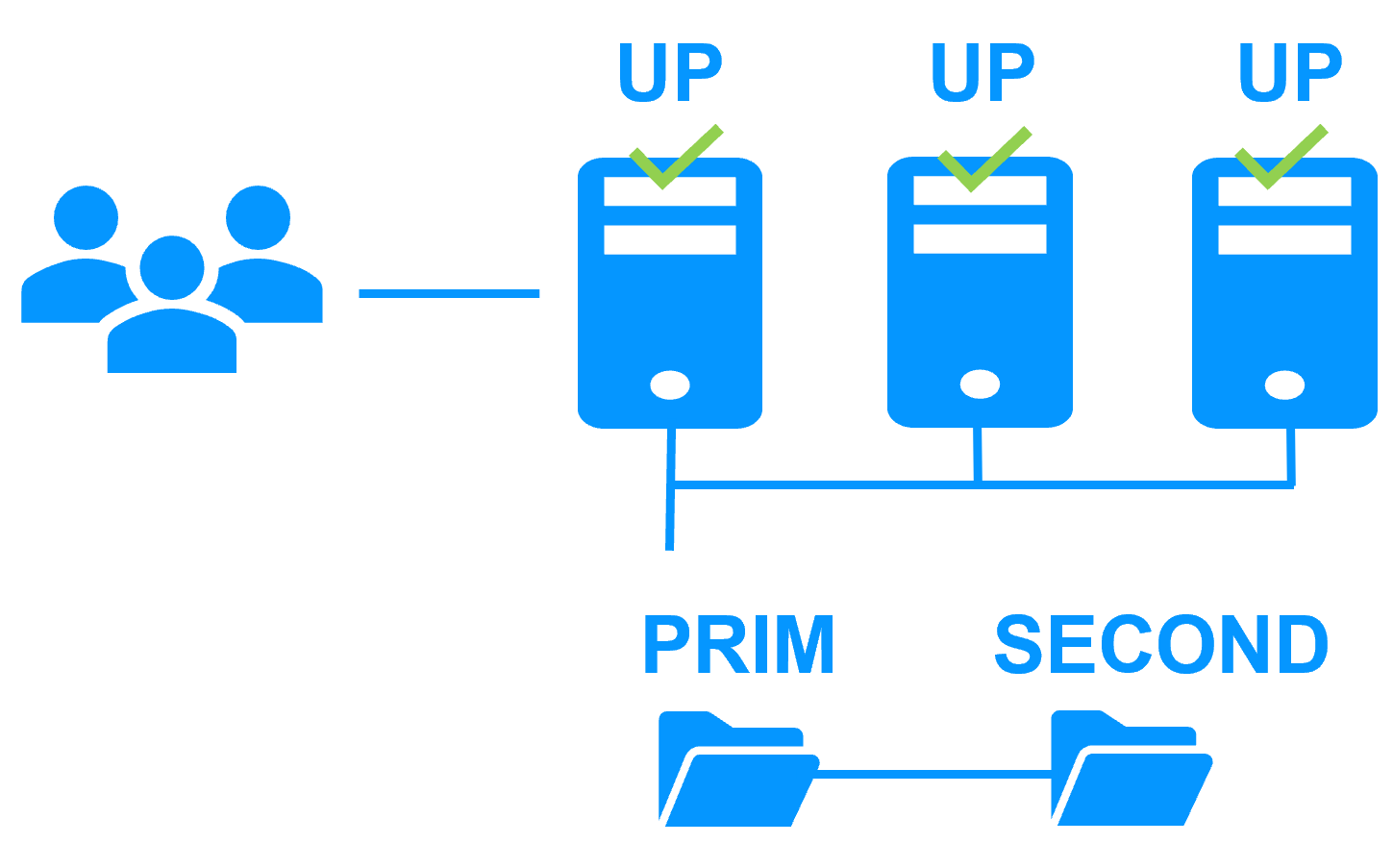 |
|
|
RTO / RPO More info > 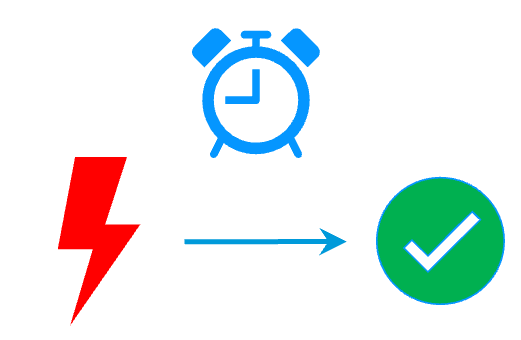 |
|
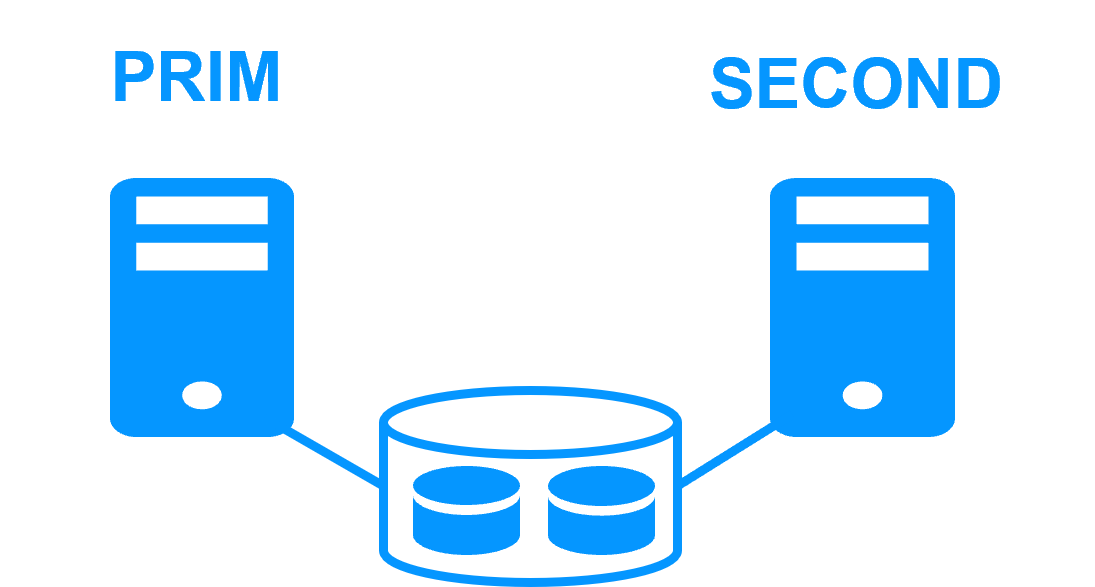
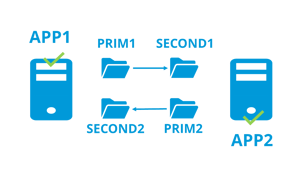

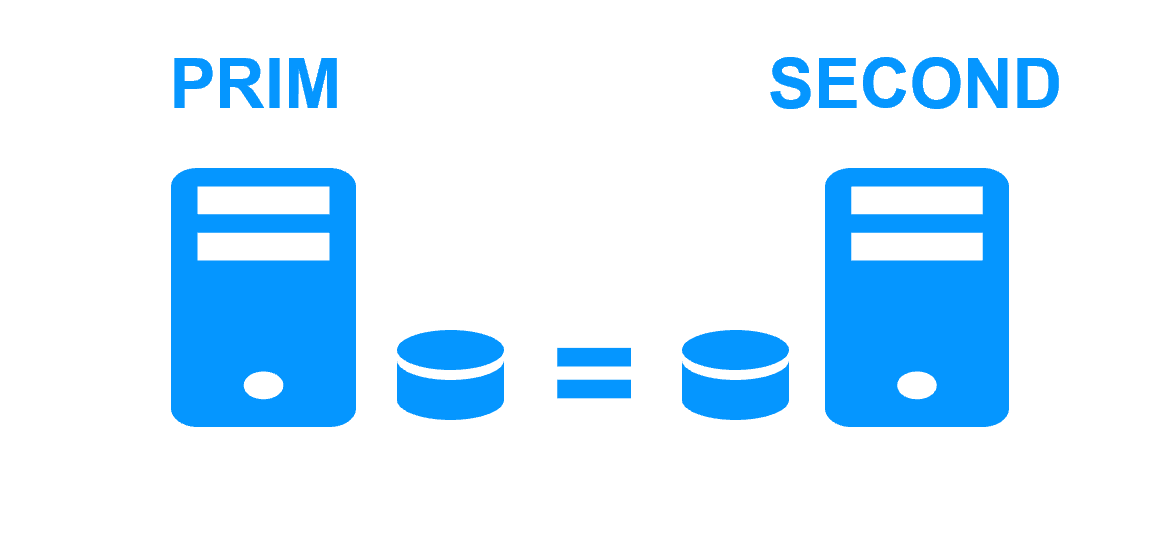

Step 1. Real-time replication
Server 1 (PRIM) runs the application. Clients are connected to a virtual IP address. SafeKit replicates in real time modifications made inside files through the network.
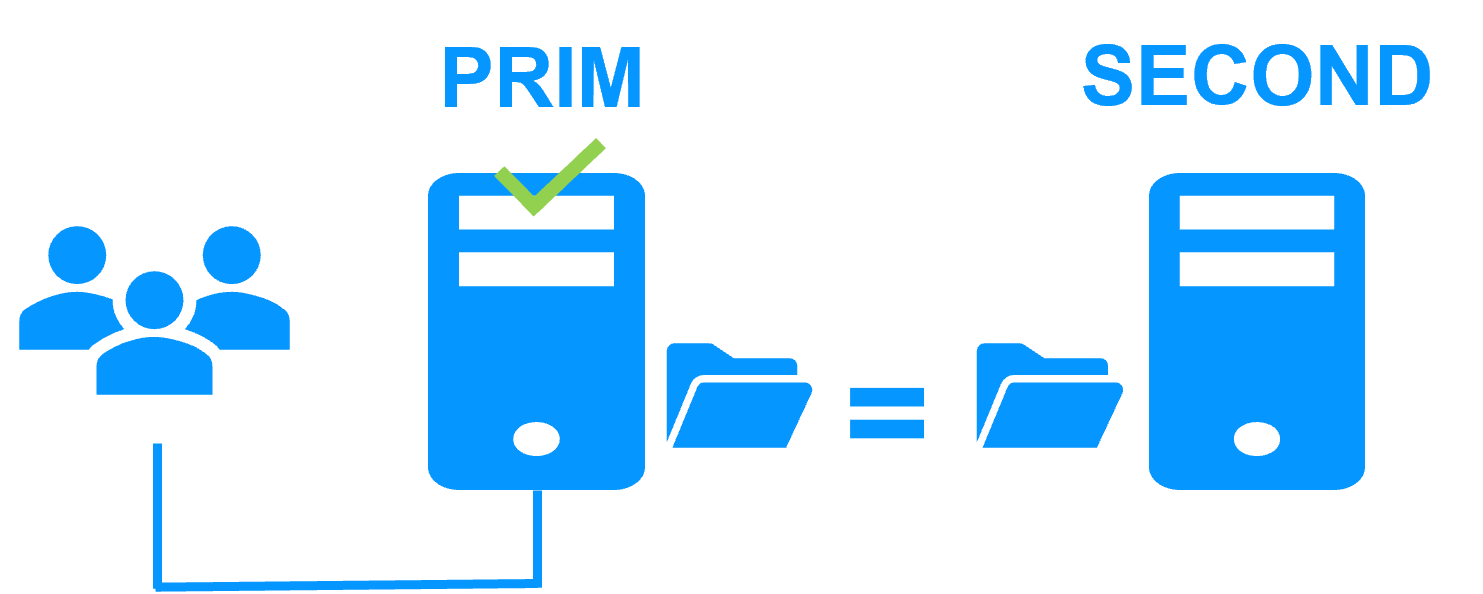
The replication is synchronous with no data loss on failure contrary to asynchronous replication.
You just have to configure the names of directories to replicate in SafeKit. There are no pre-requisites on disk organization. Directories may be located in the system disk.
Step 2. Automatic failover
When Server 1 fails, Server 2 takes over. SafeKit switches the virtual IP address and restarts the application automatically on Server 2.
The application finds the files replicated by SafeKit uptodate on Server 2. The application continues to run on Server 2 by locally modifying its files that are no longer replicated to Server 1.
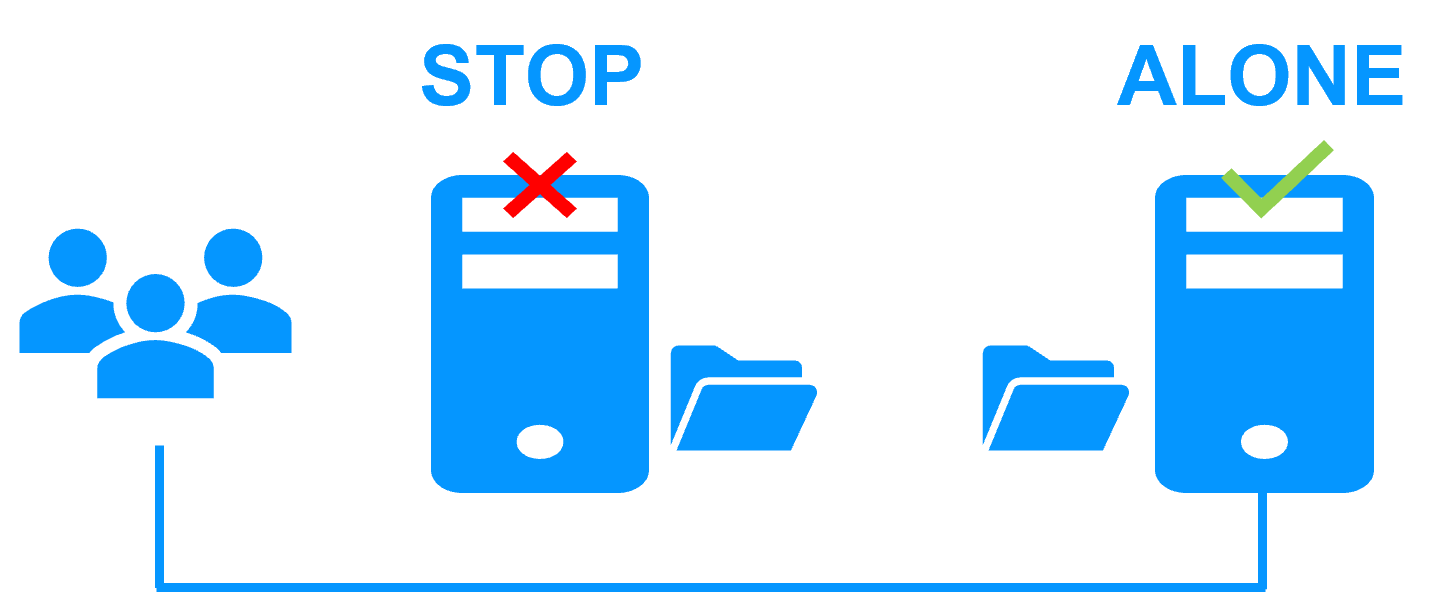
The failover time is equal to the fault-detection time (30 seconds by default) plus the application start-up time.
Step 3. Automatic failback
Failback involves restarting Server 1 after fixing the problem that caused it to fail.
SafeKit automatically resynchronizes the files, updating only the files modified on Server 2 while Server 1 was halted.
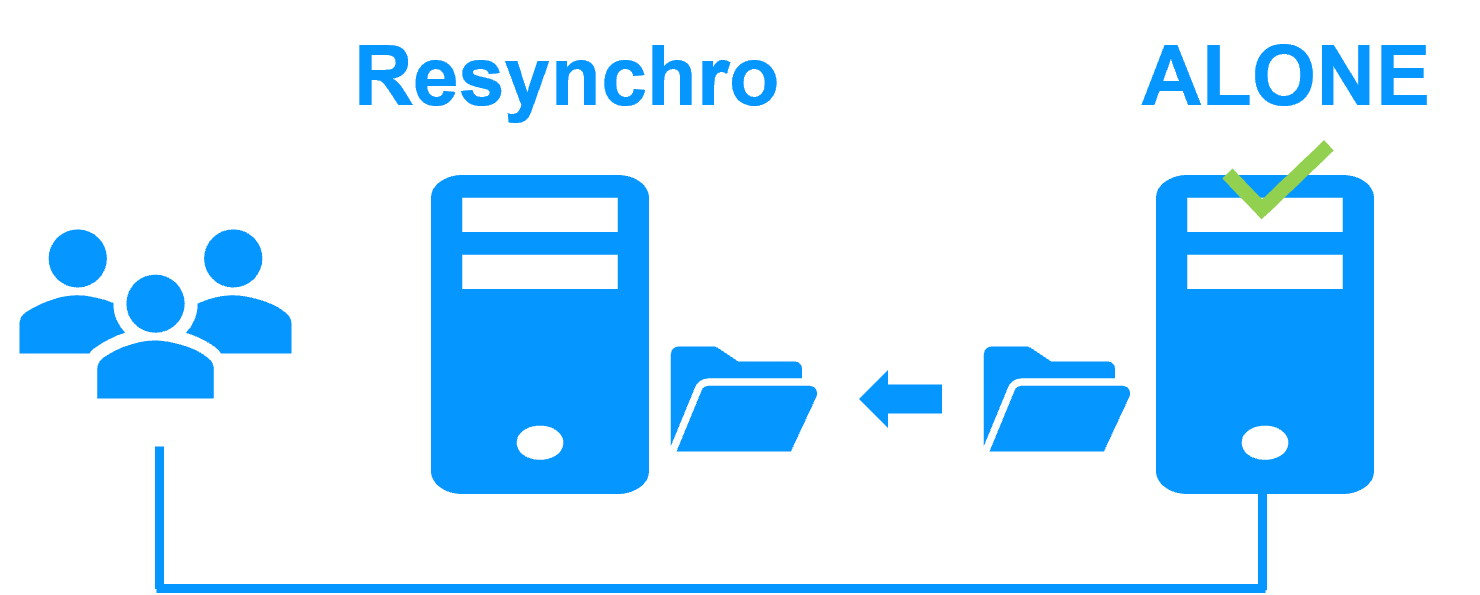
Failback takes place without disturbing the application, which can continue running on Server 2.
Step 4. Back to normal
After reintegration, the files are once again in mirror mode, as in step 1. The system is back in high-availability mode, with the application running on Server 2 and SafeKit replicating file updates to Server 1.
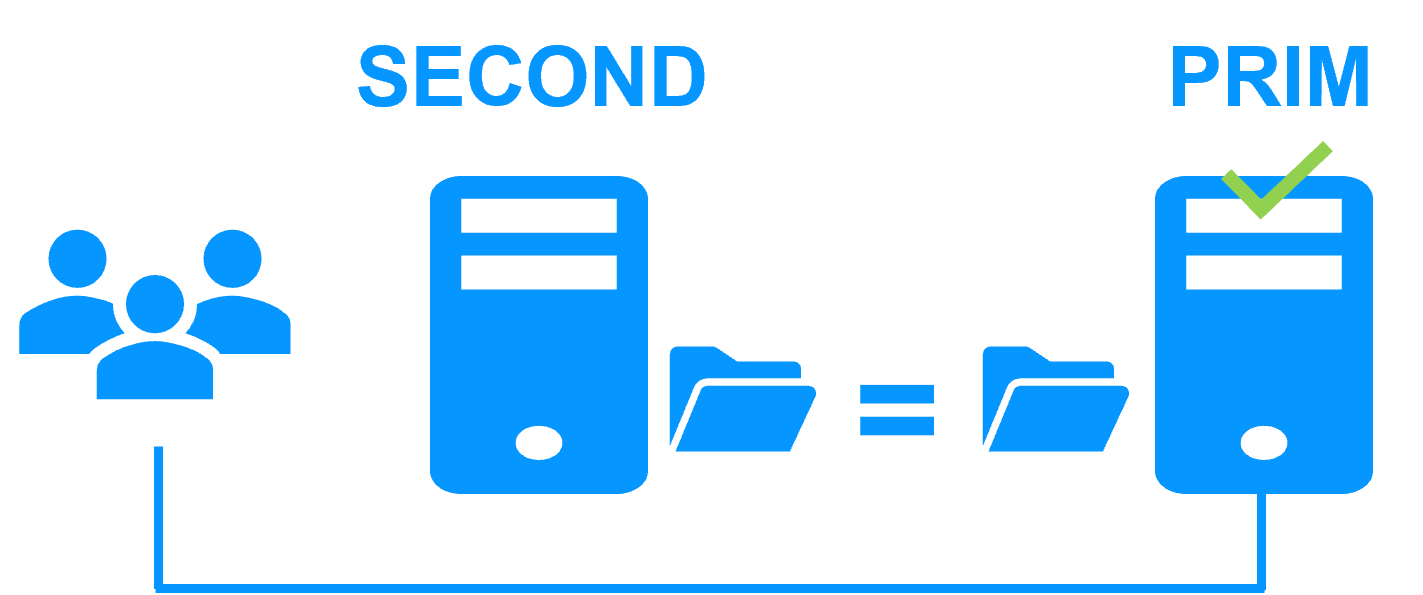
If the administrator wishes the application to run on Server 1, he/she can execute a "swap" command either manually at an appropriate time, or automatically through configuration.