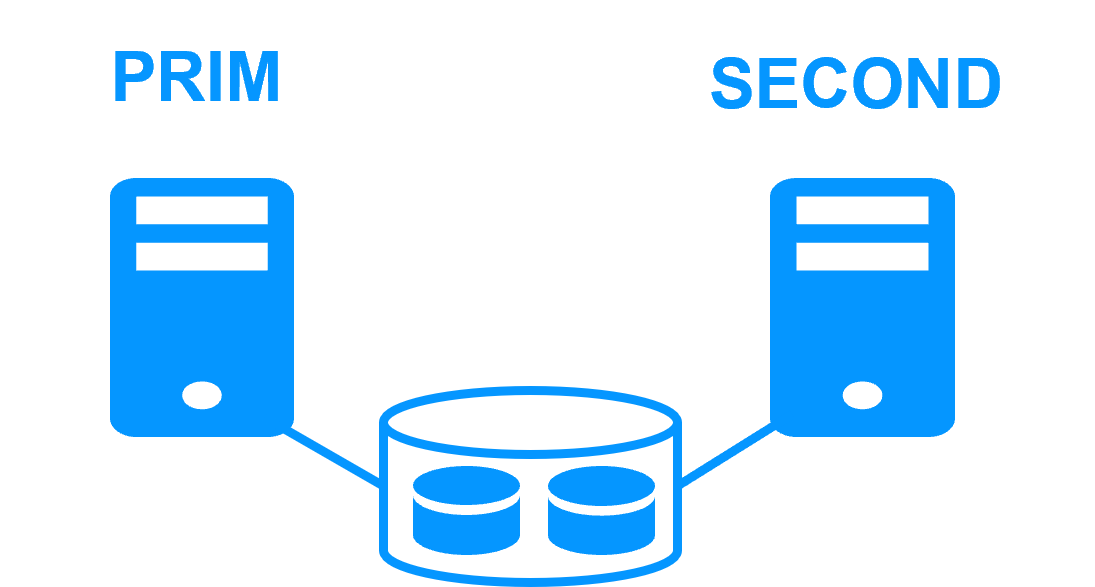
Step 1. File replication at byte level in a mirror cluster
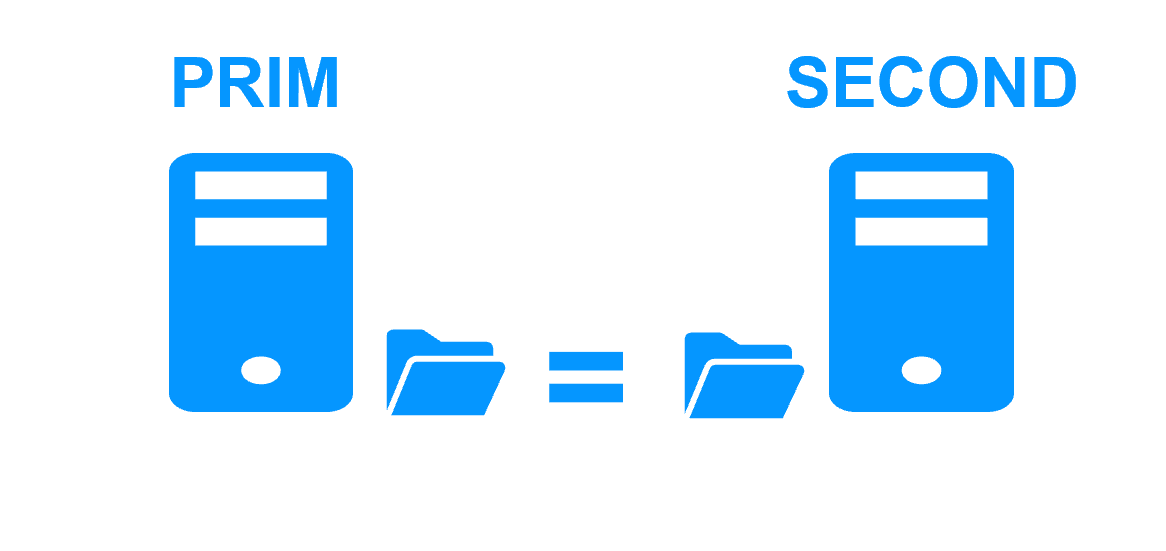
This step corresponds to the following figure. Server 1 (PRIM) runs the Kubernetes K3S components explained in the previous table. Clients are connected to the virtual IP address of the mirror cluster. SafeKit replicates in real time files opened by the Kubernetes K3S components. Only changes made by the components in the files are replicated across the network, thus limiting traffic (byte-level file replication).
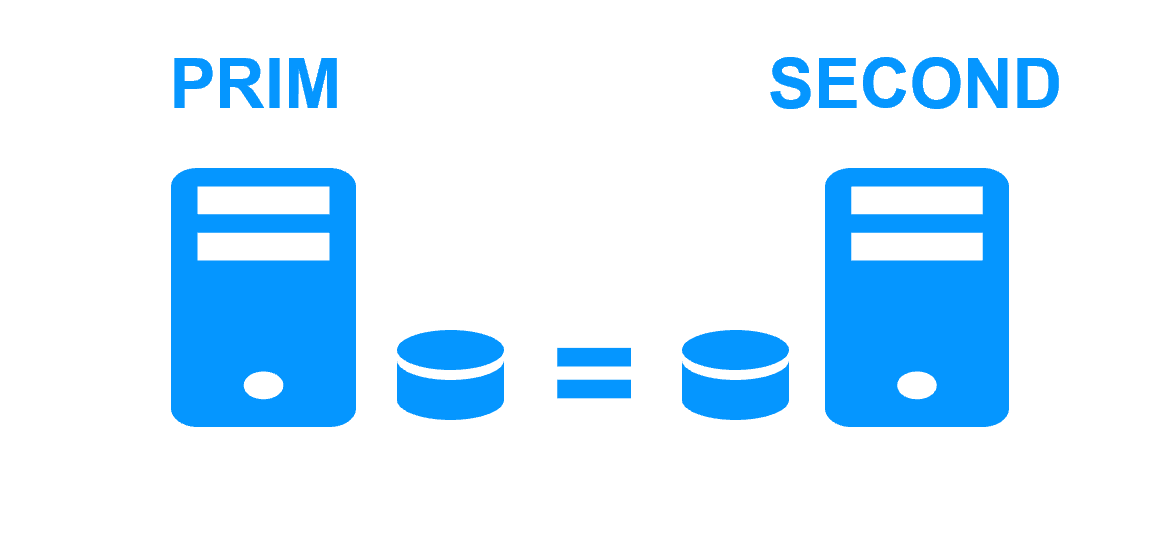
With a software data replication at the file level, only names of directories are configured in SafeKit. There are no pre-requisites on disk organization for the two servers. Directories to replicate may be located in the system disk. SafeKit implements synchronous replication with no data loss on failure contrary to asynchronous replication.
Step 2. Failover
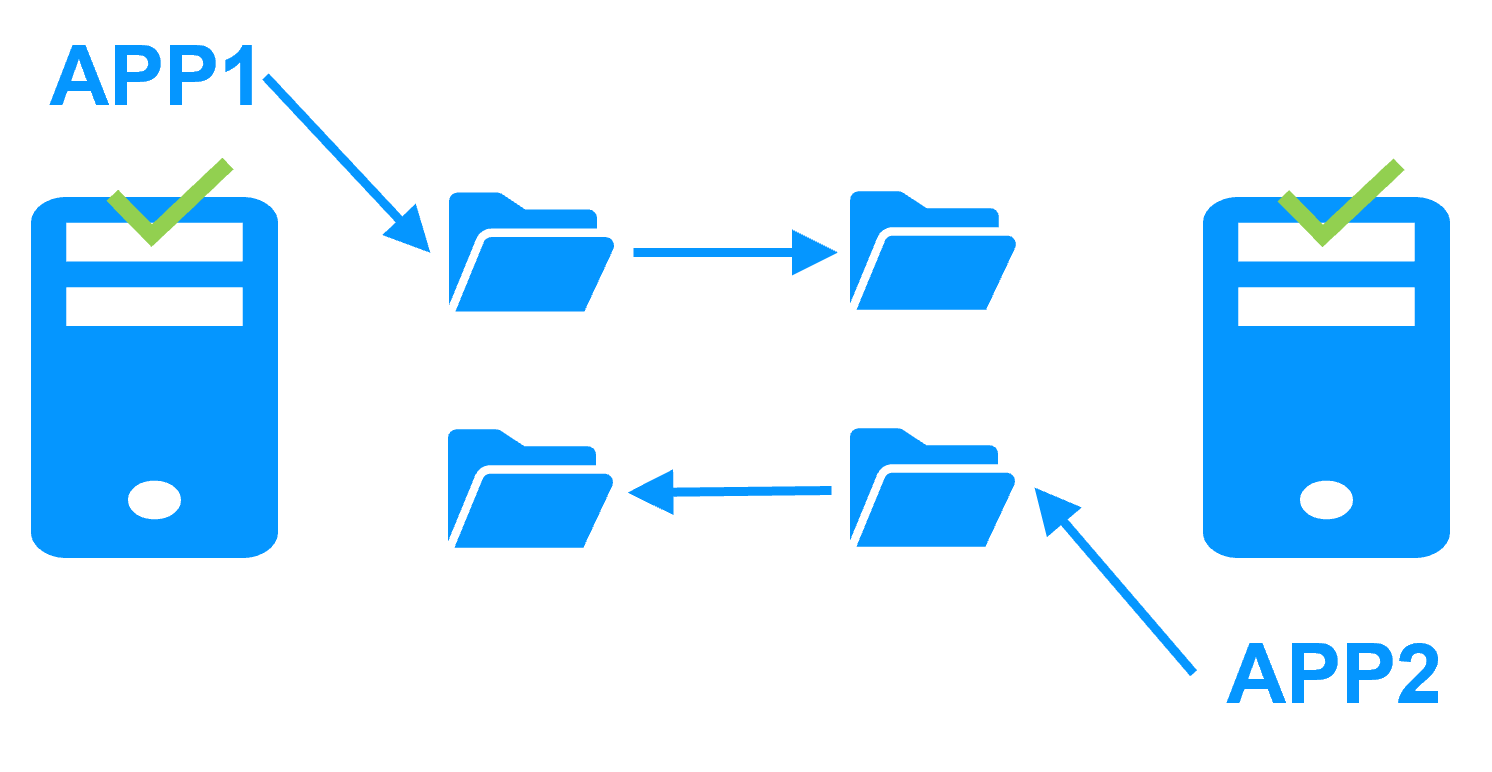
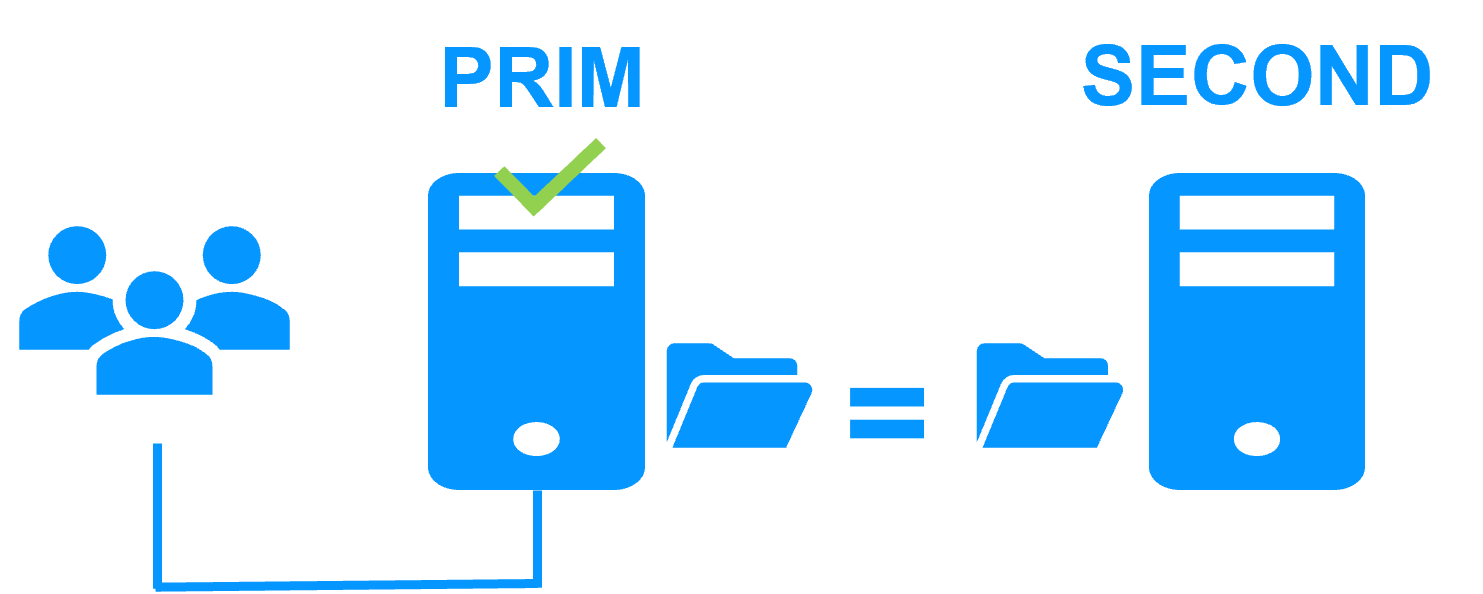
When Server 1 fails, Server 2 takes over. SafeKit switches the cluster's virtual IP address and restarts the Kubernetes K3S components automatically on Server 2. The components find the files replicated by SafeKit uptodate on Server 2, thanks to the synchronous replication between Server 1 and Server 2. The components continue to run on Server 2 by locally modifying their files that are no longer replicated to Server 1.
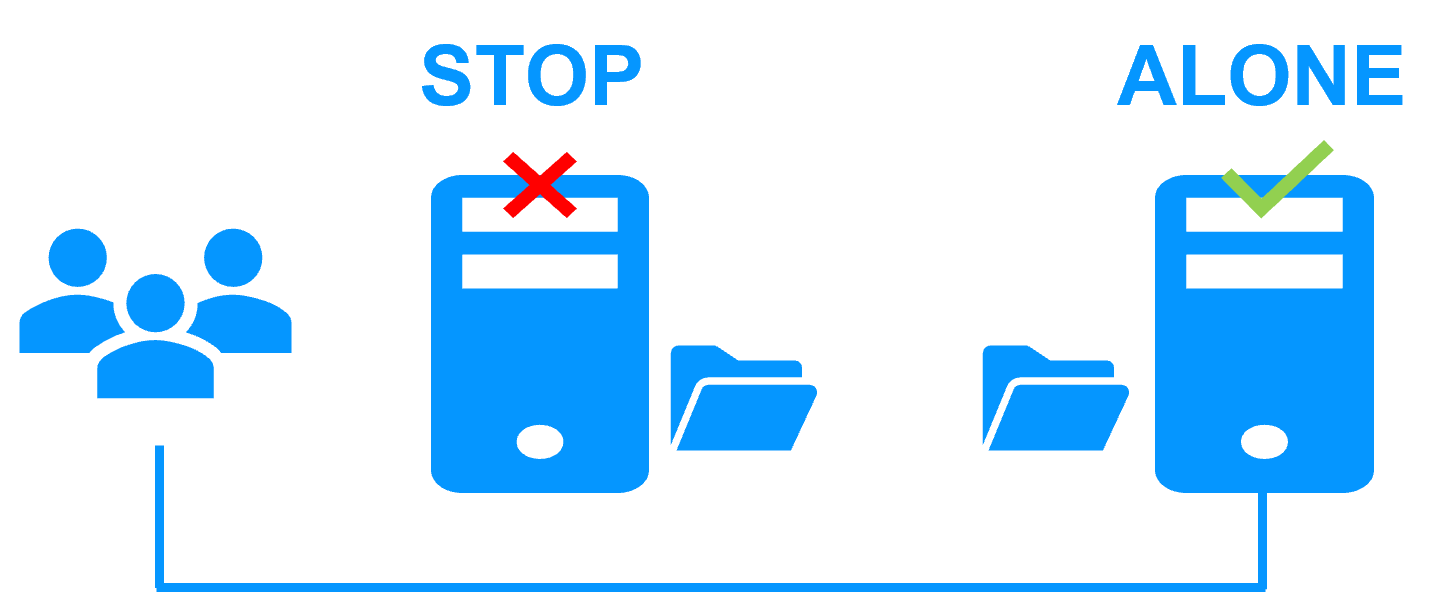
The failover time is equal to the fault-detection time (set to 30 seconds by default) plus the components start-up time. Unlike disk replication solutions, there is no delay for remounting file system and running file system recovery procedures.
Step 3. Failback and reintegration
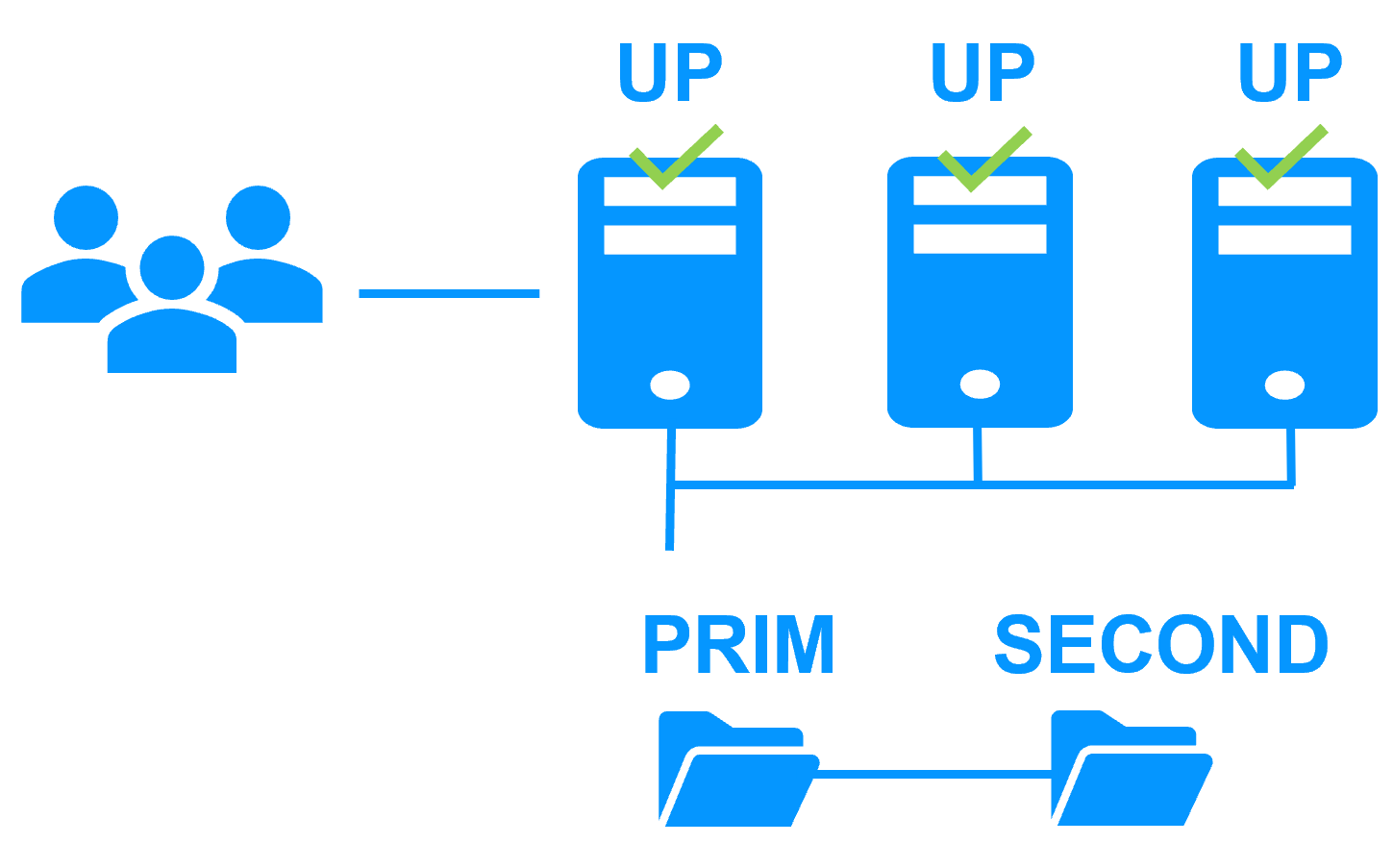
Failback involves restarting Server 1 after fixing the problem that caused it to fail. SafeKit automatically resynchronizes the files, updating only the files modified on Server 2 while Server 1 was halted. This reintegration takes place without disturbing the Kubernetes K3S components, which can continue running on Server 2.
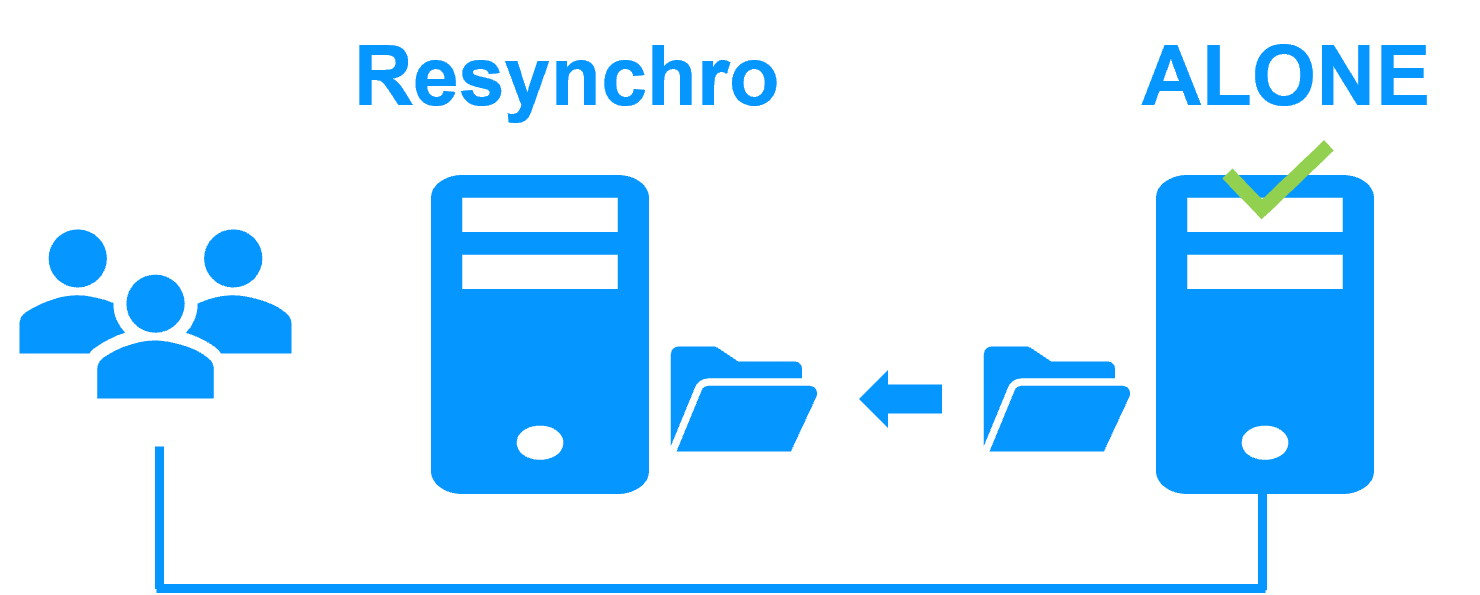
If SafeKit was cleanly stopped on server 1, then at its restart, only the modified zones inside files are resynchronized, according to modification tracking bitmaps.
If server 1 crashed (power off), the modification bitmaps are not reliable and not used. All the files bearing a modification timestamp more recent than the last known synchronization point are resynchronized.
Step 4. Return to byte-level file replication in the mirror cluster
After reintegration, the files are once again in mirror mode, as in step 1. The system is back in high-availability mode, with the Kubernetes K3S components running on Server 2 and SafeKit replicating file updates to the secondary Server 1.
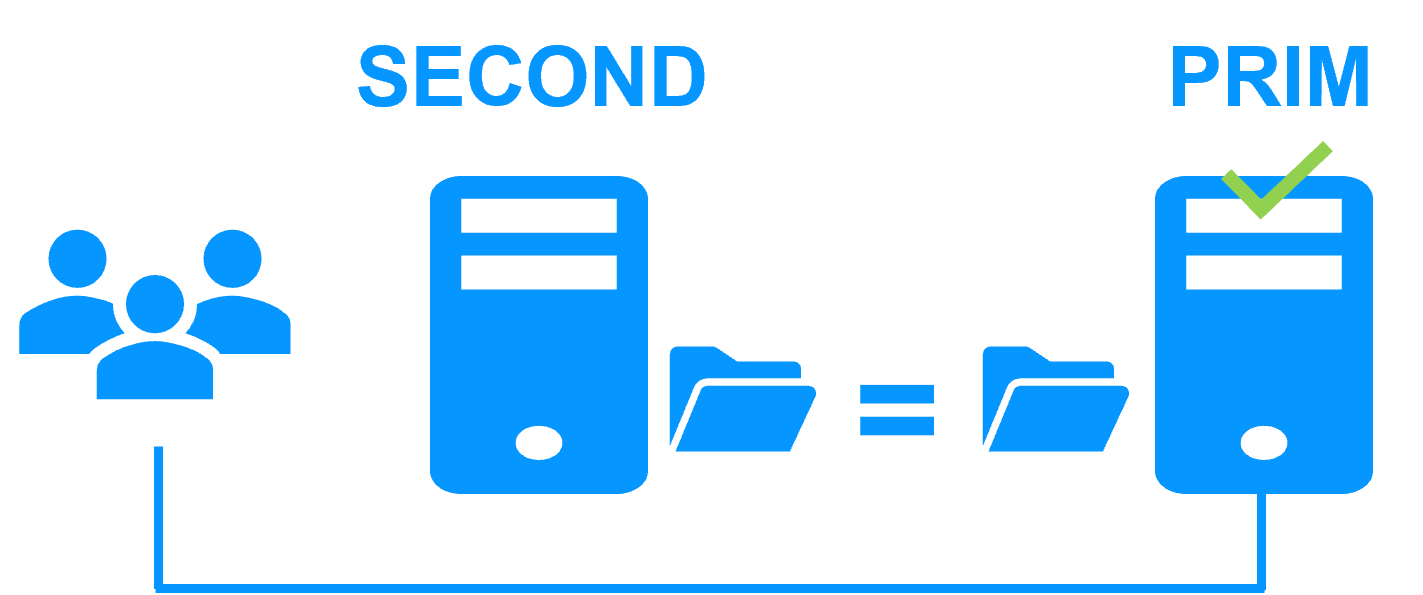
If the administrator wishes the Kubernetes K3S components to run on Server 1, he/she can execute a "swap" command either manually at an appropriate time, or automatically through configuration.
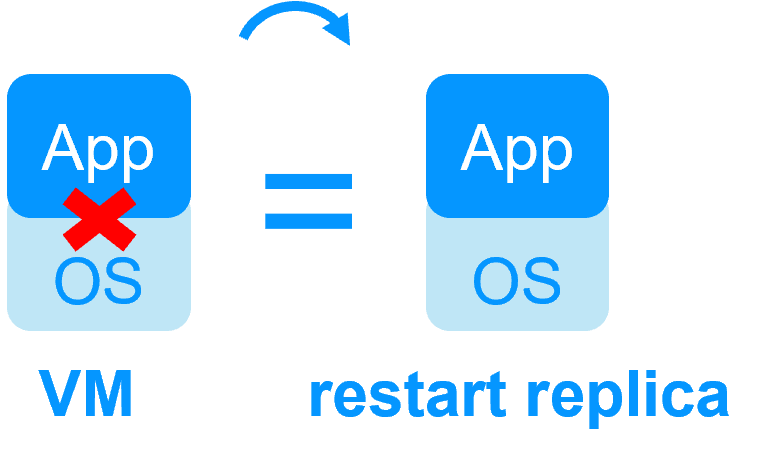
 No shared disk -
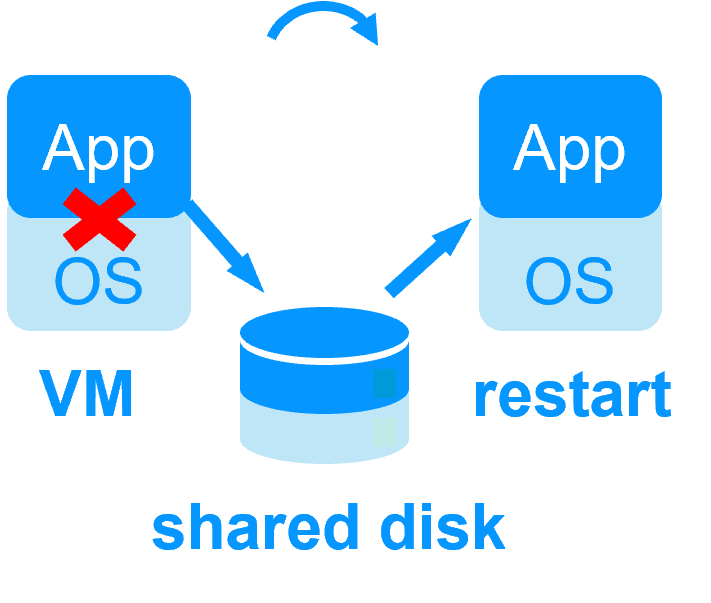
No shared disk -  Shared disk and specific extenal bay of disk
Shared disk and specific extenal bay of disk