| Key Features |
Why Choose SafeKit for Simple and Cost-Effective High Availability? |
See Why Choose SafeKit for High Availability
|
| Deployment Model |
All-in-One SANless HA: Shared-Nothing Software Clustering |
See SafeKit All-in-One SANless HA
|
| Partners |
SafeKit: The Benchmark in High Availability for Partners |
See Why SafeKit Is the HA Benchmark for Partners |
| HA Strategies |
SafeKit: Infrastructure (VM) vs. Application-Level High Availability |
See SafeKit HA & Redundancy: VM vs. Application Level
|
| Technical Specifications |
Technical Limitations for SafeKit Clustering |
See SafeKit High Availability Limitations |
| Proof of Concept |
SafeKit: High Availability Configuration & Failover Demos |
See SafeKit Failover Tutorials |
| Architecture |
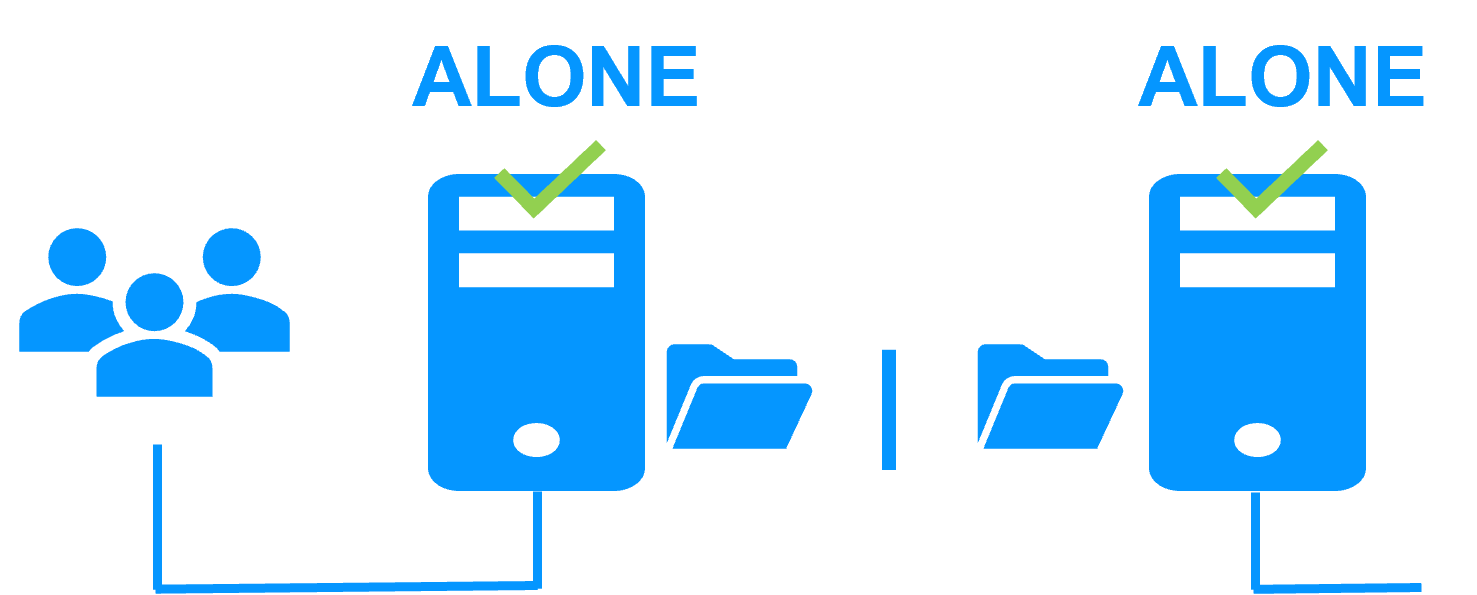
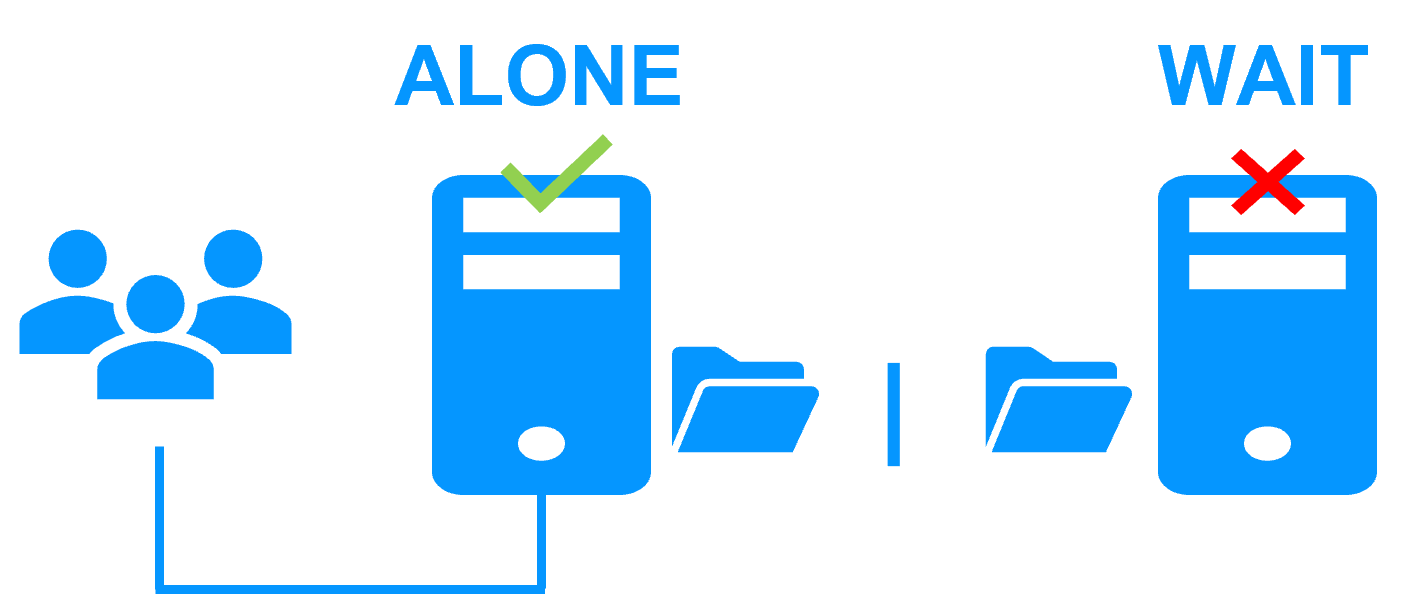
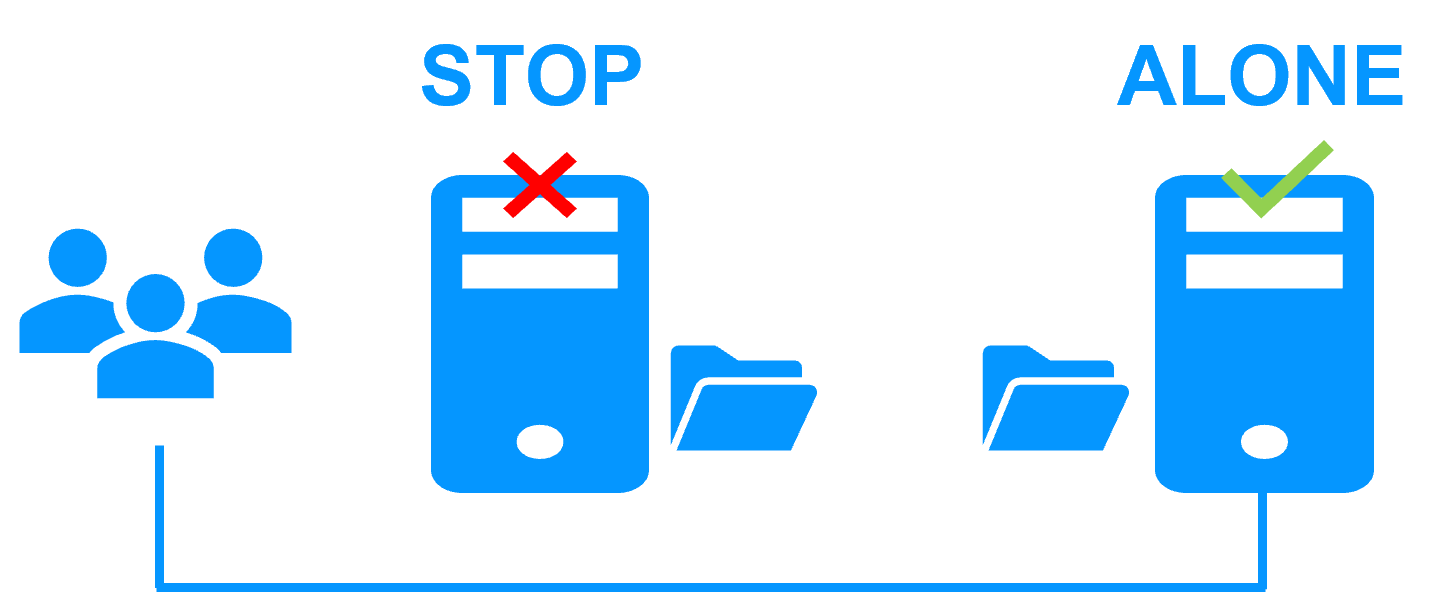
How the SafeKit Mirror Cluster works (Real-Time Replication & Failover) |
See SafeKit Mirror Cluster: Real-Time Replication & Failover |
| Architecture |
How the SafeKit Farm Cluster works (Network Load Balancing & Failover) |
See SafeKit Farm Cluster: Network Load Balancing & Failover |
| Competitive Advantages |
Comparison: SafeKit vs. Traditional High Availability (HA) Clusters |
See SafeKit vs. Traditional HA Cluster Comparison |
| Technical Resources |
SafeKit High Availability: Documentation, Downloads & Trial |
See SafeKit HA Free Trial & Technical Documentation |
| Pre-configured Solutions |
SafeKit Application Module Library: Ready-to-Use HA Solutions |
See SafeKit High Availability Application Modules |