| Architecture |
Shared-Nothing: Uses local disks for maximum speed and minimum cost. |
Shared Storage: Dependent on cloud-managed disks. |
Block-Level: Replicates entire VM disks to a passive region. |
| Data Integrity (RPO) |
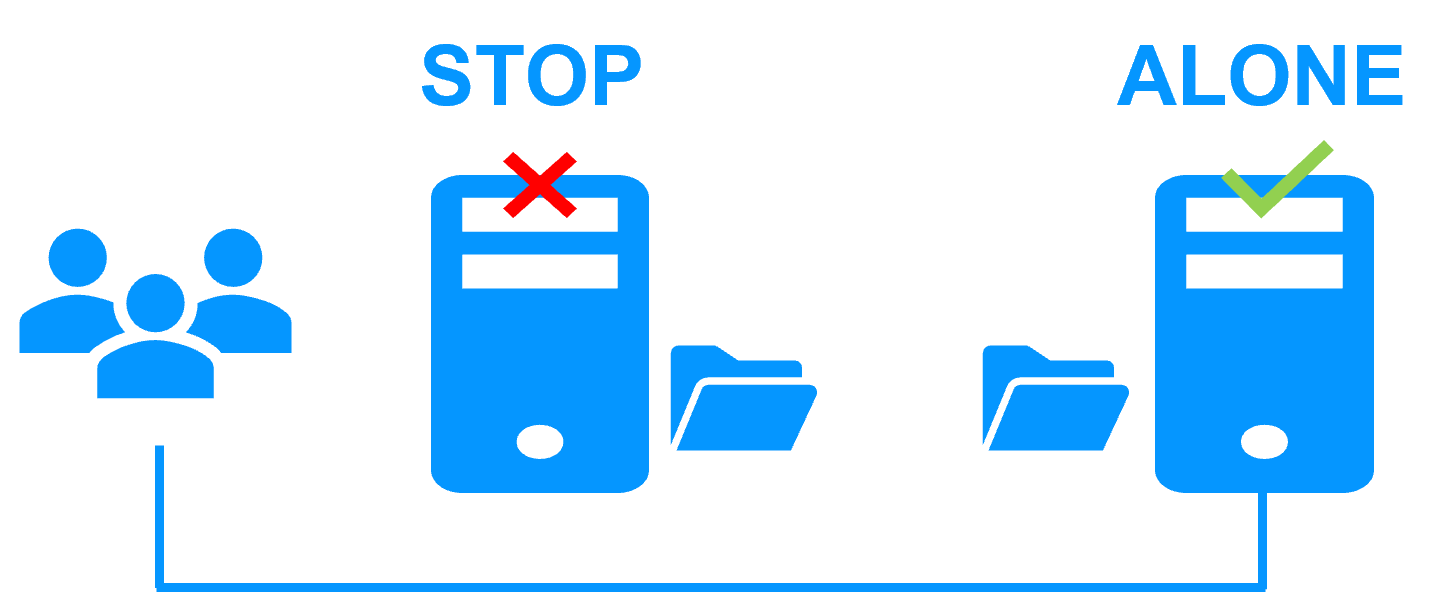
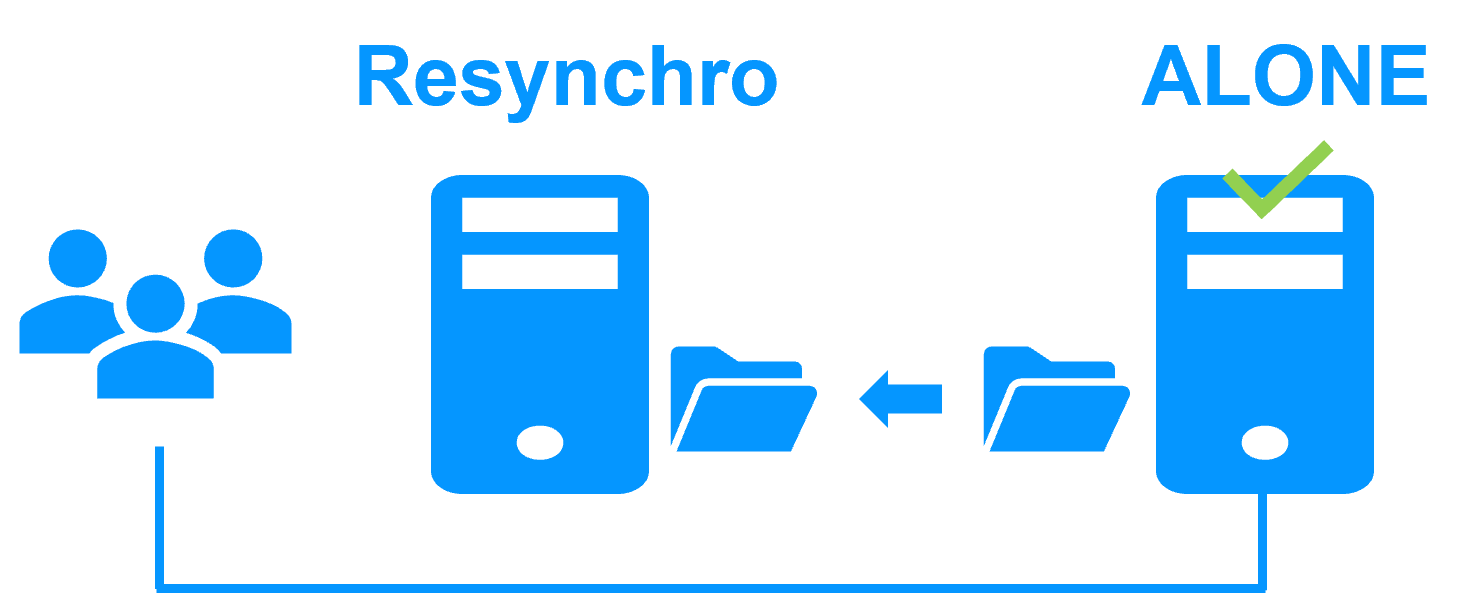
Zero (RPO=0): Synchronous file-level replication. |
Zero: Synchronous writing to a shared disk. |
Non-Zero: Asynchronous replication resulting in data lag. |
| Failover/Failback Logic |
Fully Automatic: Integrated monitoring and restart. |
Requires a third-party failover tool supporting cloud shared disks. |
Manual: Requires activation of a disaster recovery plan. |
| Application Setup |
Zero Reconfiguration: Protects applications where they are currently installed. |
Reconfiguration: Application data must be migrated to a specific shared disk. |
None: Captures the entire OS and application as-is. |
| Replication Scope |
Complete: Application data folders (DB + Config + Logs). |
Partial: Only data stored on the shared volume. |
Total: Replicates the entire virtual machine. |
| VM Localization |
Native Multi-AZ: Synchronous replication across Availability Zones within a region. |
Provider Dependent: Requires shared storage replicated across Availability Zones. |
Regional: Primarily designed for replication between distant geographical regions. |
| Deployment Time |
Low: < 30 Minutes (On-prem or Cloud). |
High: Days or weeks for cluster configuration. |
Medium: Requires setting up DR vaults and policies. |