Heartbeat, failover and quorum in a Windows or Linux cluster
Evidian SafeKit
A single network
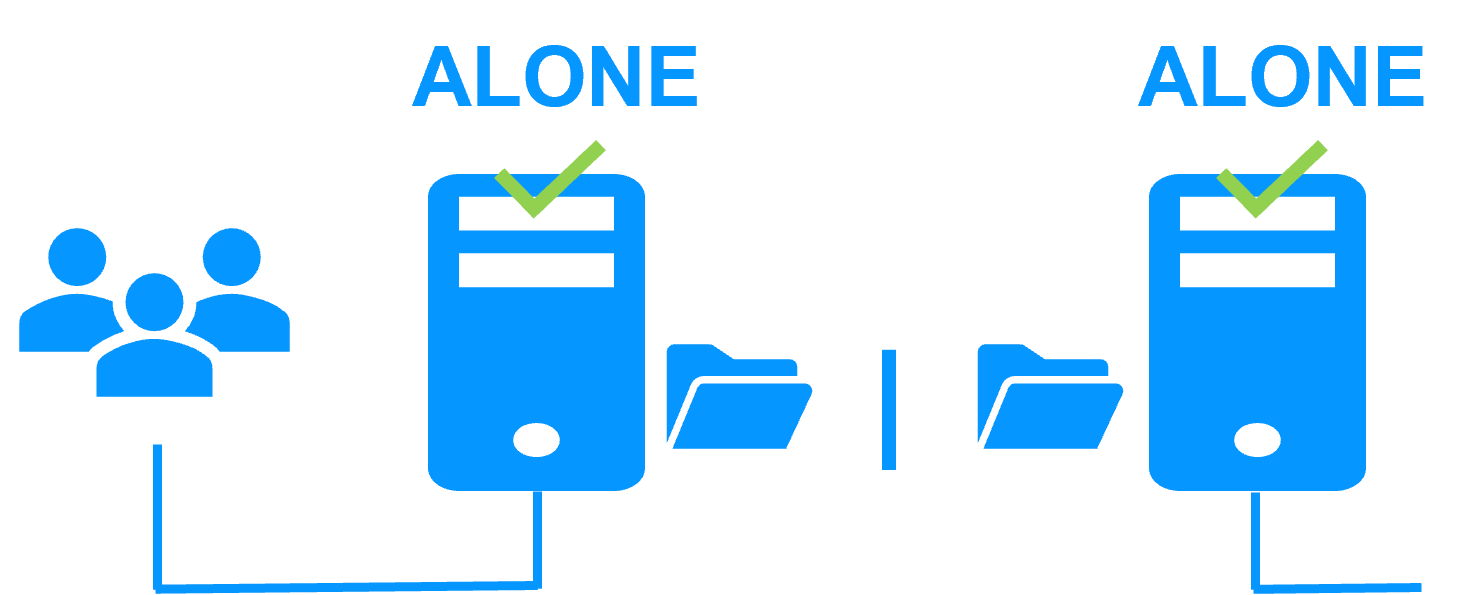
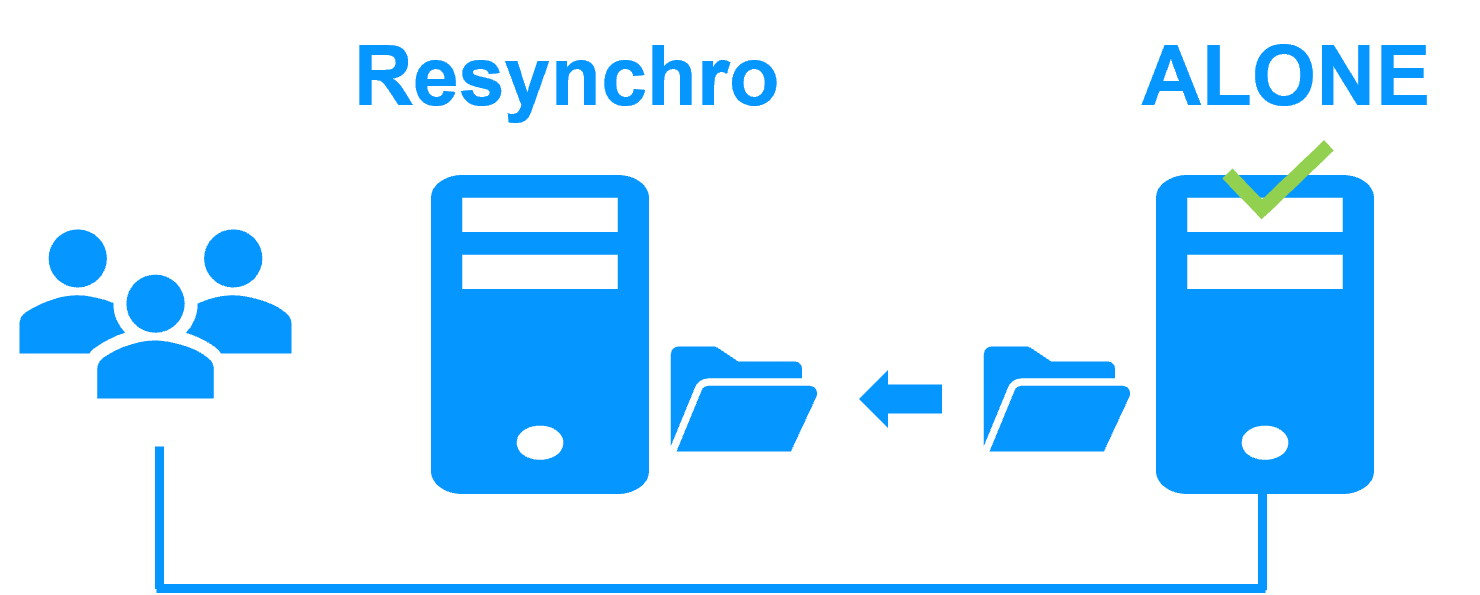
When there is a network isolation, the default behavior is:
- as heartbeats are lost for each node, each node goes to ALONE and runs the application with its virtual IP address (double execution of the application modifying its local data),
- when the isolation is repaired, one ALONE node is forced to stop and to resynchronize its data from the other node,
- at the end the cluster is PRIM-SECOND (or SECOND-PRIM according the duplicate virtual IP address detection made by Windows).
Two networks with a dedicated replication network
When there is a network isolation, the behavior with a dedicated replication network is:
- a dedicated replication network is implemented on a private network,
- heartbeats on the production network are lost (isolated network),
- heartbeats on the replication network are working (not isolated network),
- the cluster stays in PRIM/SECOND state.
A single network and a splitbrain checker
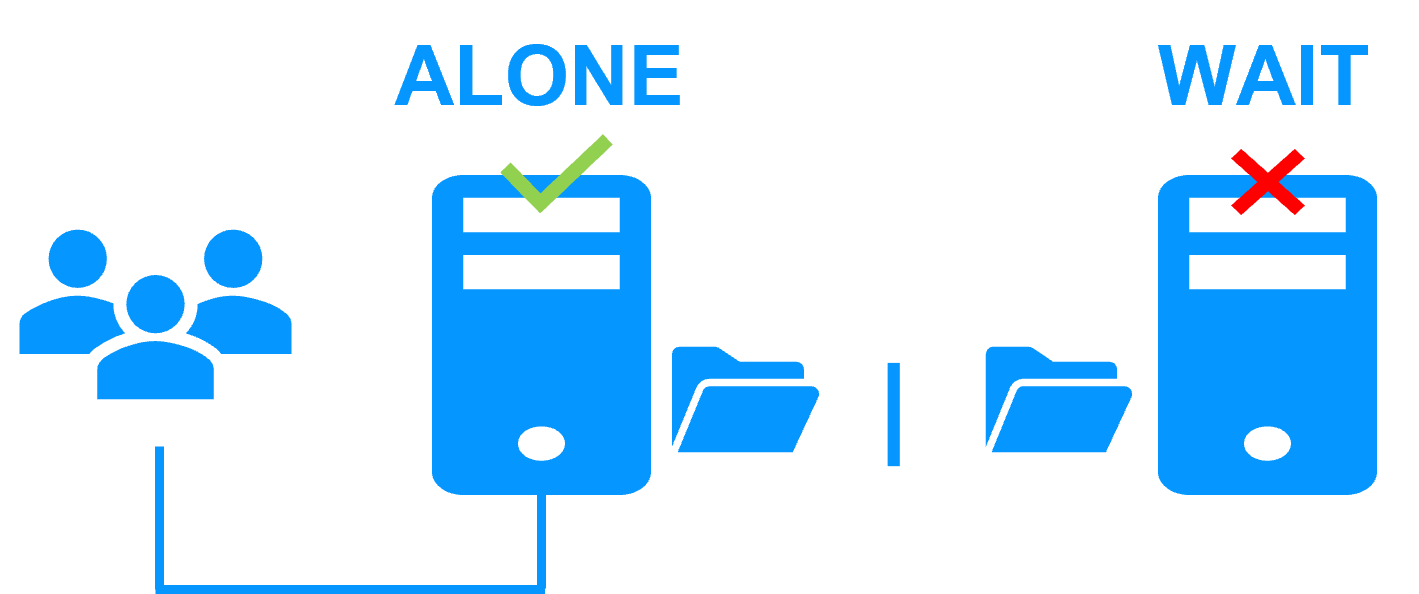
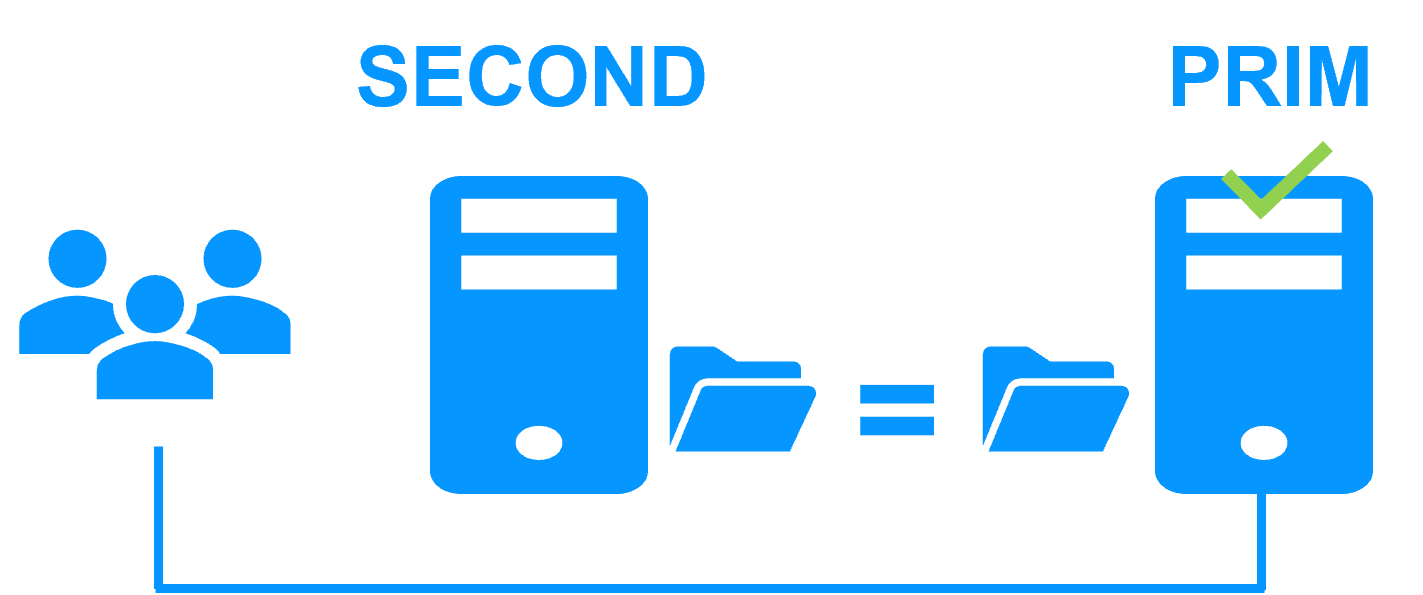
When there is a network isolation, the behavior with a split-brain checker is:
- a split-brain checker has been configured with the IP address of a witness (typically a router),
- the split-brain checker operates when a server goes from PRIM to ALONE or from SECOND to ALONE,
- in case of network isolation, before going to ALONE, both nodes test the IP address,
- the node which can access the IP address goes to ALONE, the other one goes to WAIT,
- when the isolation is repaired, the WAIT node resynchronizes its data and becomes SECOND.
Note: If the witness is down or disconnected, both nodes go to WAIT and the application is no more running. That's why you must choose a robust witness like a router.
What is a heartbeat?
The basic mechanism for synchronizing two servers and detecting server failures is the heartbeat, which is a monitoring data flow on a network shared by a pair of servers.
The SafeKit software supports as many heartbeats as there are networks shared by two servers.
The heartbeat mechanism is used to implement Windows and Linux clusters. It is integrated within the SafeKit mirror cluster with real-time file replication and failover.
SafeKit heartbeats
In normal operation, the two servers exchange their states (PRIM, SECOND, the resource states) through the heartbeat channels and synchronize their application start and stop procedures.
In particular, in case of a scheduled failover, the stop script which stops the application is first executed on the primary server, before executing the start script on the secondary server. Thus, replicated data on the secondary server are in a safe state corresponding to a clean stop of the application.
Loss of all heartbeats
When all heartbeats are lost on one server, this server considers the other server to be down and transitions to the ALONE state.
If it is the SECOND server which goes to the ALONE state, then there is an application failover with restart of the application on the secondary server.
Although not mandatory, it is better to have two heartbeat channels on two different networks for synchronizing the two servers in order to separate the network failure case from the server failure one.

Remote computer rooms
A high availability cluster securing a critical application can be implemented with two servers in two geographically remote computer rooms.
Thus, the solution supports the disaster of a full room.
Split brain
In situation of a network isolation between both computer rooms, all heartbeats are lost and the split brain problem arises.
Both servers start the critical application.
Complexity of solutions
Mostoften, to solve split brain, quorum is implemented with a third quorum server or a special quorum disk to avoid the double masters.
Unfortunately these new quorum devices add cost and complexity to the overall clustering architecture.
SafeKit split brain checker
With the SafeKit high availability software, the quorum within a Windows or Linux cluster requires no third quorum server and no quorum disk. A simple split brain checker is sufficient to avoid the double execution of an application.
On the the loss of all heartbeats between servers, the split brain checker selects only one server to become the primary. The other server goes into the WAIT state, until it receives the other server's heartbeats again. It then goes back to secondary after having synchronized replicated data from the primary server.
How the split brain checker works?
The primary server election is based on the ping of an IP address, called the witness. The witness is typically a router that is always available. In case of network isolation, only the server with access to the witness will be primary ALONE, the other will go to WAIT.
The witness is not tested permanently but only when all heartbeats are lost. If at that time, the witness is down, the cluster goes into the WAIT-WAIT state and an administrator can choose to restart one of the servers as primary through the SafeKit web console.
What happens without a split brain checker?
In case of network isolation, both servers will go to the ALONE state running the critical application. The replicated directories are isolated and each application is working on its own data in its own directory.
When the network is reconnected, SafeKit by default chooses the server which was PRIM before the isolation as the new primay and forces the other one as SECOND with a resynchronization of all its data from the PRIM.
Note: Windows can detect a duplicate IP address on one server and remove the virtual IP address on this server. SafeKit has a checker to force a restart in that case.
Partners, the success with SafeKit
This platform agnostic solution is ideal for a partner reselling a critical application and who wants to provide a redundancy and high availability option easy to deploy to many customers.
With many references in many countries won by partners, SafeKit has proven to be the easiest solution to implement for redundancy and high availability of building management, video management, access control, SCADA software...



Building Management Software (BMS)

Video Management Software (VMS)

Electronic Access Control Software (EACS)

SCADA Software (Industry)

Step 1. Real-time replication
Server 1 (PRIM) runs the application. Clients are connected to a virtual IP address. SafeKit replicates in real time modifications made inside files through the network.
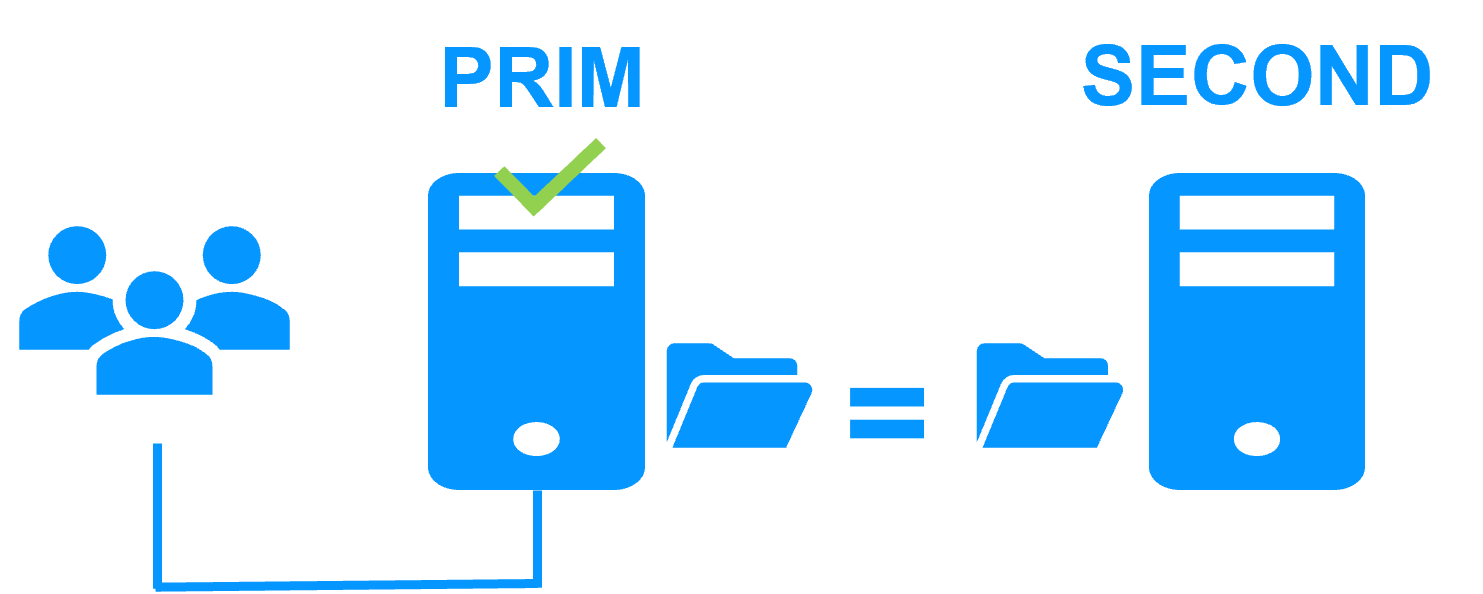
The replication is synchronous with no data loss on failure contrary to asynchronous replication.
You just have to configure the names of directories to replicate in SafeKit. There are no pre-requisites on disk organization. Directories may be located in the system disk.
Step 2. Automatic failover
When Server 1 fails, Server 2 takes over. SafeKit switches the virtual IP address and restarts the application automatically on Server 2.
The application finds the files replicated by SafeKit uptodate on Server 2. The application continues to run on Server 2 by locally modifying its files that are no longer replicated to Server 1.
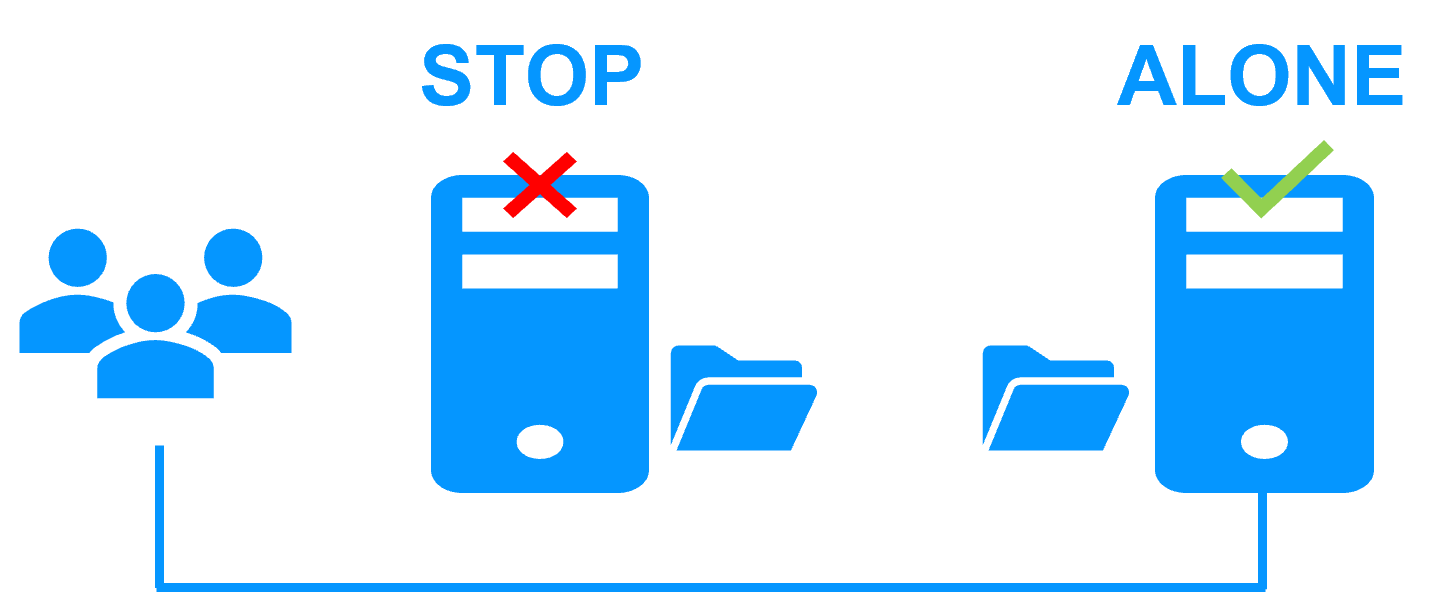
The failover time is equal to the fault-detection time (30 seconds by default) plus the application start-up time.
Step 3. Automatic failback
Failback involves restarting Server 1 after fixing the problem that caused it to fail.
SafeKit automatically resynchronizes the files, updating only the files modified on Server 2 while Server 1 was halted.
Failback takes place without disturbing the application, which can continue running on Server 2.
Step 4. Back to normal
After reintegration, the files are once again in mirror mode, as in step 1. The system is back in high-availability mode, with the application running on Server 2 and SafeKit replicating file updates to Server 1.
If the administrator wishes the application to run on Server 1, he/she can execute a "swap" command either manually at an appropriate time, or automatically through configuration.
More information on power outage and network isolation in a cluster.
Why a replication of a few Tera-bytes?
Resynchronization time after a failure (step 3)
- 1 Gb/s network ≈ 3 Hours for 1 Tera-bytes.
- 10 Gb/s network ≈ 1 Hour for 1 Tera-bytes or less depending on disk write performances.
Alternative
- For a large volume of data, use external shared storage.
- More expensive, more complex.
Why a replication < 1,000,000 files?
- Resynchronization time performance after a failure (step 3).
- Time to check each file between both nodes.
Alternative
- Put the many files to replicate in a virtual hard disk / virtual machine.
- Only the files representing the virtual hard disk / virtual machine will be replicated and resynchronized in this case.
Why a failover ≤ 32 replicated VMs?
- Each VM runs in an independent mirror module.
- Maximum of 32 mirror modules running on the same cluster.
Alternative
- Use an external shared storage and another VM clustering solution.
- More expensive, more complex.
Why a LAN/VLAN network between remote sites?
- Automatic failover of the virtual IP address with 2 nodes in the same subnet.
- Good bandwidth for resynchronization (step 3) and good latency for synchronous replication (typically a round-trip of less than 2ms).
Alternative
- Use a load balancer for the virtual IP address if the 2 nodes are in 2 subnets (supported by SafeKit, especially in the cloud).
- Use backup solutions with asynchronous replication for high latency network.
Evidian SafeKit mirror cluster with real-time file replication and failover |
|
|
3 products in 1 More info >  |
|
|
Very simple configuration More info >  |
|
|
Synchronous replication More info > 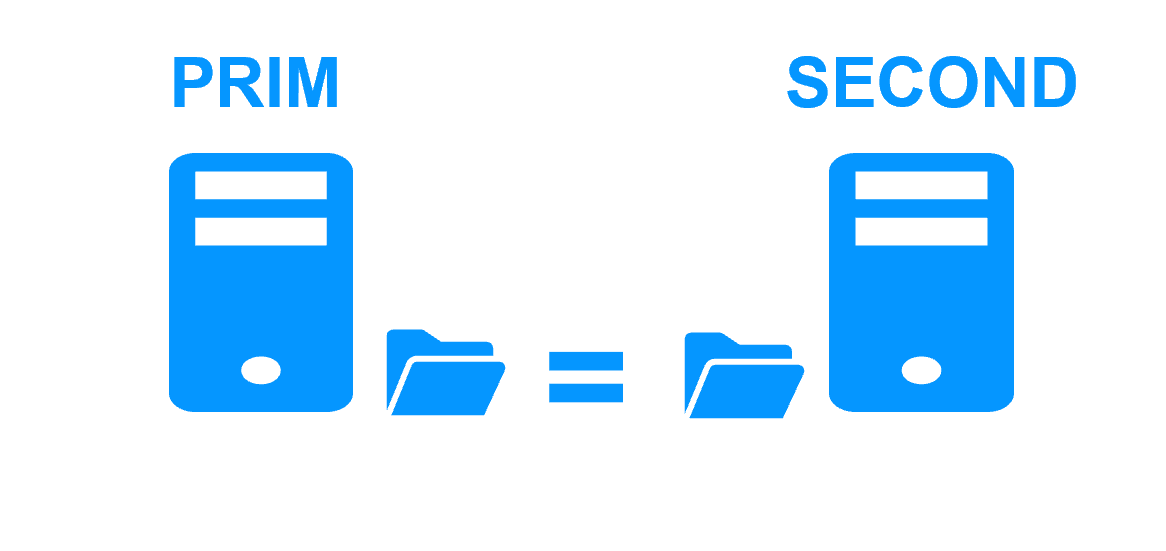 |
|
|
Fully automated failback More info >  |
|
|
Replication of any type of data More info >  |
|
|
File replication vs disk replication More info >  |
|
|
File replication vs shared disk More info >  |
|
|
Remote sites and virtual IP address More info >  |
|
|
Quorum and split brain More info > |
|
|
Active/active cluster More info > 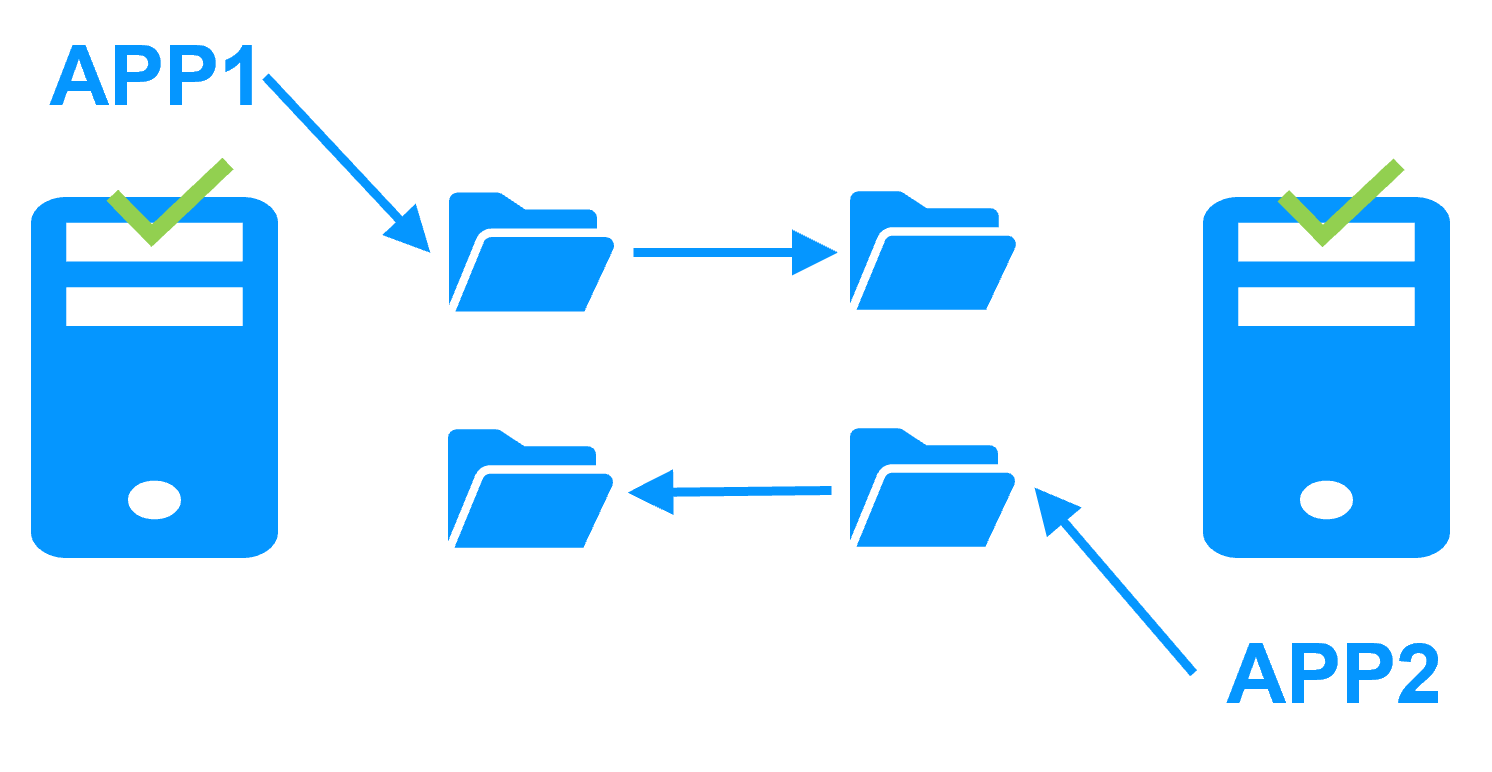 |
|
|
Uniform high availability solution More info > 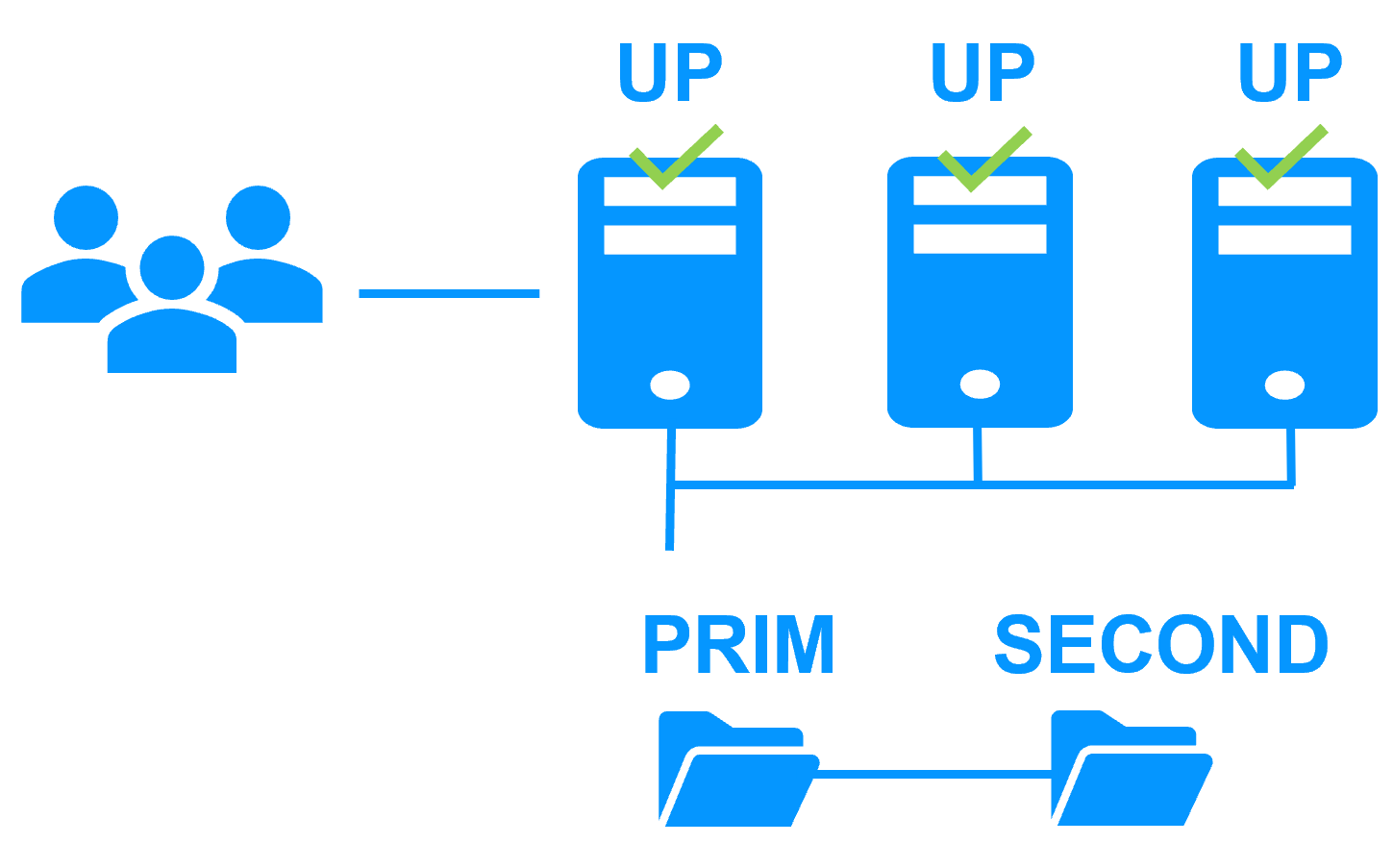 |
|
|
RTO / RPO More info >  |
|
Evidian SafeKit farm cluster with load balancing and failover |
|
|
No load balancer or dedicated proxy servers or special multicast Ethernet address 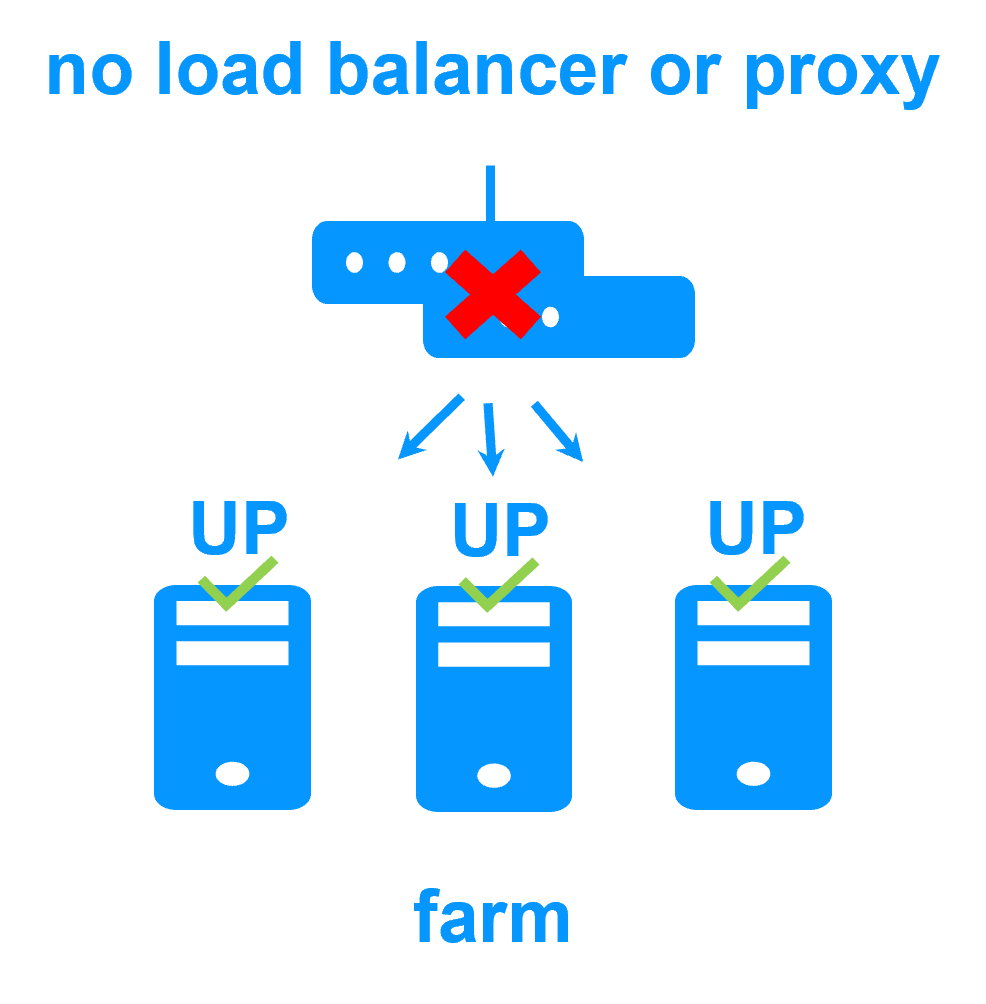
|
|
|
All clustering features
|
|
|
Remote sites and virtual IP address
|
|
|
Uniform high availability solution
|
|
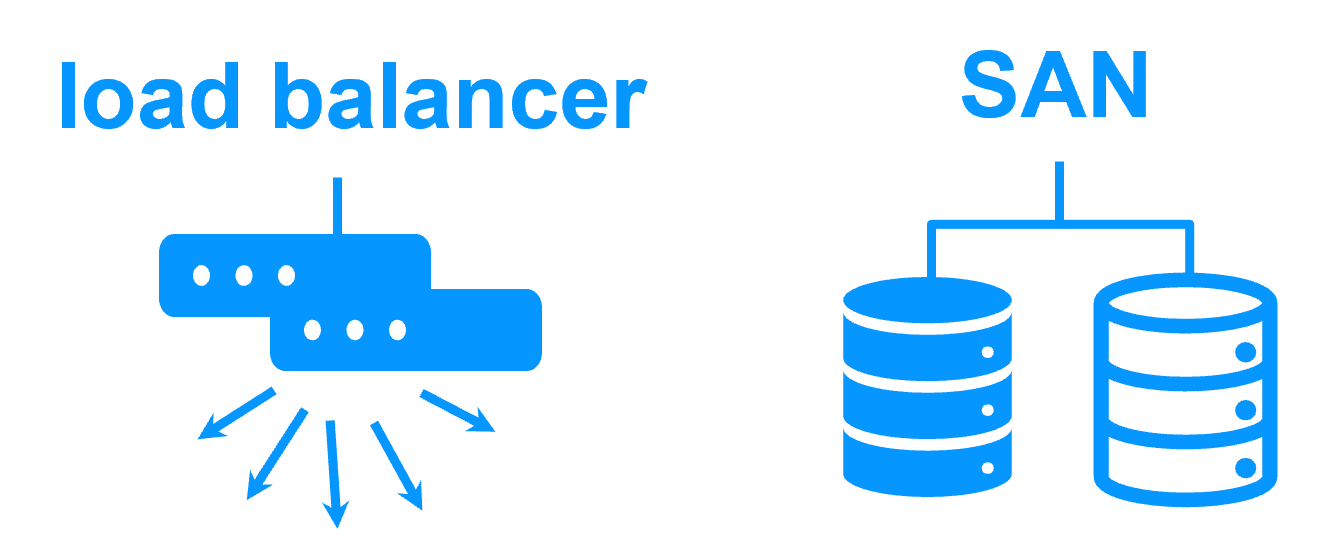
Software clustering vs hardware clustering
|
|
|
|
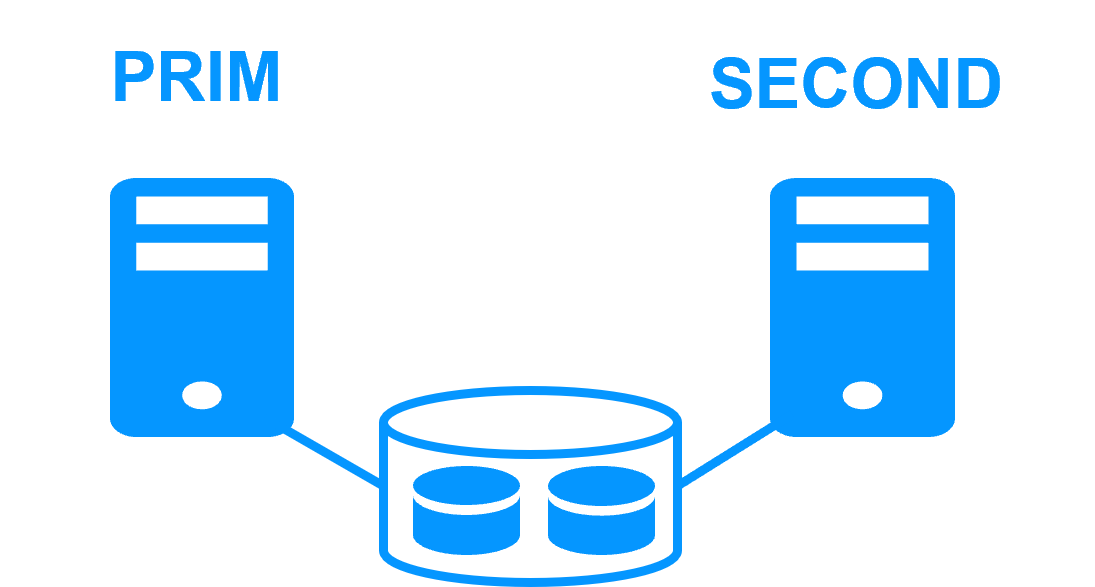
Shared nothing vs a shared disk cluster |
|
|
|
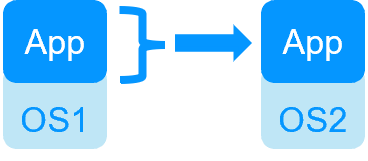
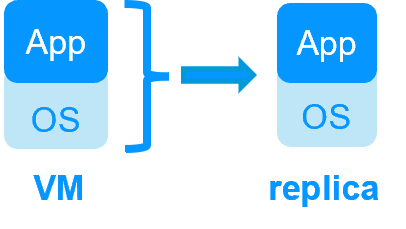
Application High Availability vs Full Virtual Machine High Availability
|
|
|
|
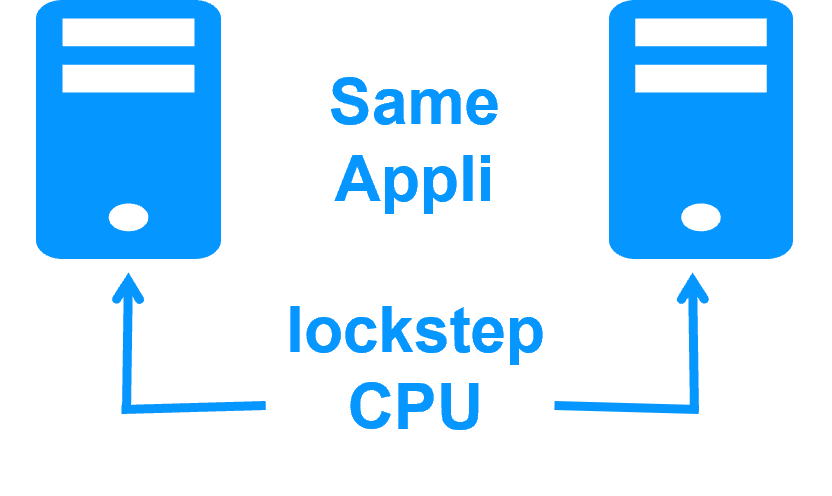
High availability vs fault tolerance
|
|
|
|
Synchronous replication vs asynchronous replication
|
|
|

|
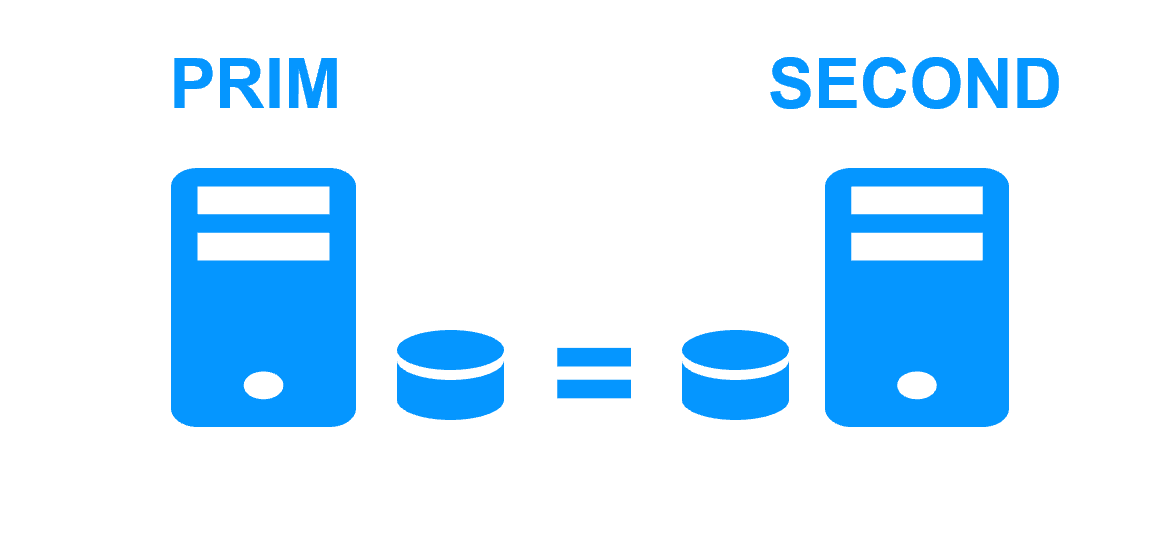
Byte-level file replication vs block-level disk replication
|
|
|
|
Heartbeat, failover and quorum to avoid 2 master nodes
|
|
|
|
Virtual IP address primary/secondary, network load balancing, failover
|
|

|
|
Network load balancing and failover |
|
| Windows farm | Linux farm |
| Generic Windows farm > | Generic Linux farm > |
| Microsoft IIS > | - |
| NGINX > | |
| Apache > | |
| Amazon AWS farm > | |
| Microsoft Azure farm > | |
| Google GCP farm > | |
| Other cloud > | |
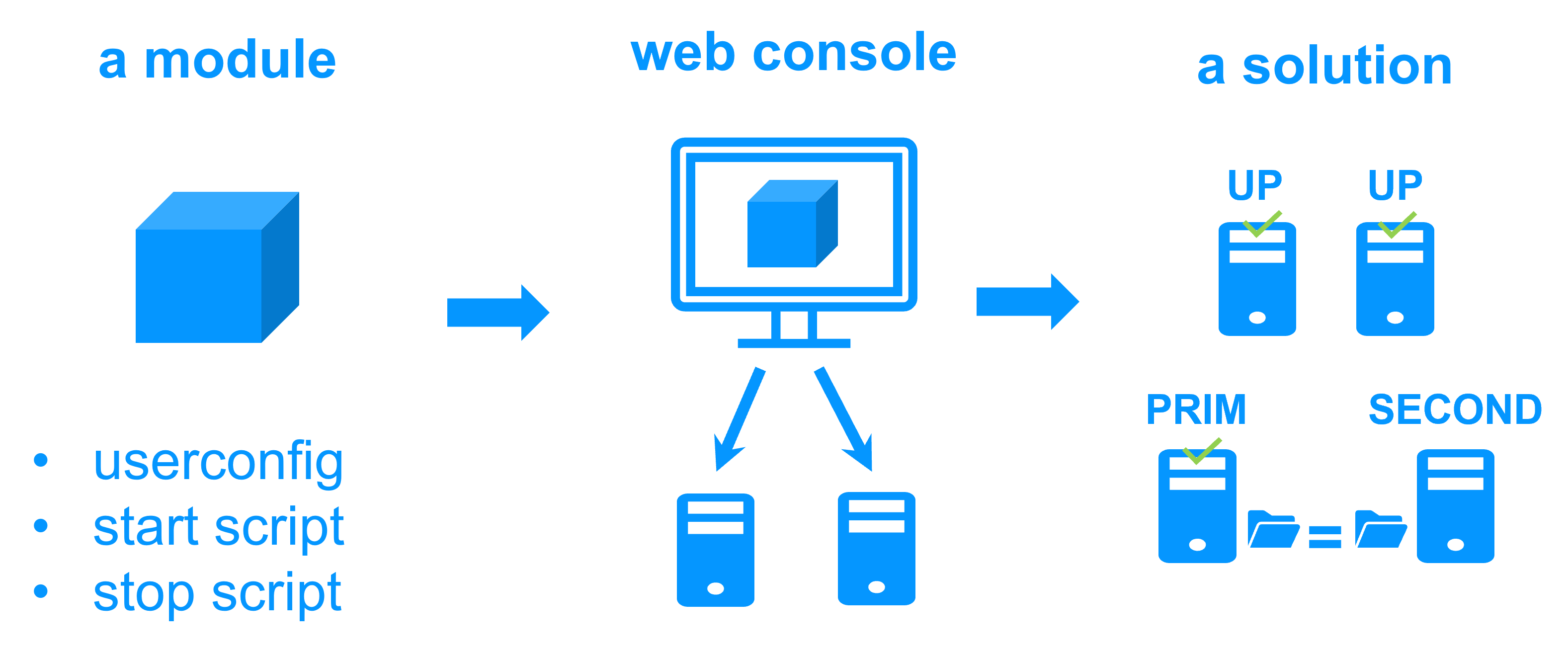
Advanced clustering architectures
Several modules can be deployed on the same cluster. Thus, advanced clustering architectures can be implemented:
- the farm+mirror cluster built by deploying a farm module and a mirror module on the same cluster,
- the active/active cluster with replication built by deploying several mirror modules on 2 servers,
- the Hyper-V cluster or KVM cluster with real-time replication and failover of full virtual machines between 2 active hypervisors,
- the N-1 cluster built by deploying N mirror modules on N+1 servers.

- Demonstration
- Examples of redundancy and high availability solution
- Evidian SafeKit sold in many different countries with Milestone
- 2 solutions: virtual machine cluster or application cluster
- Distinctive advantages
- More information on the web site
Evidian SafeKit 8.2
All new features compared to 7.5 described in the release notes
Packages
- Windows (with Microsoft Visual C++ Redistributable)
- Windows (without Microsoft Visual C++ Redistributable)
- Linux
- Supported OS and last fixes
One-month license key
Technical documentation
Product information
Training
Introduction
-
- Demonstration
- Examples of redundancy and high availability solution
- Evidian SafeKit sold in many different countries with Milestone
- 2 solutions: virtual machine or application cluster
- Distinctive advantages
- More information on the web site
-
- Cluster of virtual machines
- Mirror cluster
- Farm cluster
Installation, Console, CLI
- Install and setup / pptx
- Package installation
- Nodes setup
- Upgrade
- Web console / pptx
- Configuration of the cluster
- Configuration of a new module
- Advanced usage
- Securing the web console
- Command line / pptx
- Configure the SafeKit cluster
- Configure a SafeKit module
- Control and monitor
Advanced configuration
- Mirror module / pptx
- start_prim / stop_prim scripts
- userconfig.xml
- Heartbeat (<hearbeat>)
- Virtual IP address (<vip>)
- Real-time file replication (<rfs>)
- How real-time file replication works?
- Mirror's states in action
- Farm module / pptx
- start_both / stop_both scripts
- userconfig.xml
- Farm heartbeats (<farm>)
- Virtual IP address (<vip>)
- Farm's states in action
Troubleshooting
- Troubleshooting / pptx
- Analyze yourself the logs
- Take snapshots for support
- Boot / shutdown
- Web console / Command lines
- Mirror / Farm / Checkers
- Running an application without SafeKit
Support
- Evidian support / pptx
- Get permanent license key
- Register on support.evidian.com
- Call desk