What is RPO and RTO with examples?
Evidian SafeKit
What is RPO and RTO with examples of high availability and backup solutions?
Overview
This article explores RPO (Recovery Point Objective) and RTO (Recovery Time Objective) with examples of high availability and backup solutions.
High availability and backup solutions are complementary. The first is for automatic failover in the event of a failure and the second is for data recovery in the event of a disaster such as ransomware encrypting all data.
The article explains in detail the RTO and RPO of SafeKit, a high availability software product.
What is RPO?
RPO (Recovery Point Objective) reflects the data loss in the event of a failure.
If you are looking for a high availability cluster with automatic failover, then the RPO should be 0. The application is thus restarted without data loss. Either you can choose a hardware high availability cluster with shared disk. Or you can choose a software high availability cluster with synchronous real-time replication to have 0 data loss.
If you are implementing backup solutions, then the RPO is greater than 0 and the recovery is not automatic. Administrators decide how often to replicate and how many backups to keep.
What is RTO?
RTO (Recovery Time Objective) is the time during which an application is unavailable in the event of a failure.
For a critical application, RTO should be minimal. For this, a high availability solution is necessary with automatic restart of the application in the event of hardware or software failures. RTO is then approximatively one minute: the detection time plus the automatic restart time of the application.
With a backup solution, RTO is generally greater than several hours. Administrators will first attempt to repair the hardware and restart the application on up-to-date data. Restarting from a backup is the last decision when previous actions don't work, because it leads to data loss.
RTO with the example of a SafeKit mirror cluster
The SafeKit mirror cluster is a software high availability cluster with synchronous real-time data replication and automatic application failover.
RTO of the SafeKit mirror cluster is in the order of 1 mn and can be decreased if you configure the heartbeat timeout.
For a hardware failure, RTO = heartbeat timeout (default 30 s) + time to restart the application.
For a software failure or an administrator restart, RTO = time to stop the application + time to restart it.
With solutions that reboot a full virtual machine in case of failure, the RTO includes the reboot time of the virtual machine.
RTO with the example of a SafeKit farm cluster
The SafeKit farm cluster is a software high availability cluster with network load balancing and automatic failover.
RTO of a SafeKit farm cluster is in the order of a few seconds.
For a hardware failure, RTO = failure detection timeout through monitoring channels (default a few seconds). After the timeout the load balancing filters are reconfigured.
For a software failure or an administrator restart, RTO = time to stop the application + time to restart it.
RPO with the example of a SafeKit mirror cluster
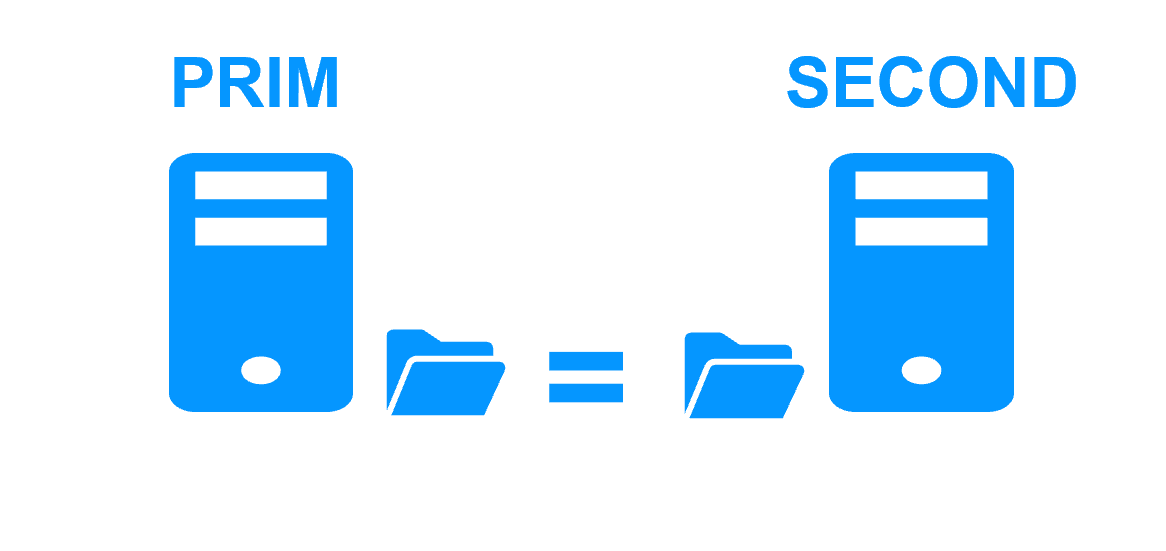
RPO of the SafeKit mirror cluster is 0 as the replication is synchronous and real-time.
Be careful, with asynchronous replication, RPO is not 0 and there is data loss in case of failure when the application restarts on the secondary server.
RPO with the example of a SafeKit farm cluster
N/R. A farm cluster does replicate any data.
What are the advantages of a mirror cluster?
- Low Complexity
- Plug&Play deployment with no specific skills
- Suitable for large deployments in many sites (very simple to deploy)
- 2 physical or virtual nodes
- No shared storage requirement
- No Domain Controller requirement
- Same solution on Windows and Linux
- Support Windows Server and Client OS editions
- Well documented API and support
- Synchronous data replication (no data loss in case of failure)
- Replicated directories can be in the system disk
- Supports multiple heartbeats and vitual IP addresses
- Offers configurable software, hardware and network checkers
- For the split brain problem and the quorum, does not require a special disk or a third machine or a dedicated link between both servers
- Automatic failover of application with a recovery time in the order of one minute
- Automatic failback when a server comes back after a failure (no manual operation)
- A very simple console to deploy the solution and to maintain it afterwards for end-customer
- Supports hardware and environment failures (20% of causes of unavailability), including the complete failure of a computer room with 2 nodes in two remote sites
- Supports software failures (40% of causes of unavailability): software bug, regression on software update (N and N+1 versions can coexist)
- Supports human errors (40% of causes of unavailability) : the simplicity of use avoids the administration error of the critical application
What are the advantages of a farm cluster
- Low Complexity
- Plug&Play deployment with no specific skills
- Suitable for large deployments in many sites (very simple to deploy)
- 2 physical or virtual nodes or more
- No network load balancers requirement
- No proxy server requirement (above the farm cluster)
- No Domain Controller requirement
- No restriction in VMware due to multicast or unicast address
- Same solution on Windows and Linux
- Support Windows Server and Client OS editions
- Well documented API and support
- Supports multiple monitoring channels on multiple networks for server failure detection
- Supports multiple vitual IP addresses
- Offers configurable software, hardware and network checkers
- Offers the mirror cluster with synchronous real-time replication and failover to implement a farm+mirror 3-tiers architecture
- Automatic failover with a recovery time in the order of a few seconds
- Automatic failback when a server comes back after a failure (no manual operation)
- A very simple console to deploy the solution and to maintain it afterwards for end-customer
- Supports hardware and environment failures (20% of causes of unavailability), including the complete failure of a computer room with 2 nodes in two remote sites
- Supports software failures (40% of causes of unavailability): software bug, regression on software update (N and N+1 versions can coexist)
- Supports human errors (40% of causes of unavailability): the simplicity of use avoids the administration error of the critical application
New application (real-time replication and failover)
- Windows (mirror.safe)
- Linux (mirror.safe)
New application (network load balancing and failover)
Database (real-time replication and failover)
- Microsoft SQL Server (sqlserver.safe)
- PostgreSQL (postgresql.safe)
- MySQL (mysql.safe)
- Oracle (oracle.safe)
- MariaDB (sqlserver.safe)
- Firebird (firebird.safe)
Web (network load balancing and failover)
- Apache (apache_farm.safe)
- IIS (iis_farm.safe)
- NGINX (farm.safe)
Full VM or container real-time replication and failover
- Hyper-V (hyperv.safe)
- KVM (kvm.safe)
- Docker (mirror.safe)
- Podman (mirror.safe)
- Kubernetes K3S (k3s.safe)
Amazon AWS
- AWS (mirror.safe)
- AWS (farm.safe)
Google GCP
- GCP (mirror.safe)
- GCP (farm.safe)
Microsoft Azure
- Azure (mirror.safe)
- Azure (farm.safe)
Other clouds
- All Cloud Solutions
- Generic (mirror.safe)
- Generic (farm.safe)
Physical security (real-time replication and failover)
- Milestone XProtect (milestone.safe)
- Nedap AEOS (nedap.safe)
- Genetec SQL Server (sqlserver.safe)
- Bosch AMS (hyperv.safe)
- Bosch BIS (hyperv.safe)
- Bosch BVMS (hyperv.safe)
- Hanwha Vision (hyperv.safe)
- Hanwha Wisenet (hyperv.safe)
Siemens (real-time replication and failover)
- Siemens Siveillance suite (hyperv.safe)
- Siemens Desigo CC (hyperv.safe)
- Siemens Siveillance VMS (SiveillanceVMS.safe)
- Siemens SiPass (hyperv.safe)
- Siemens SIPORT (hyperv.safe)
- Siemens SIMATIC PCS 7 (hyperv.safe)
- Siemens SIMATIC WinCC (hyperv.safe)
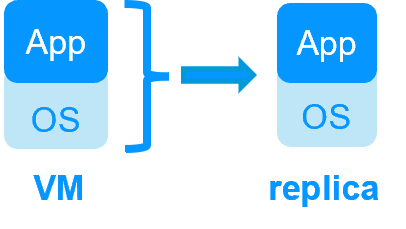
| VM HA with the SafeKit Hyper-V or KVM module | Application HA with SafeKit application modules |
 |
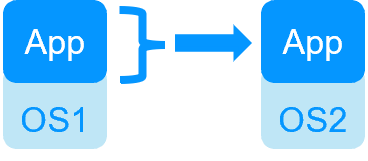 |
| SafeKit inside 2 hypervisors: replication and failover of full VM | SafeKit inside 2 virtual or physical machines: replication and failover at application level |
| Replicates more data (App+OS) | Replicates only application data |
| Reboot of VM on hypervisor 2 if hypervisor 1 crashes Recovery time depending on the OS reboot VM checker and failover (Virtual Machine is unresponsive, has crashed, or stopped working) |
Quick recovery time with restart of App on OS2 if crash of server 1 Around 1 mn or less (see RTO/RPO here) Application checker and software failover |
| Generic solution for any application / OS | Restart scripts to be written in application modules |
| Works with Windows/Hyper-V and Linux/KVM but not with VMware | Platform agnostic, works with physical or virtual machines, cloud infrastructure and any hypervisor including VMware |
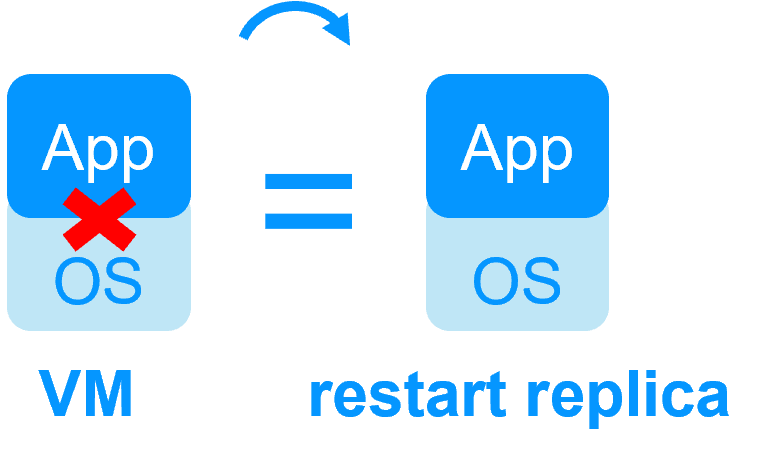
| SafeKit with the Hyper-V module or the KVM module | Microsoft Hyper-V Cluster & VMware HA |
 |
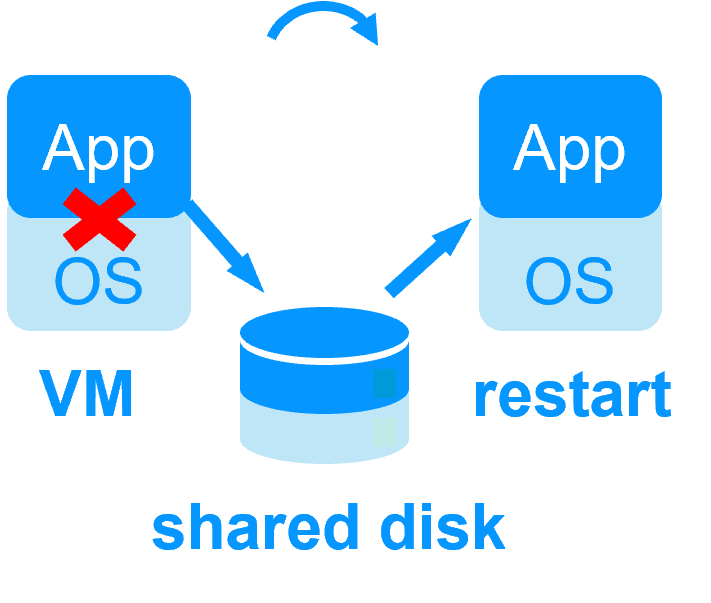 |
 No shared disk - synchronous real-time replication instead with no data loss No shared disk - synchronous real-time replication instead with no data loss |
 Shared disk and specific extenal bay of disk Shared disk and specific extenal bay of disk |
| Remote sites = no SAN for replication |
Remote sites = replicated bays of disk across a SAN |
| No specific IT skill to configure the system (with hyperv.safe and kvm.safe) |
Specific IT skills to configure the system |
| Note that the Hyper-V/SafeKit and KVM/SafeKit solutions are limited to replication and failover of 32 VMs. | Note that the Hyper-V built-in replication does not qualify as a high availability solution. This is because the replication is asynchronous, which can result in data loss during failures, and it lacks automatic failover and failback capabilities. |
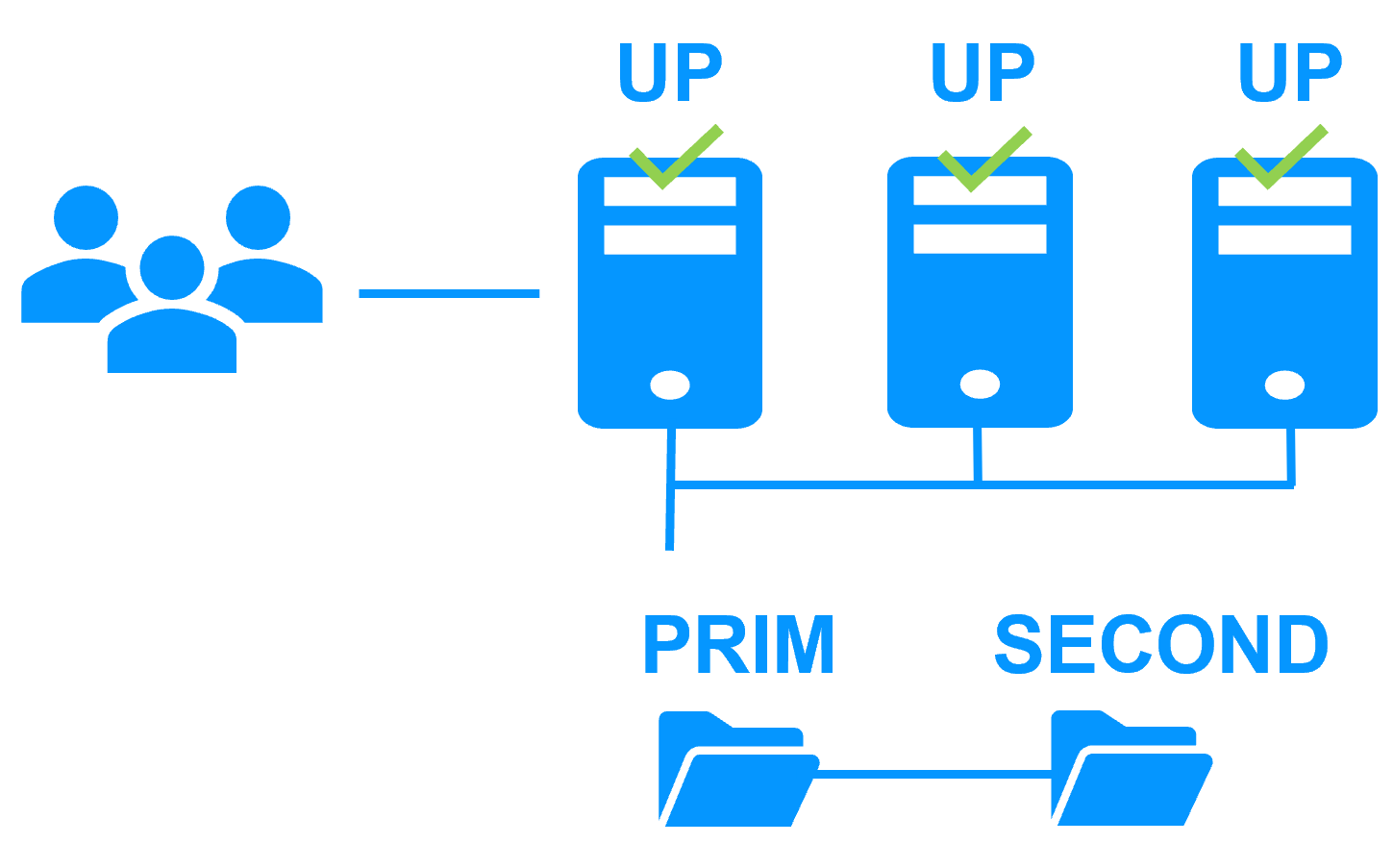
Evidian SafeKit mirror cluster with real-time file replication and failover |
|
3 products in 1
More info >
 |
|
Very simple configuration
More info >
 |
|
Synchronous replication
More info >
 |
|
Fully automated failback
More info >
 |
|
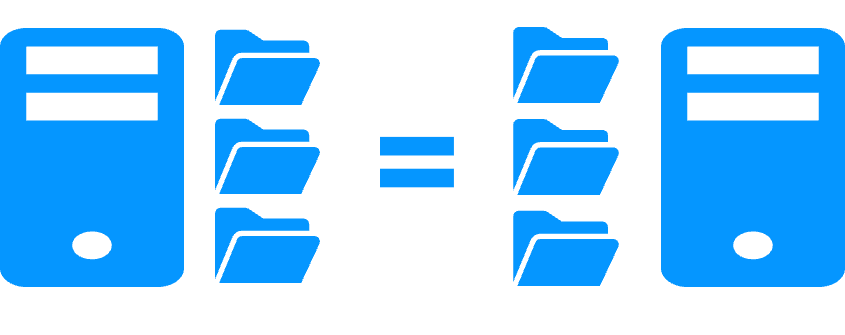
Replication of any type of data
More info >
 |
|
File replication vs disk replication
More info >
 |
|
File replication vs shared disk
More info >
 |
|
Remote sites and virtual IP address
More info >
 |
|
Quorum and split brain
More info >
 |
|
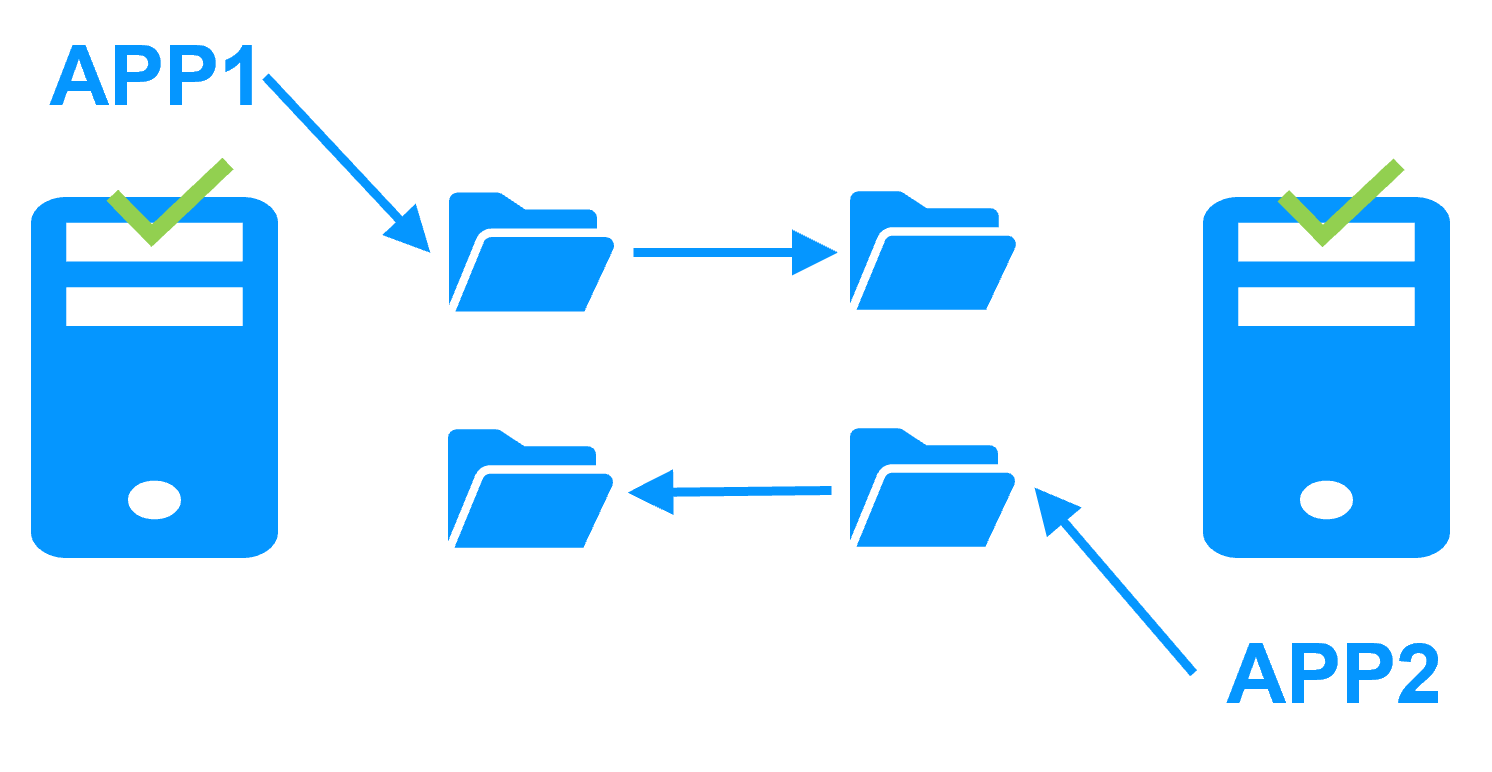
Active/active cluster
More info >
 |
|
Uniform high availability solution
More info >
 |
|
|
RTO / RPO
More info >
|
|
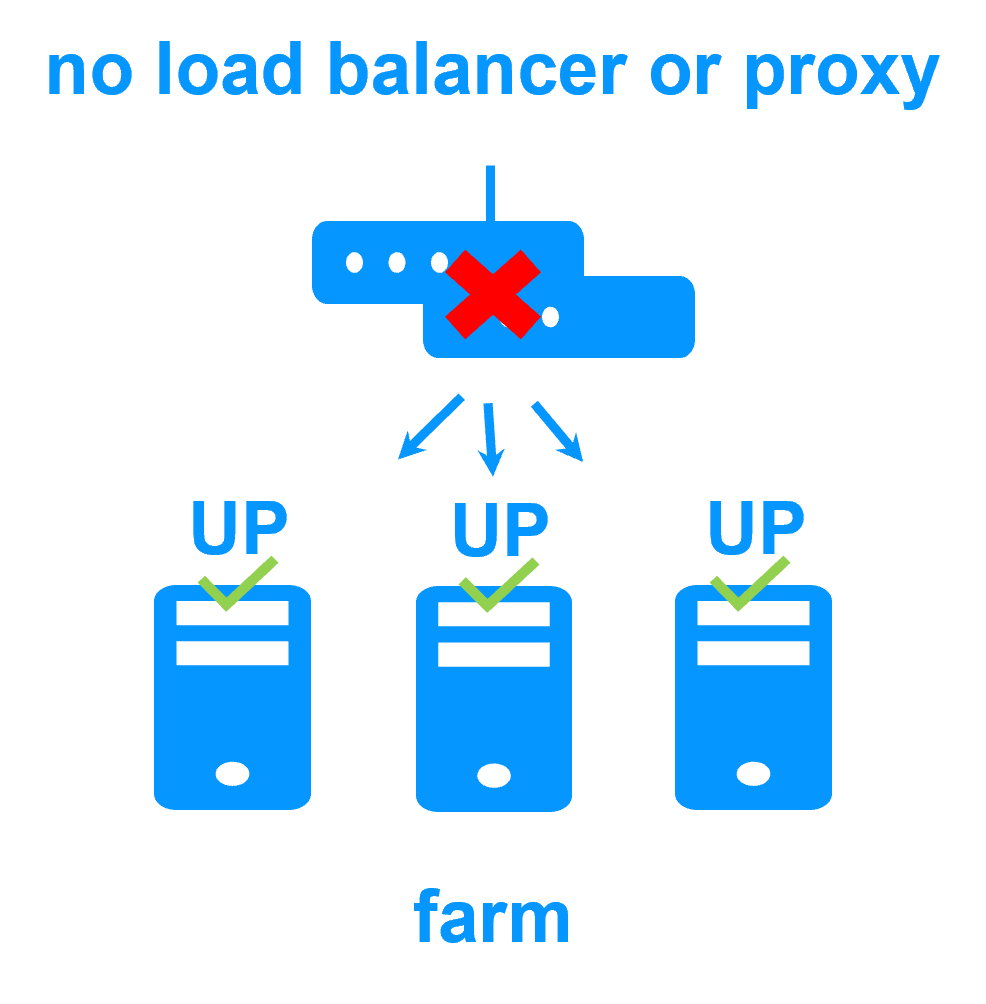
Evidian SafeKit farm cluster with load balancing and failover |
|
No load balancer or dedicated proxy servers or special multicast Ethernet address
More info >
 |
|
|
All clustering features
More info >
|
|
|
Remote sites and virtual IP address
More info >
|
|
|
Uniform high availability solution
More info >
|
|
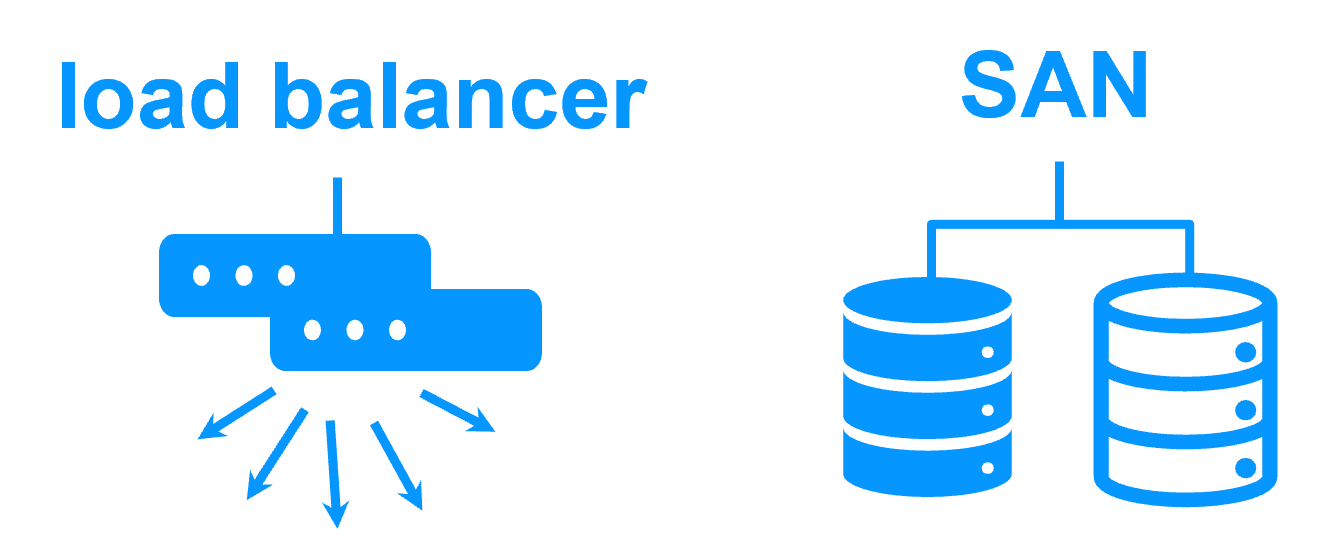
Software clustering vs hardware clustering More info > |
|
|
|
Shared nothing vs a shared disk cluster More info > |
|
|
|
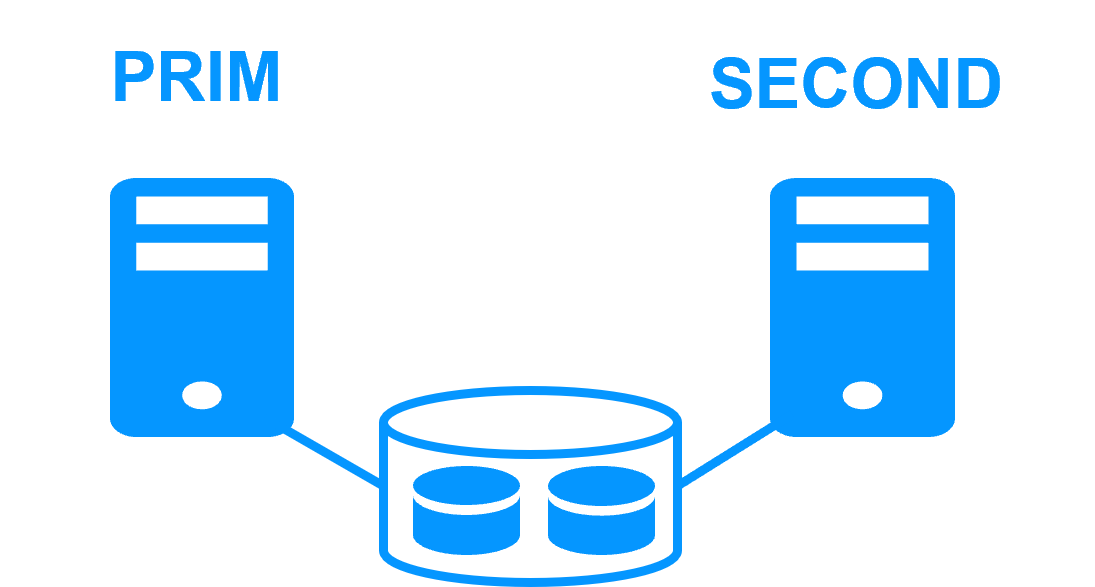
Application High Availability vs Full Virtual Machine High Availability More info > |
|
|
|
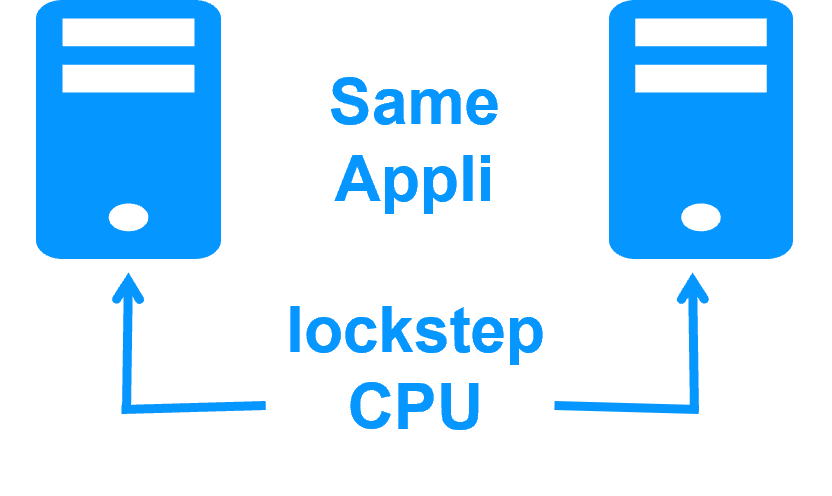
High availability vs fault tolerance More info > |
|
|
|
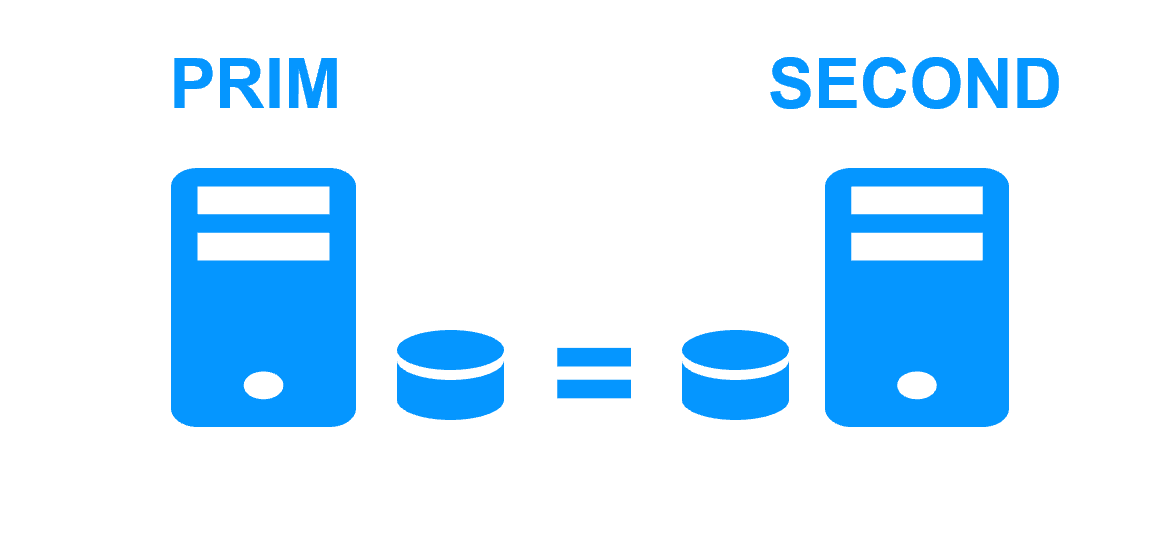
Synchronous replication vs asynchronous replication More info > |
|
|

|
Byte-level file replication vs block-level disk replication More info > |
|
|
|
Heartbeat, failover and quorum to avoid 2 master nodes More info > |
|
|
|
Virtual IP address primary/secondary, network load balancing, failover More info > |
|

|
|