What is the SafeKit Mirror HA solution for Windows?
SafeKit brings high availability to Windows between two servers of any brand.
This article explains how to implement quickly a Windows cluster without shared storage on a SAN and without specific skills.
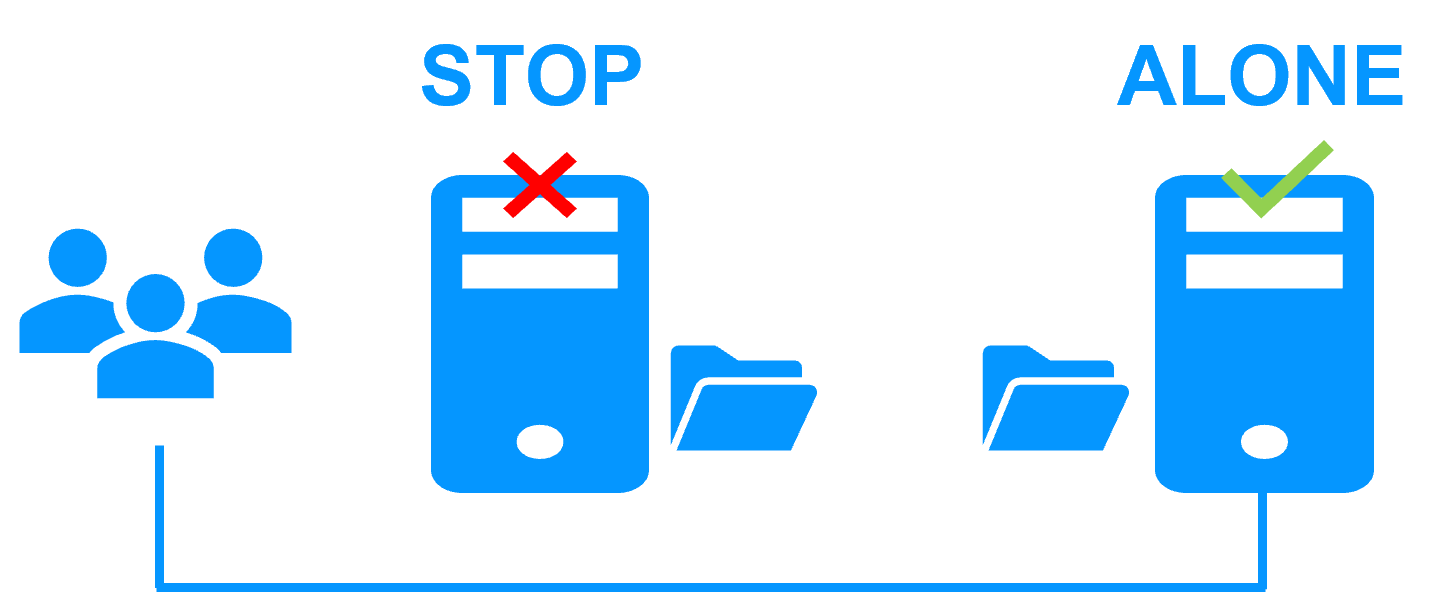
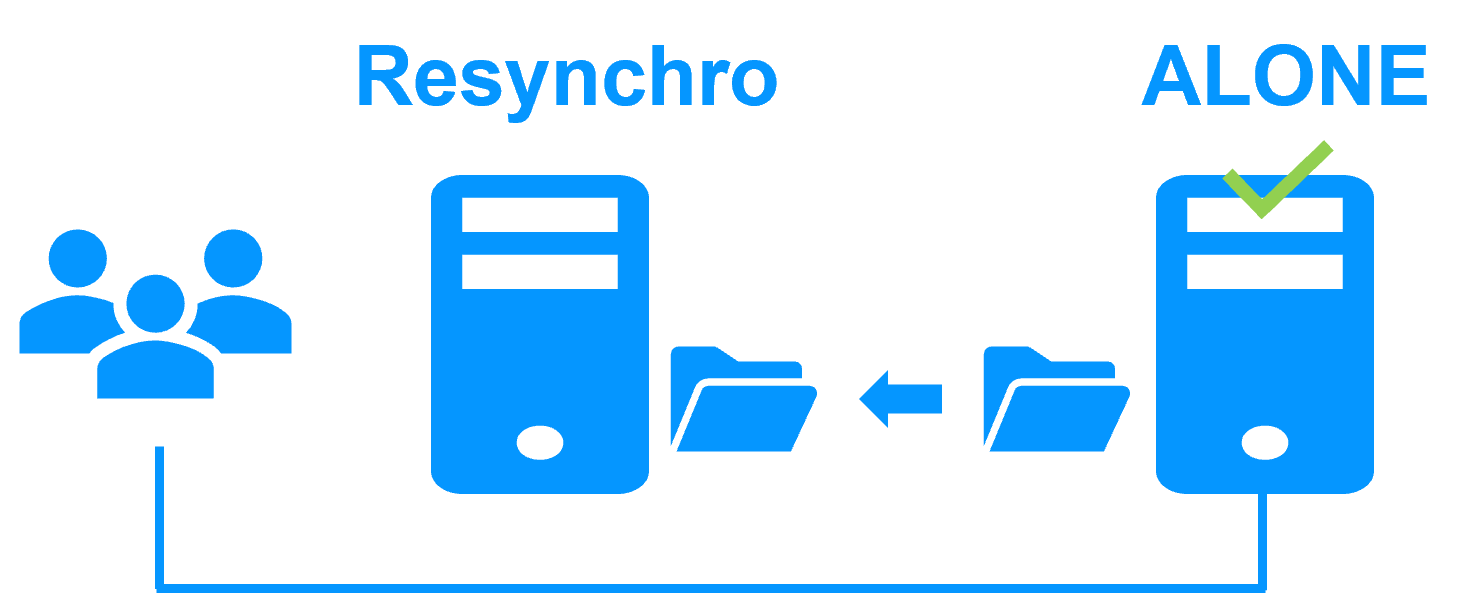
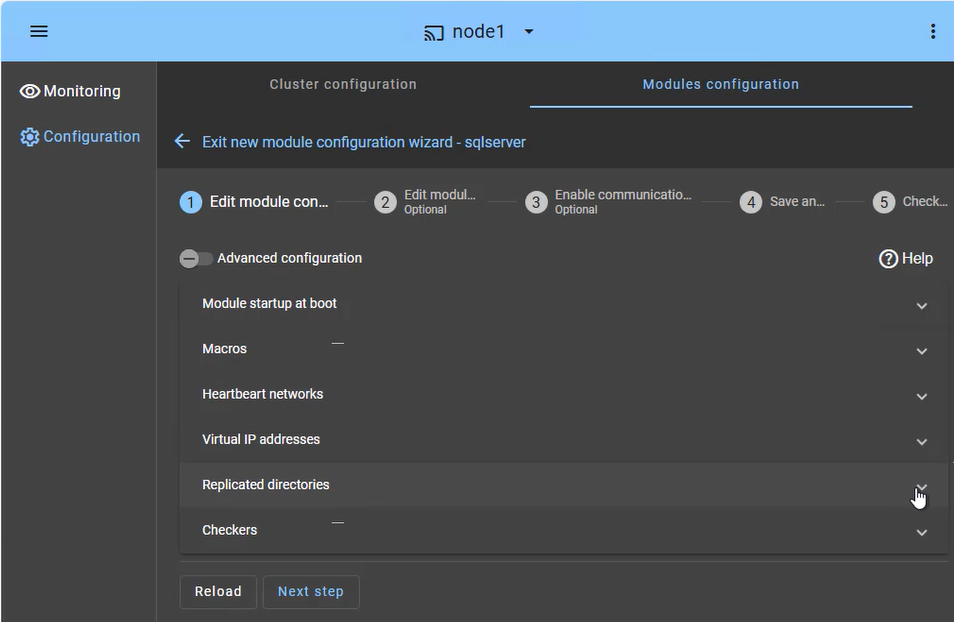
The principle of the solution is to define the folders where the Windows data resides, its services, a virtual IP, and checkers.
SafeKit then implements real-time replication and automatic failover to ensure continuous service availability.