Heartbeat, failover et quorum dans un cluster Windows ou Linux
Evidian SafeKit
Un seul réseau
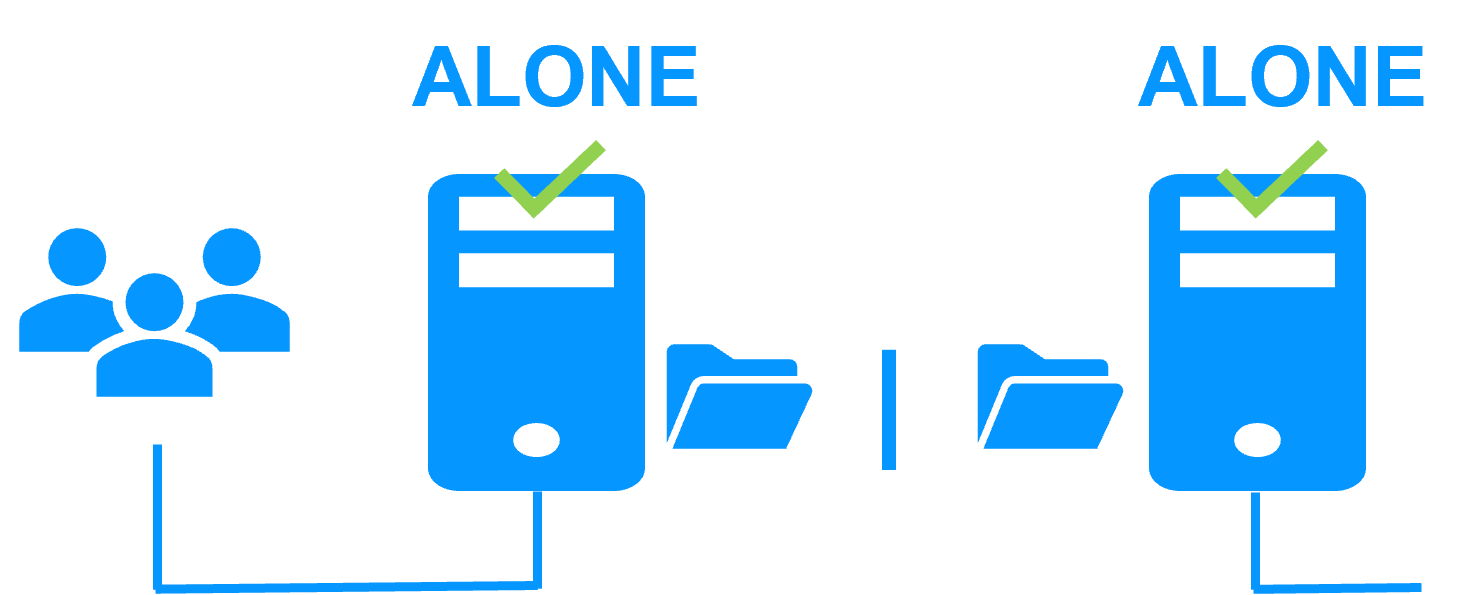
Lorsqu'il y a un isolement réseau, le comportement par défaut est :
- comme les heartbeats sont perdus pour chaque nœud, chaque nœud passe en ALONE et exécute l'application avec son adresse IP virtuelle (double exécution de l'application modifiant ses données locales),
- lorsque l'isolement est réparé, un nœud ALONE est obligé de s'arrêter et de resynchroniser ses données depuis l'autre nœud,
- à la fin, le cluster est PRIM-SECOND (ou SECOND-PRIM selon la détection d'adresse IP virtuelle en double faite par Windows).
Deux réseaux avec un réseau de réplication dédié
Lorsqu'il y a un isolement réseau, le comportement avec un réseau de réplication dédié est :
- un réseau de réplication dédié est implémenté sur un réseau privé,
- les heartbeats sur le réseau de production sont perdus (réseau isolé),
- les heartbeats sur le réseau de réplication fonctionnent (réseau non isolé),
- le cluster reste à l'état PRIM/SECOND.
Un seul réseau et un checker split-brain
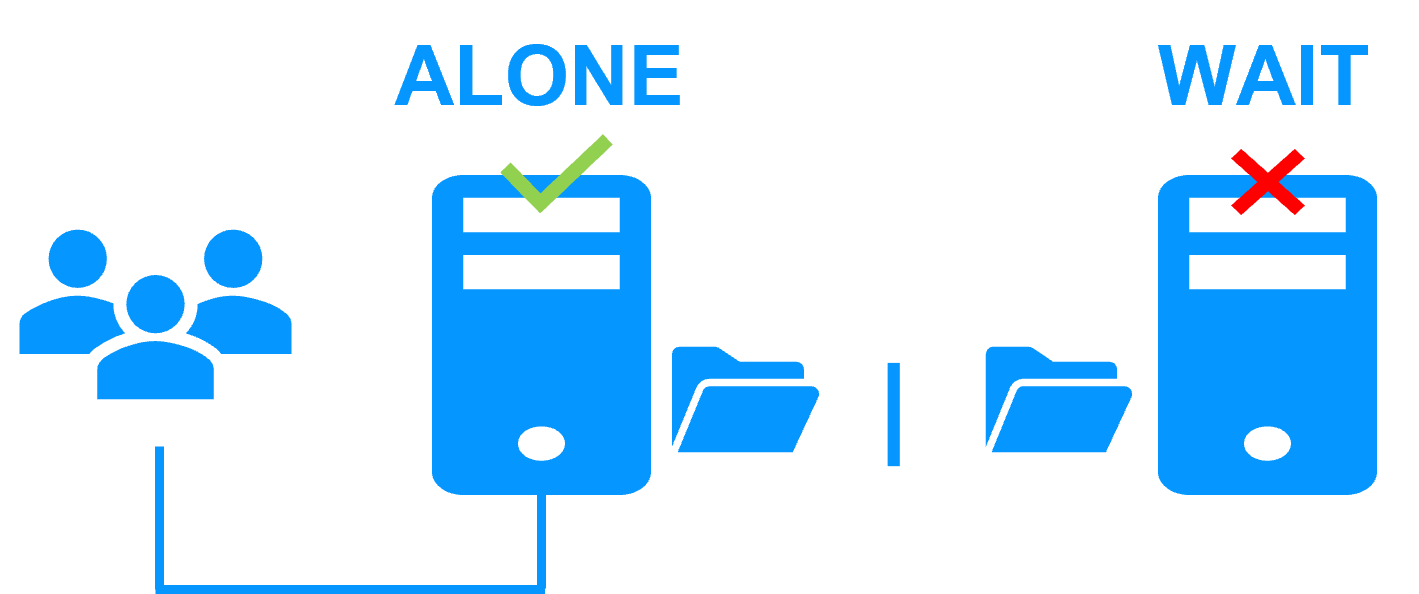
Lorsqu'il y a un isolement du réseau, le comportement avec un split-brain checker est :
- un split-brain checker a été configuré avec l'adresse IP d'un témoin (typiquement un routeur),
- le split-brain agit lorsqu'un serveur passe de PRIM à ALONE ou de SECOND à ALONE,
- en cas d'isolement du réseau, avant de passer en ALONE, les deux nœuds testent l'adresse IP,
- le nœud qui peut accéder à l'adresse IP passe à ALONE, l'autre passe à WAIT,
- lorsque l'isolement est réparé, le nœud WAIT resynchronise ses données et devient SECOND.
Remarque : Si le témoin est en panne ou déconnecté, les deux nœuds passent à WAIT et l'application n'est plus en cours d'exécution. C'est pourquoi vous devez choisir un témoin robuste comme un routeur.
Qu'est-ce qu'un heartbeat ?
Le mécanisme de base pour synchroniser deux serveurs et détecter les pannes de serveur est le heartbeat, qui est un flux de données de surveillance sur un réseau partagé par une paire de serveurs.
Le logiciel SafeKit supporte autant de heartbeats qu'il y a de réseaux partagés par les deux serveurs.
Le mécanisme de heartbeat est utilisé pour implémenter des clusters Windows et Linux. Il est intégré au cluster miroir de SafeKit avec réplication de fichiers en temps réel et basculement.
Heartbeats de SafeKit
En fonctionnement normal, les deux serveurs échangent leurs états (PRIM, SECOND, les états des ressources) via les canaux de heartbeat et synchronisent leurs procédures de démarrage et d'arrêt des applications.
En particulier, en cas de basculement programmé, le script d'arrêt qui stoppe l'application est d'abord exécuté sur le serveur primaire, avant d'exécuter le script de démarrage sur le serveur secondaire. Ainsi, les données répliquées sur le serveur secondaire sont dans un état sûr correspondant à un arrêt propre de l'application.
Perte de tous les heartbeats
Lorsque tous les heartbeats sont perdus sur un serveur, ce serveur considère que l'autre serveur est en panne et passe à l'état ALONE.
Si c'est le serveur SECOND qui passe à l'état ALONE, alors il y a basculement de l'application avec redémarrage de l'application sur le serveur secondaire.
Bien que non obligatoire, il est préférable d'avoir deux canaux de heartbeat sur deux réseaux différents pour synchroniser les deux serveurs afin de séparer le cas de la panne réseau de celui de la panne serveur.

Salles informatiques distantes
Un cluster de haute disponibilité sécurisant une application critique peut être mis en place avec deux serveurs dans deux salles informatiques géographiquement distantes.
Ainsi, la solution prend en charge le sinistre d'une salle complète.
Split brain
En cas d'isolation réseau entre les deux salles informatiques, tous les heartbeats sont perdus et le problème du split brain se pose.
Les deux serveurs démarrent l'application critique.
Complexité des solutions
Le plus souvent, pour résoudre le split brain, le quorum est implémenté avec un troisième serveur de quorum ou un disque de quorum spécial pour éviter les doubles maîtres.
Malheureusement, ces nouveaux dispositifs de quorum ajoutent des coûts et de la complexité à l'architecture de clustering globale.
Split brain checker de SafeKit
Avec le logiciel de haute disponibilité SafeKit, le quorum au sein d'un cluster Windows ou Linux ne nécessite pas de troisième serveur de quorum ni de disque quorum. Un split brain checker simple est suffisant pour éviter la double exécution d'une application.
En cas de perte de tous les heartbeats entre les serveurs, le split brain checker sélectionne un seul serveur pour devenir le serveur primaire. L'autre serveur passe à l'état WAIT jusqu'à ce qu'il reçoive à nouveau les heartbeats. Il repasse alors en secondaire après avoir resynchronisé les données répliquées du serveur primaire.
Comment fonctionne le split brain checker ?
L'élection du serveur primaire est basée sur le ping d'une adresse IP, appelée témoin. Le témoin est généralement un routeur toujours disponible. En cas d'isolation réseau, seul le serveur ayant accès au témoin sera primaire et passera ALONE, l'autre ira en WAIT.
Le témoin n'est pas testé en permanence mais seulement lorsque tous les heartbeats sont perdus. Si à ce moment-là, le témoin est en panne, le cluster passe à l'état WAIT-WAIT et un administrateur peut choisir de redémarrer l'un des serveurs en tant que serveur primaire via la console Web de SafeKit.
Que se passe-t-il sans split brain checker ?
En cas d'isolation réseau, les deux serveurs passeront à l'état ALONE exécutant l'application critique. Les répertoires répliqués sont isolés et chaque application travaille sur ses propres données dans son propre répertoire.
A la reconnexion du réseau, SafeKit choisit par défaut le serveur qui était PRIM avant l'isolation comme nouveau primaire et force l'autre serveur en SECOND avec une resynchronisation de toutes ses données depuis le serveur PRIM.
Remarque : Windows peut détecter une adresse IP en double sur un serveur et supprimer l'adresse IP virtuelle sur ce serveur. SafeKit dispose d'un checker pour forcer un redémarrage dans ce cas.
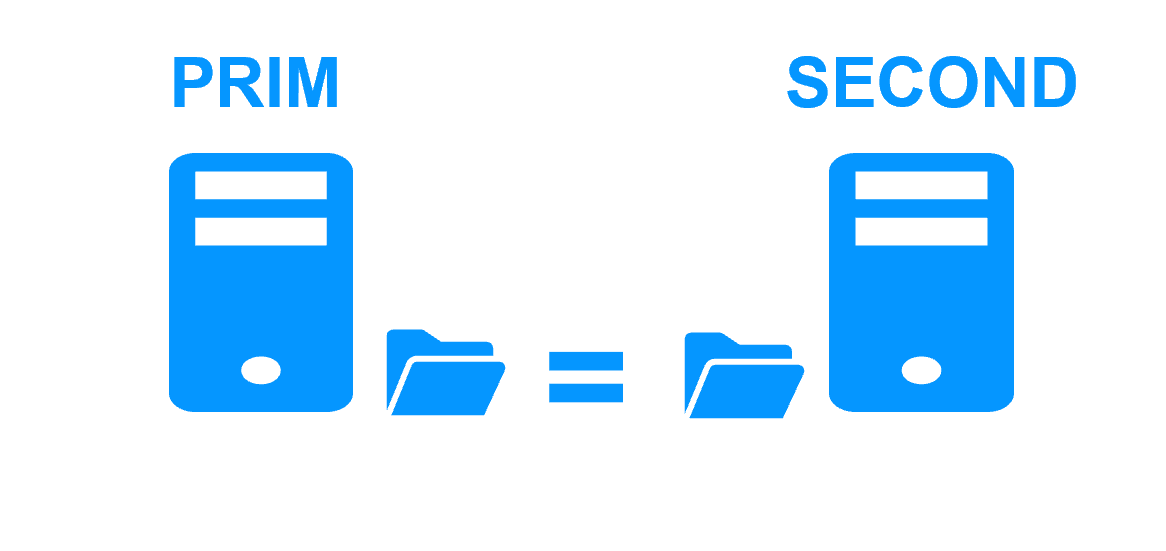
Etape 1. Réplication en temps réel
Le serveur 1 (PRIM) exécute l'application. Les utilisateurs sont connectés à une adresse IP virtuelle. Seules les modifications faites par l'application à l'intérieur des fichiers sont répliquées en continue à travers le réseau.
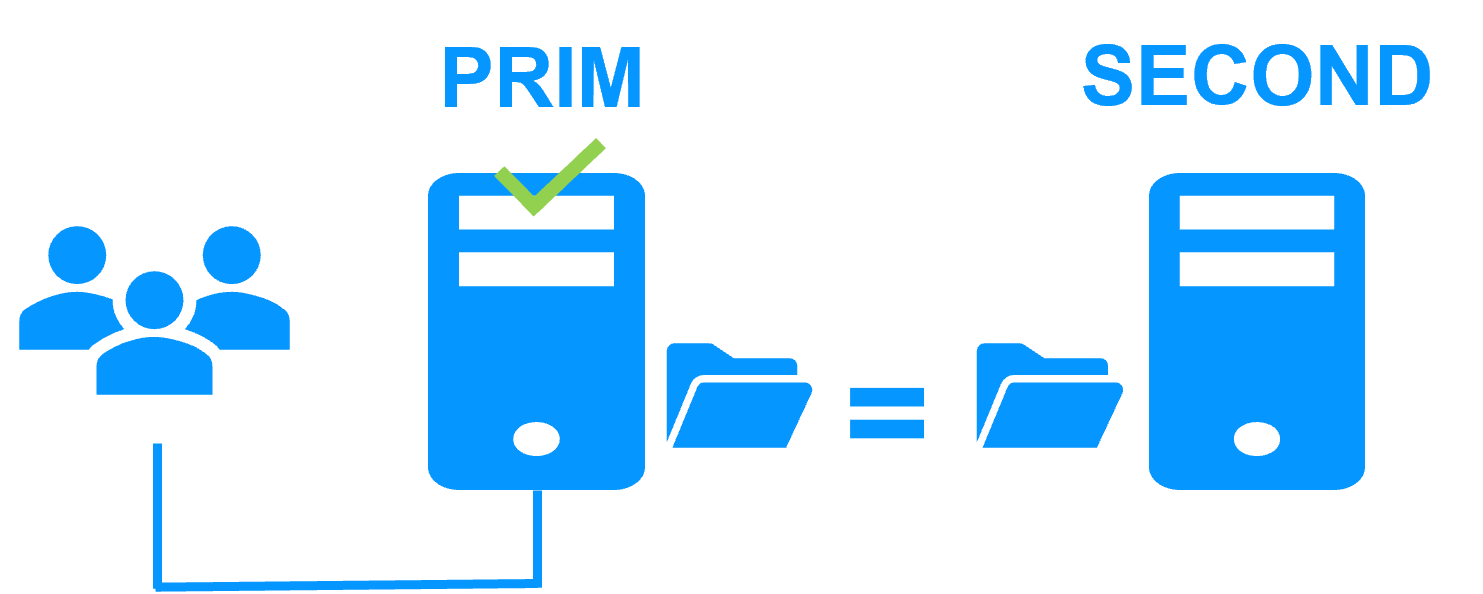
La réplication est synchrone sans perte de données en cas de panne contrairement à une réplication asynchrone.
Il vous suffit de configurer les noms des répertoires à répliquer dans SafeKit. Il n'y a pas de pré-requis sur l'organisation du disque. Les répertoires peuvent se trouver sur le disque système.
Etape 2. Basculement automatique
Lorsque le serveur 1 est défaillant, SafeKit bascule l'adresse IP virtuelle sur le serveur 2 et redémarre automatiquement l'application. L'application retrouve les fichiers répliqués à jour sur le serveur 2.
L'application poursuit son exécution sur le serveur 2 en modifiant localement ses fichiers qui ne sont plus répliqués vers le serveur 1.
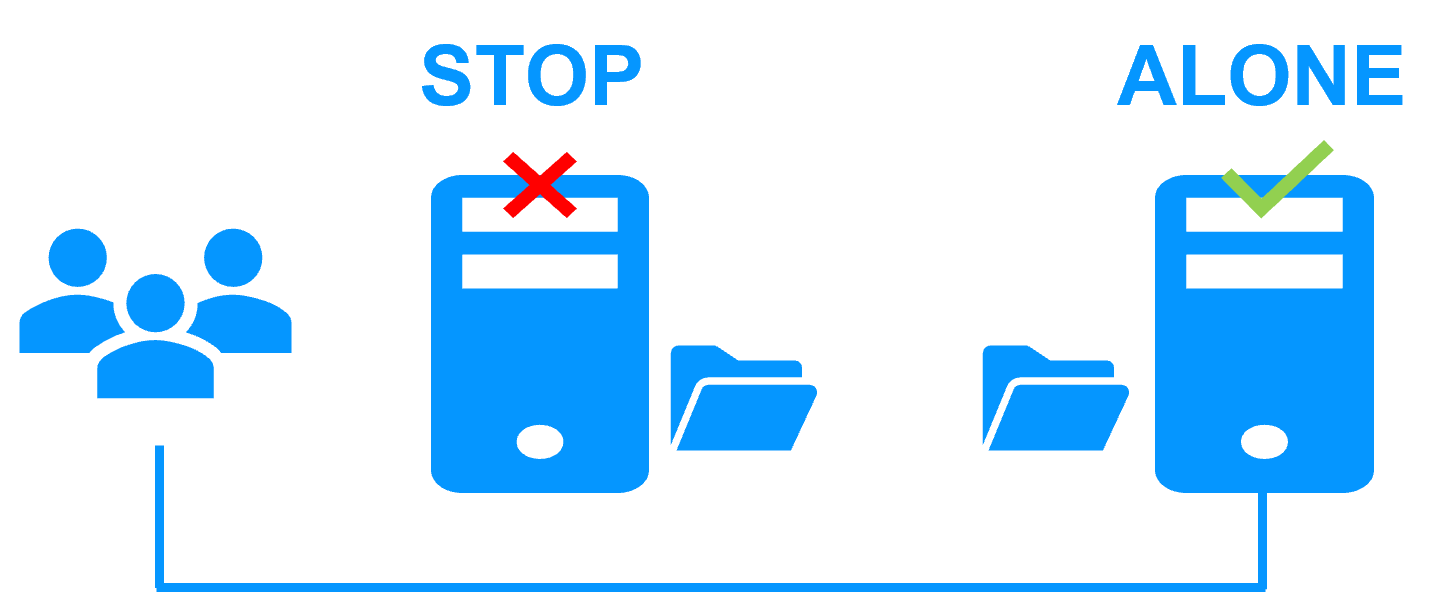
Le temps de basculement est égal au temps de détection de la panne (30 secondes par défaut) et au temps de relance de l'application.
Etape 3. Réintégration après panne
A la reprise après panne du serveur 1 (réintégration du serveur 1), SafeKit resynchronise automatiquement les fichiers de ce serveur à partir de l'autre serveur.
Seuls les fichiers modifiés sur le serveur 2 pendant l'inactivité du serveur 1 sont resynchronisés.
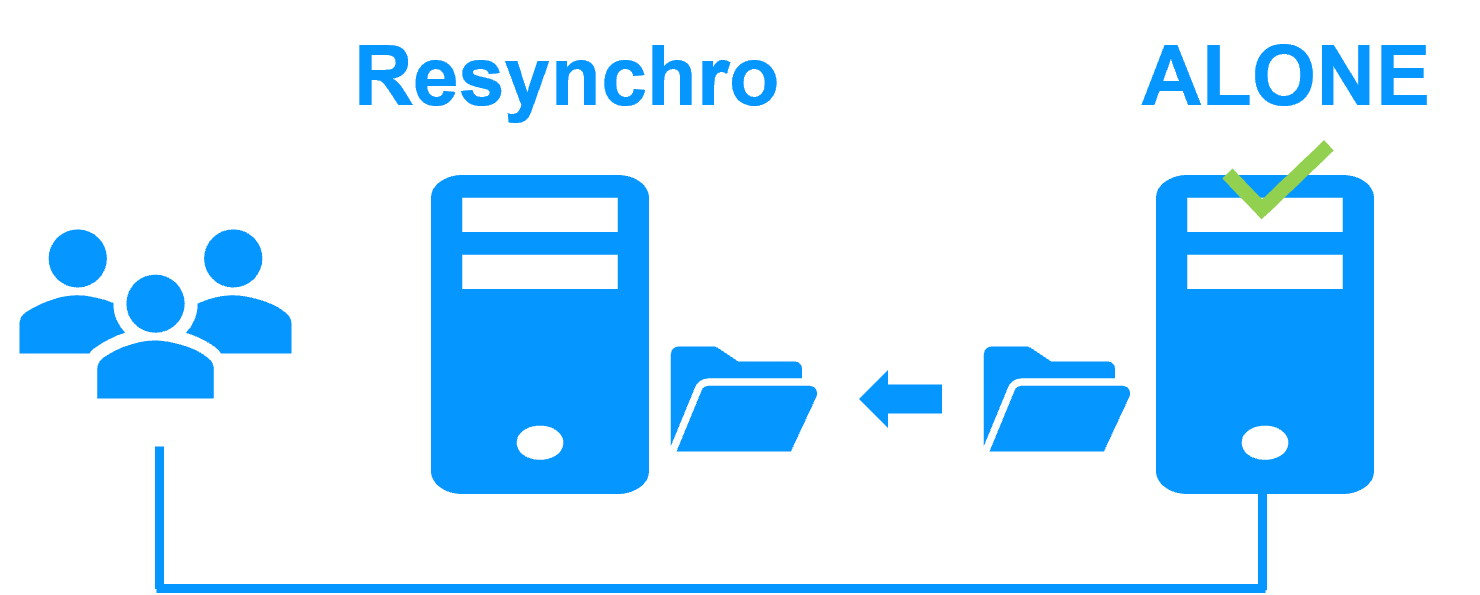
La réintégration du serveur 1 se fait sans arrêter l'exécution de l'application sur le serveur 2.
Etape 4. Retour à la normale
Après la réintégration, les fichiers sont à nouveau en mode miroir comme à l'étape 1. Le système est en haute disponibilité avec l'application qui s'exécute sur le serveur 2 et avec réplication temps réel des modifications vers le serveur 1.
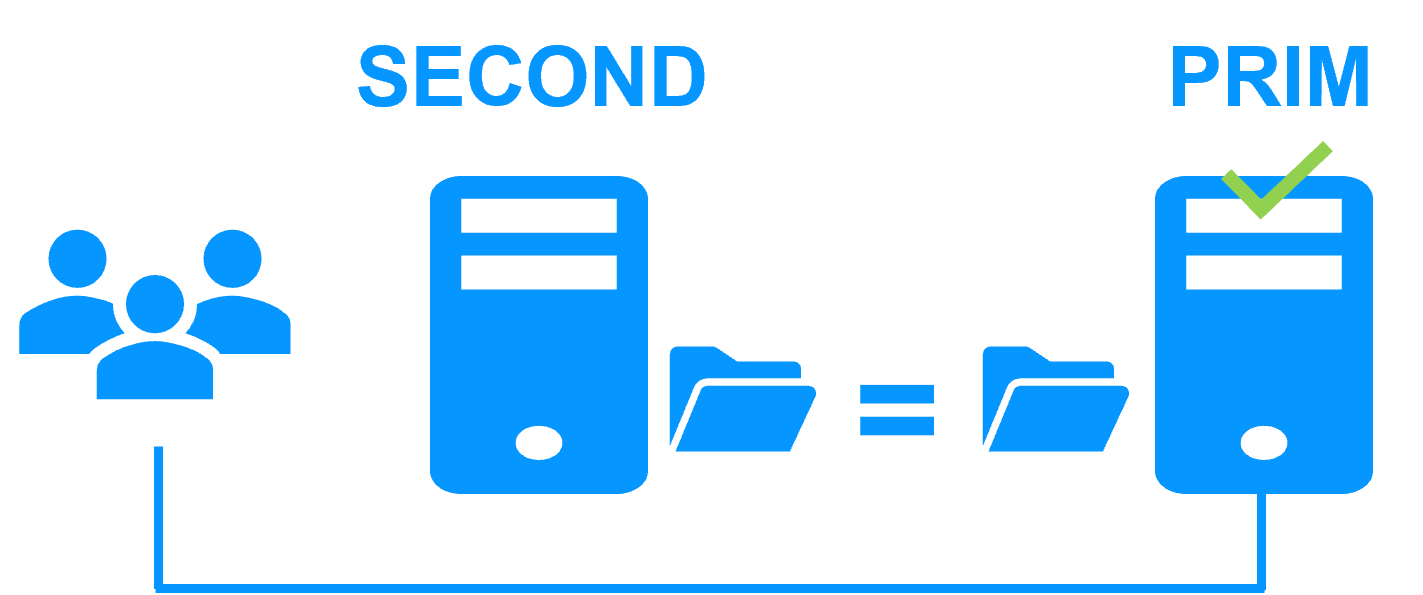
Si l'administrateur souhaite que son application s'exécute en priorité sur le serveur 1, il peut exécuter une commande de basculement, soit manuellement à un moment opportun, soit automatiquement par configuration.
Plus d'information sur une coupure de courant et un isolement du réseau dans un cluster.
Pourquoi une réplication de quelques Tera-octets ?
Temps de resynchronisation après panne (étape 3)
- Réseau 1 Gb/s ≈ 3 heures pour 1 téraoctet.
- Réseau 10 Gb/s ≈ 1 heure pour 1 téraoctet ou moins en fonction des performances d'écriture disque.
Alternative
- Pour un grand volume de données, utilisez un stockage partagé externe.
- Plus cher, plus complexe.
Pourquoi une réplication < 1 000 000 fichiers ?
- Performance du temps de resynchronisation après panne (étape 3).
- Temps pour vérifier chaque fichier entre les deux nœuds.
Alternative
- Placez les nombreux fichiers à répliquer sur un disque dur virtuel / une machine virtuelle.
- Seuls les fichiers représentant le disque dur virtuel / la machine virtuelle seront répliqués et resynchronisés dans ce cas.
Pourquoi un basculement ≤ 32 VMs répliquées ?
- Chaque VM s'exécute dans un module miroir indépendant.
- Maximum de 32 modules miroir exécutés sur le même cluster.
Alternative
- Utilisez un stockage partagé externe et une autre solution de clustering de VMs.
- Plus cher, plus complexe.
Pourquoi un réseau LAN/VLAN entre sites distants ?
- Basculement automatique de l'adresse IP virtuelle avec 2 nœuds dans le même sous-réseau.
- Bonne bande passante pour la resynchronisation (étape 3) et bonne latence pour la réplication synchrone (typiquement un aller-retour de moins de 2 ms).
Alternative
- Utilisez un équilibreur de charge pour l'adresse IP virtuelle si les 2 nœuds sont dans 2 sous-réseaux (supporté par SafeKit, notamment dans le cloud).
- Utilisez des solutions de backup avec réplication asynchrone pour un réseau à latence élevée.
| HA de VMs avec le module Hyper-V ou KVM de SafeKit | HA d'application avec les modules applicatifs de SafeKit |
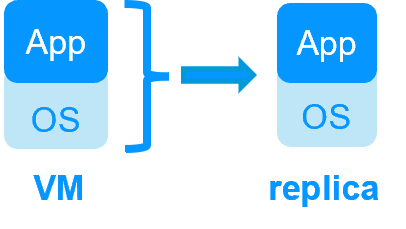
SafeKit dans 2 hyperviseurs: réplication et reprise de VM complète |
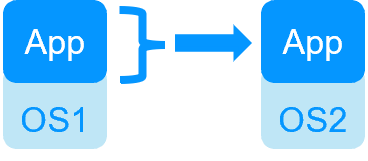
SafeKit dans 2 machines virtuelles ou physiques: réplication et reprise au niveau applicatif |
| Réplique plus de données (App+OS) | Réplique seulement les données applicatives |
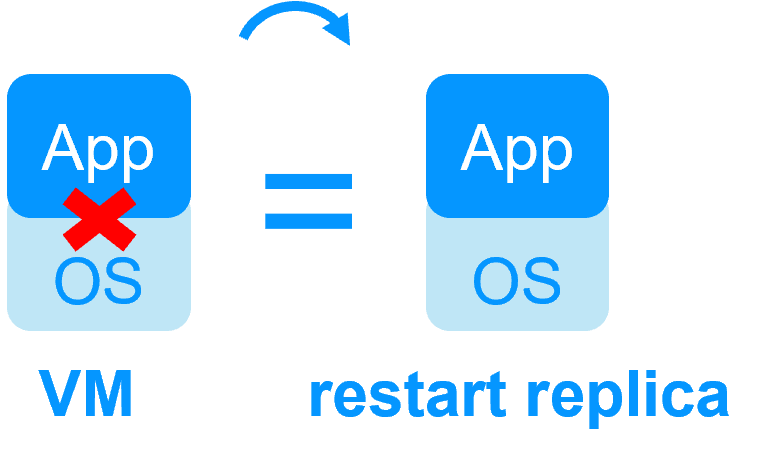
| Reboot de la machine virtuelle sur l'hyperviseur 2 si l'hyperviseur 1 crash Temps de reprise dépendant du reboot de l'OS Checker de VM et reprise sur panne (la machine virtuelle ne répond pas, est tombée en panne ou a cessé de fonctionner) |
Temps de reprise rapide avec redémarrage de l'application sur OS2 en cas de panne du serveur 1 Autour d'1 mn ou moins (voir RTO/RPO ici) Checker applicatif et reprise sur panne logicielle |
| Solution générique pour n'importe quelle application / OS | Scripts de redémarrage à écrire dans des modules applicatifs |
| Fonctionne avec Windows/Hyper-V et Linux/KVM mais pas avec VMware | Indépendant de la plateforme, fonctionne avec les machines physiques ou virtuelles, une infrastructure cloud et tout hyperviseur, y compris VMware |
| SafeKit avec le module Hyper-V ou le module KVM | Microsoft Hyper-V Cluster & VMware HA |
 |
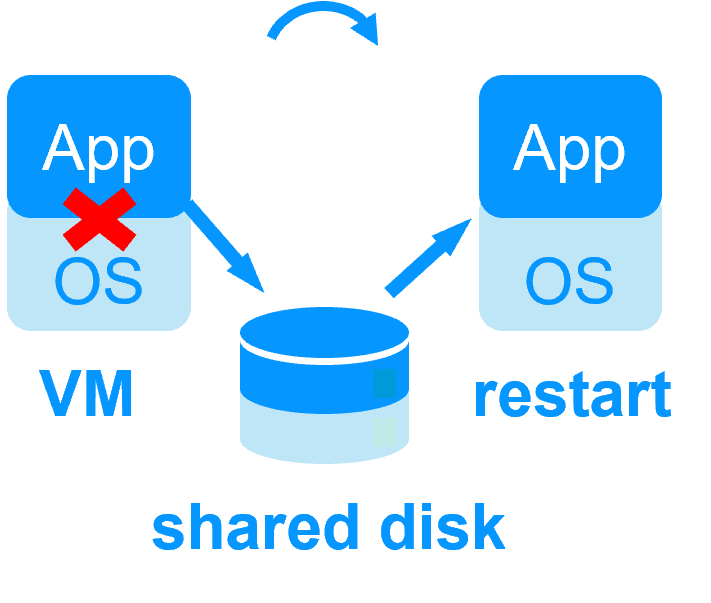 |
 Pas de disque partagé - réplication temps réel synchrone à la place avec 0 perte de données Pas de disque partagé - réplication temps réel synchrone à la place avec 0 perte de données |
 Disque partagé et baie de disques externe spécifique Disque partagé et baie de disques externe spécifique |
| Sites distants = pas de SAN pour la réplication |
Sites distants = baies de disques répliquées à travers un SAN |
| Aucune compétence informatique spécifique pour configurer le système (avec hyperv.safe et kvm.safe) |
Compétence informatique spécifique pour configurer le système |
| Notez que les solutions Hyper-V/SafeKit et KVM/SafeKit sont limitées à la réplication et au basculement de 32 machines virtuelles. | Notez que la réplication intégrée à Hyper-V ne peut pas être considérée comme une solution de haute disponibilité. En effet, la réplication est asynchrone, ce qui peut entraîner une perte de données en cas de panne, et elle ne dispose pas de fonctionnalités de basculement et de restauration automatiques. |
Cluster miroir d'Evidian SafeKit avec réplication de fichiers temps réel et reprise sur panne |
|
Économisez avec 3 produits en 1
En savoir plus >
 |
|
Configuration très simple
En savoir plus >
 |
|
Réplication synchrone
En savoir plus >
 |
|
Retour d'un serveur tombé en panne totalement automatisé (failback)
En savoir plus >
 |
|
Réplication de n'importe quel type de données
En savoir plus >
 |
|
Réplication de fichiers vs réplication de disque
En savoir plus >
 |
|
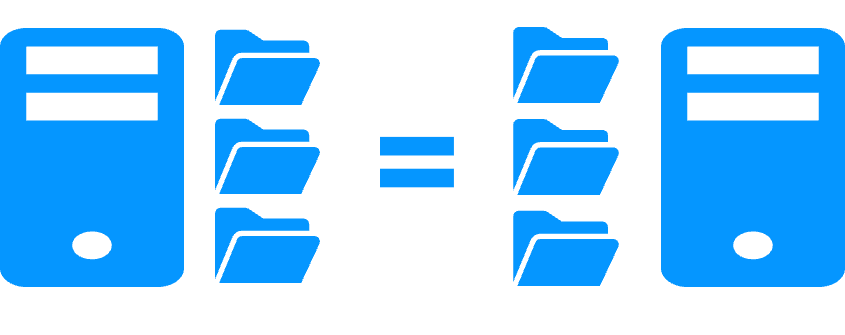
Réplication de fichiers vs disque partagé
En savoir plus >
 |
|
Sites distants et adresse IP virtuelle
En savoir plus >
 |
|
|
Split brain et quorum
En savoir plus >
|
|
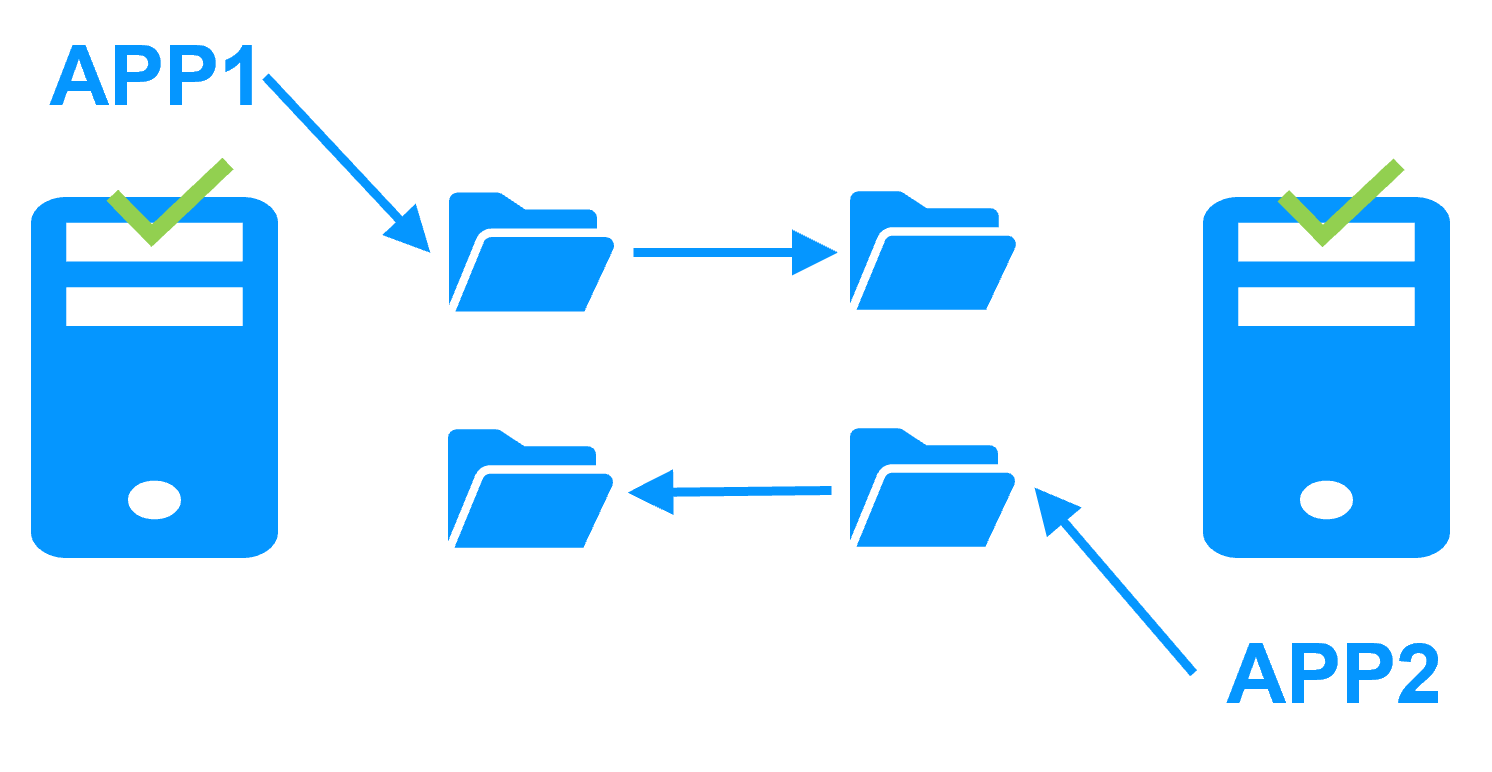
Cluster actif/actif
En savoir plus >
 |
|
Solution de haute disponibilité uniforme
En savoir plus >
 |
|
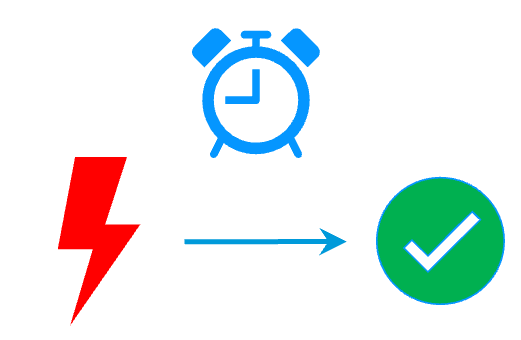
RTO / RPO
En savoir plus >
 |
|
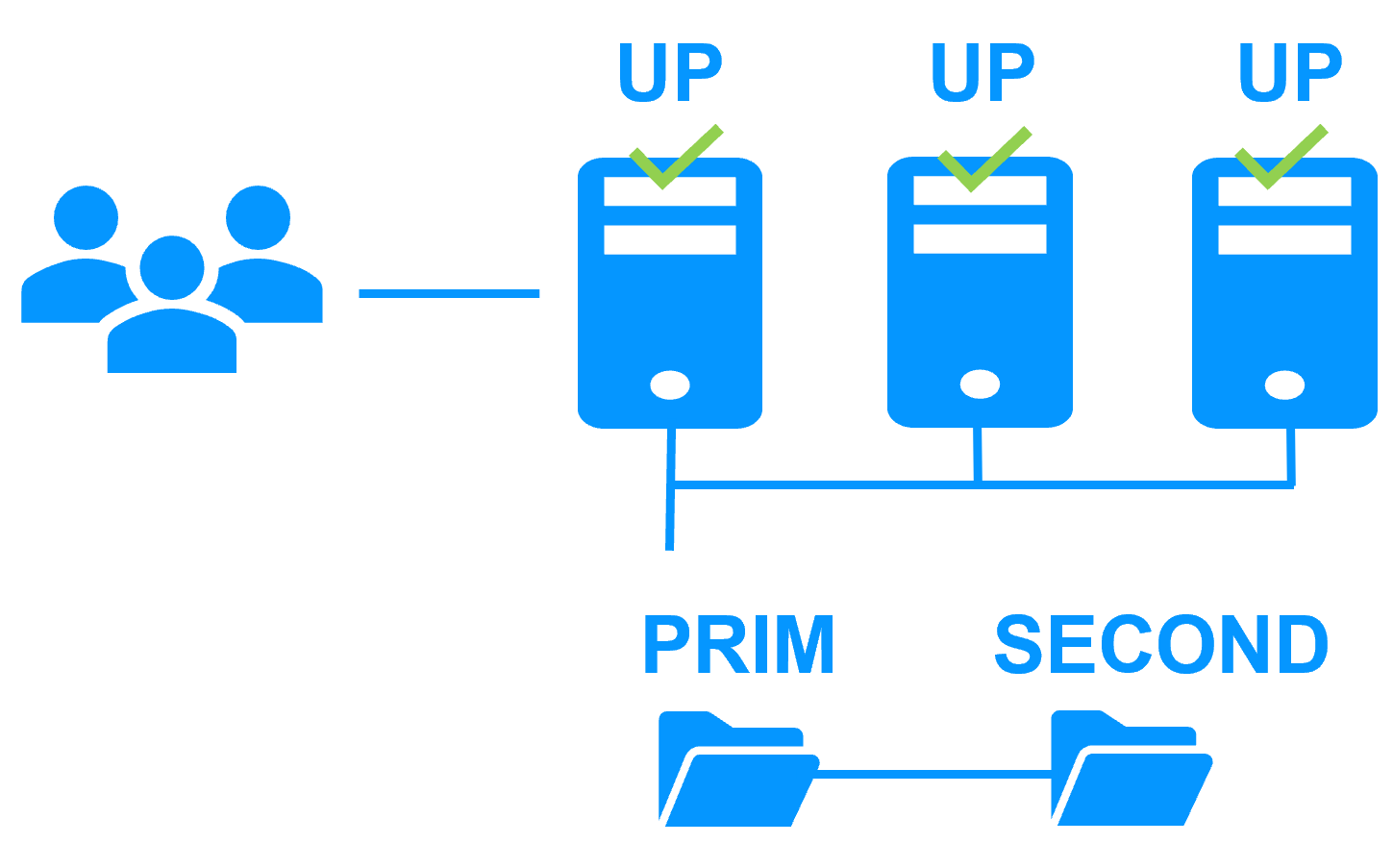
Cluster ferme d'Evidian SafeKit avec load balancing et reprise sur panne |
|
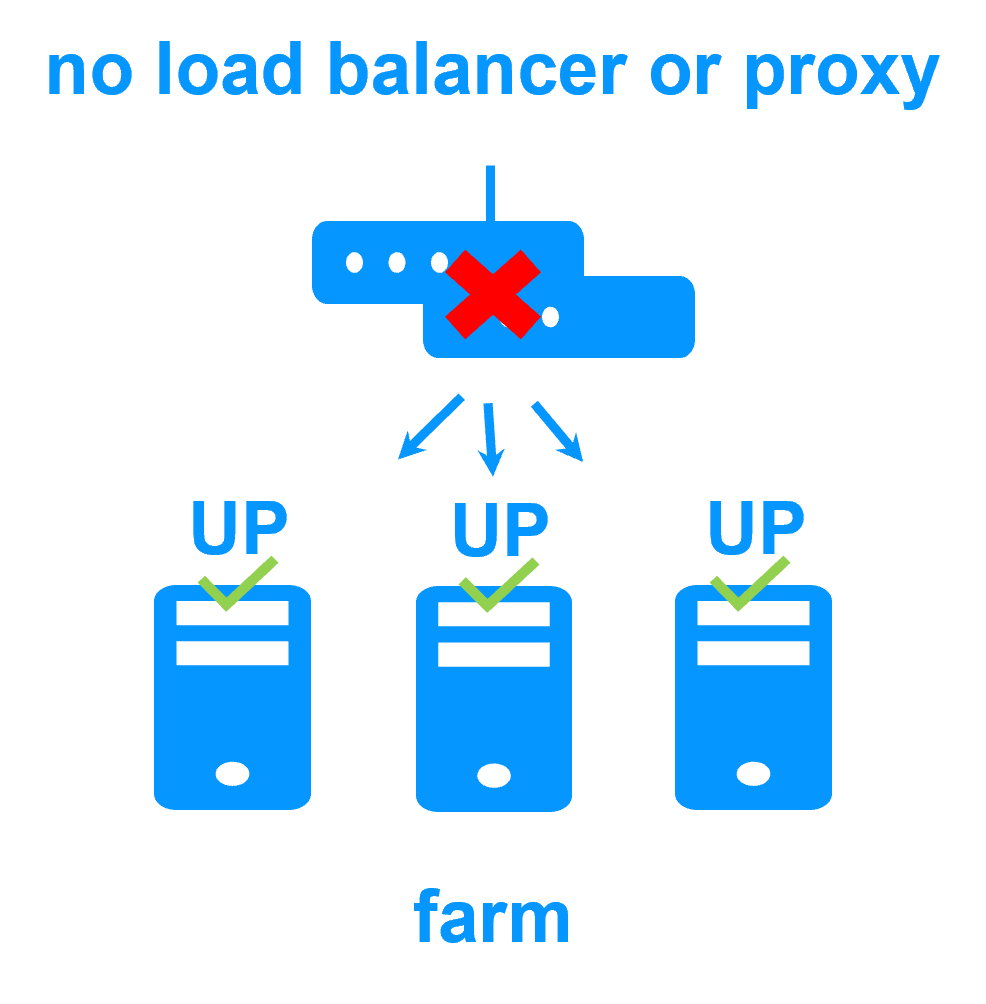
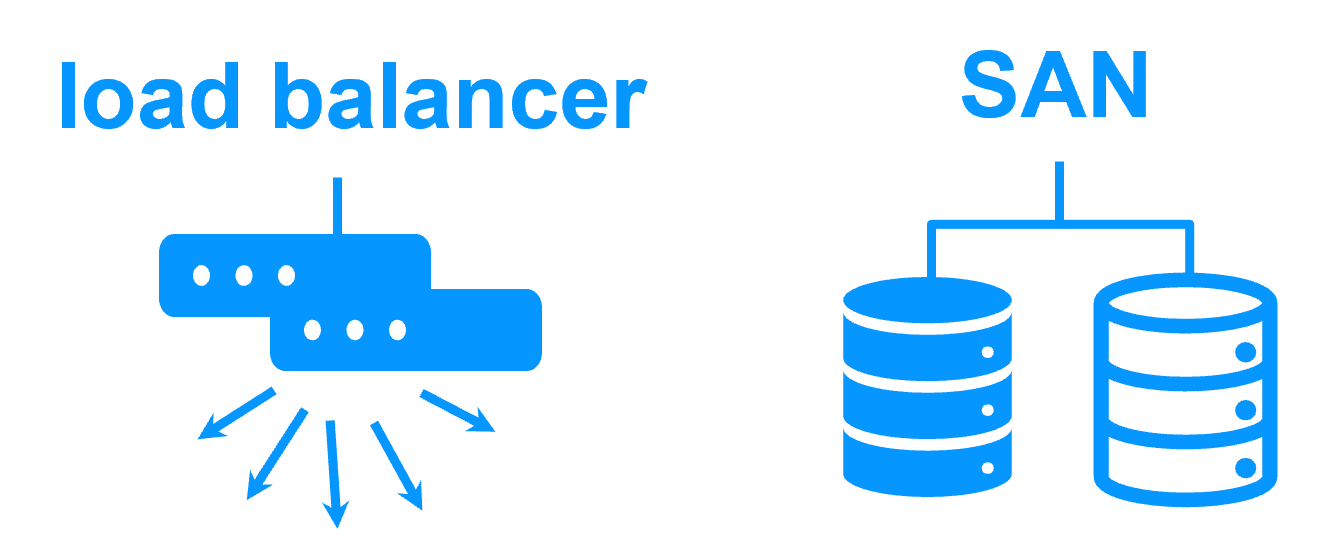
Pas de load balancer, ni de serveur proxy dédié, ni d'adresse Ethernet multicast spéciale
En savoir plus >
 |
|
|
Toutes les fonctionnalités de clustering
En savoir plus >
|
|
|
Sites distants et adresse IP virtuelle
En savoir plus >
|
|
|
Solution de haute disponibilité uniforme
En savoir plus >
|
|
|
|
|
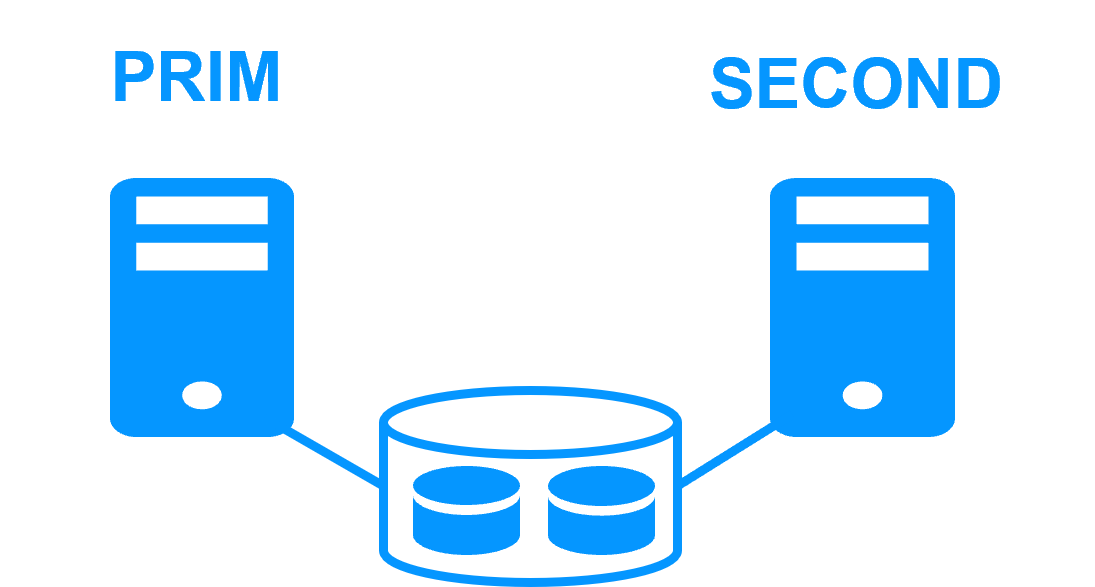
Cluster de type "shared nothing"" vs cluster à disque partagé En savoir plus > |
|
|
|
|
|
|
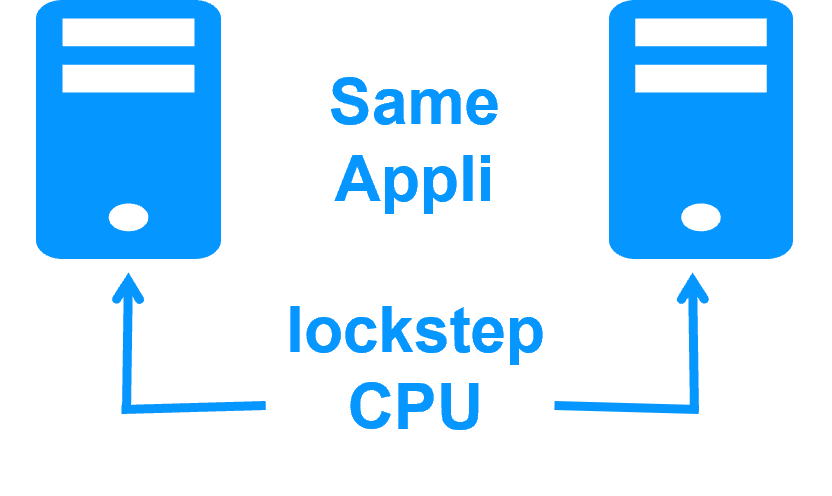
Haute disponibilité vs tolérance aux fautes En savoir plus > |
|
|
|
|
Réplication synchrone vs réplication asynchrone En savoir plus > |
|
|

|
|
Réplication de fichiers au niveau octet vs réplication de disque au niveau du bloc En savoir plus > |
|
|
|
|
Heartbeat, reprise sur panne et quorum pour éviter 2 serveurs maîtres En savoir plus > |
|
|
|
|
|

|
Nouvelle application (réplication en temps réel et basculement)
- Windows (mirror.safe)
- Linux (mirror.safe)
Nouvelle application (répartition de charge réseau et basculement)
Base de données (réplication en temps réel et basculement)
- Microsoft SQL Server (sqlserver.safe)
- PostgreSQL (postgresql.safe)
- MySQL (mysql.safe)
- Oracle (oracle.safe)
- MariaDB (sqlserver.safe)
- Firebird (firebird.safe)
Web (répartition de charge réseau et basculement)
- Apache (apache_farm.safe)
- IIS (iis_farm.safe)
- NGINX (farm.safe)
Réplication en temps réel et basculement de VM ou de conteneur complet
- Hyper-V (hyperv.safe)
- KVM (kvm.safe)
- Docker (mirror.safe)
- Podman (mirror.safe)
- Kubernetes K3S (k3s.safe)
Amazon AWS
- AWS (mirror.safe)
- AWS (farm.safe)
Google GCP
- GCP (mirror.safe)
- GCP (farm.safe)
Microsoft Azure
- Azure (mirror.safe)
- Azure (farm.safe)
Autres clouds
- Toutes les solutions Cloud
- Générique (mirror.safe)
- Générique (farm.safe)
Sécurité physique (réplication en temps réel et basculement)
- Milestone XProtect (milestone.safe)
- Nedap AEOS (nedap.safe)
- Genetec SQL Server (sqlserver.safe)
- Bosch AMS (hyperv.safe)
- Bosch BIS (hyperv.safe)
- Bosch BVMS (hyperv.safe)
- Hanwha Vision (hyperv.safe)
- Hanwha Wisenet (hyperv.safe)
Siemens (réplication en temps réel et basculement)
- Siemens Siveillance suite (hyperv.safe)
- Siemens Desigo CC (hyperv.safe)
- Siemens Siveillance VMS (SiveillanceVMS.safe)
- Siemens SiPass (hyperv.safe)
- Siemens SIPORT (hyperv.safe)
- Siemens SIMATIC PCS 7 (hyperv.safe)
- Siemens SIMATIC WinCC (hyperv.safe)