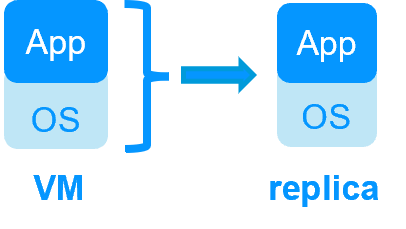
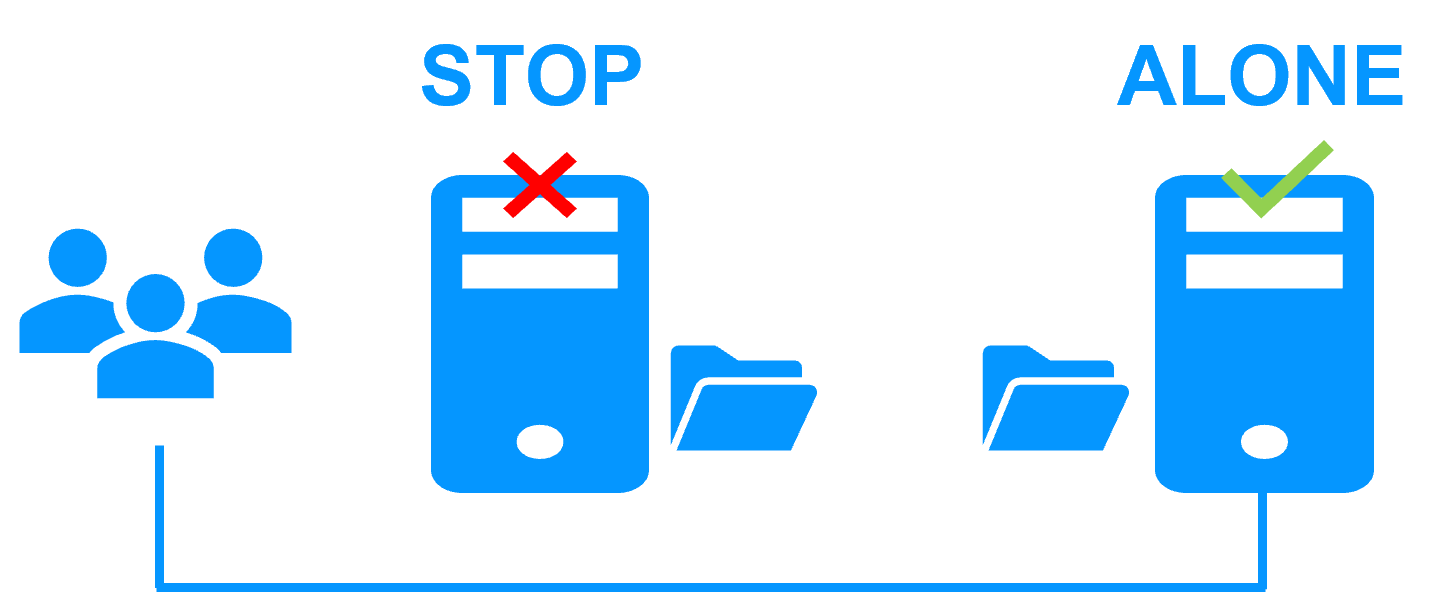
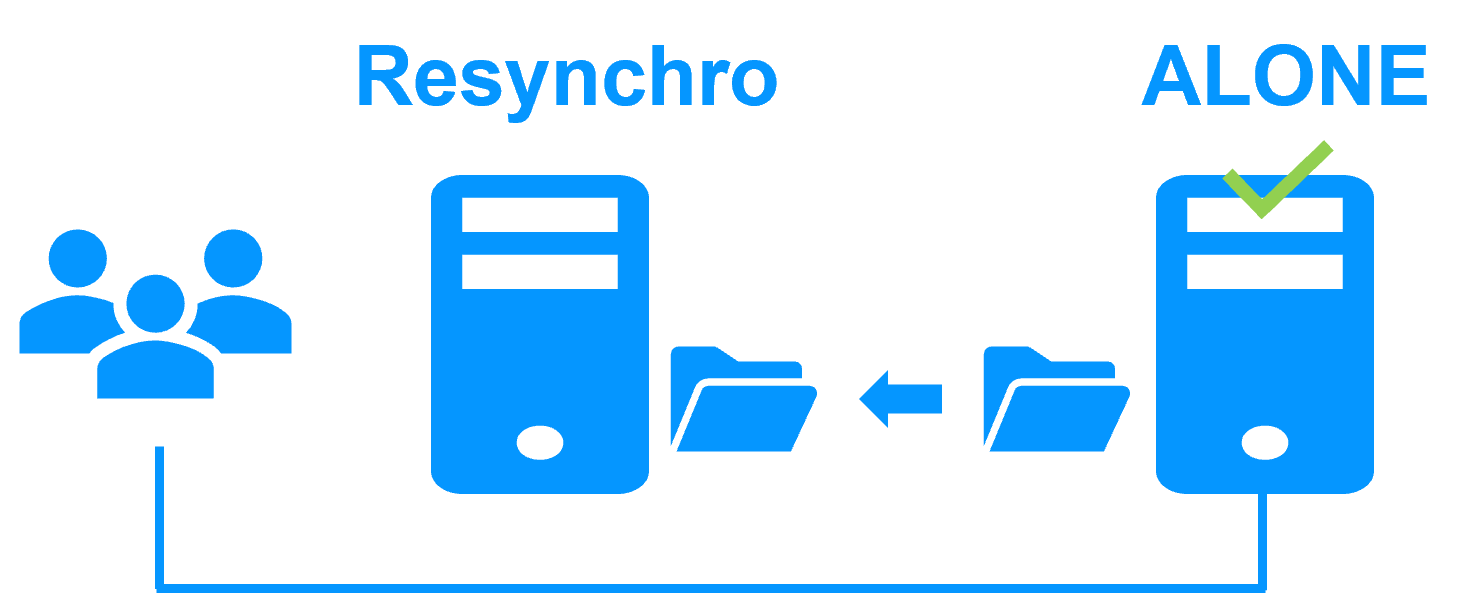
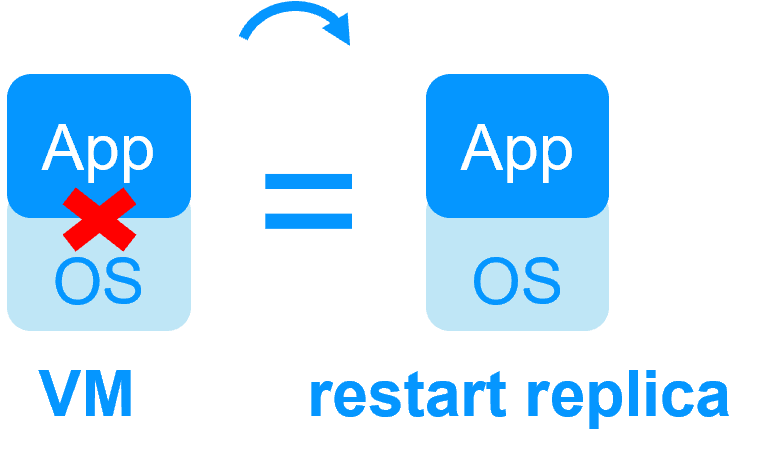
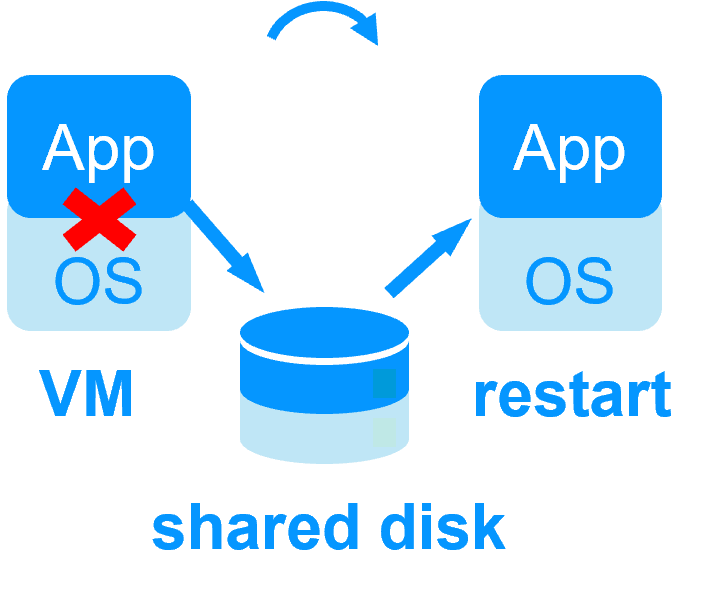
| Nuevas Aplicaciones |
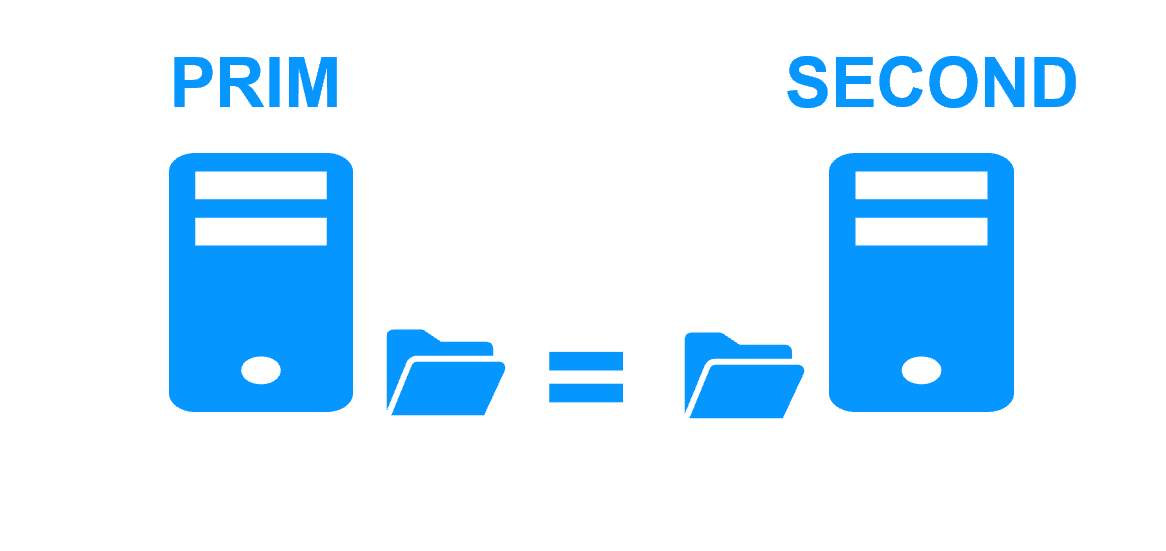
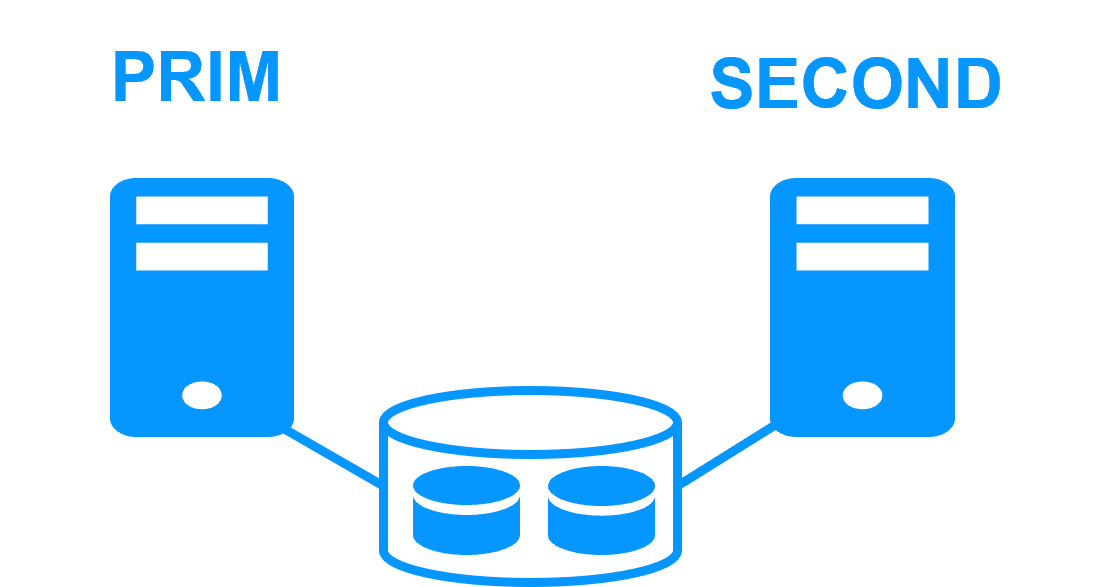
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo en Windows |
Guía de instalación de mirror.safe para Windows |
| Nuevas Aplicaciones |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo en Linux |
Guía de instalación de mirror.safe para Linux |
| Nuevas Aplicaciones |
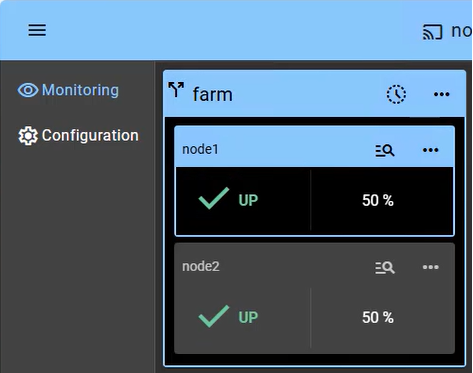
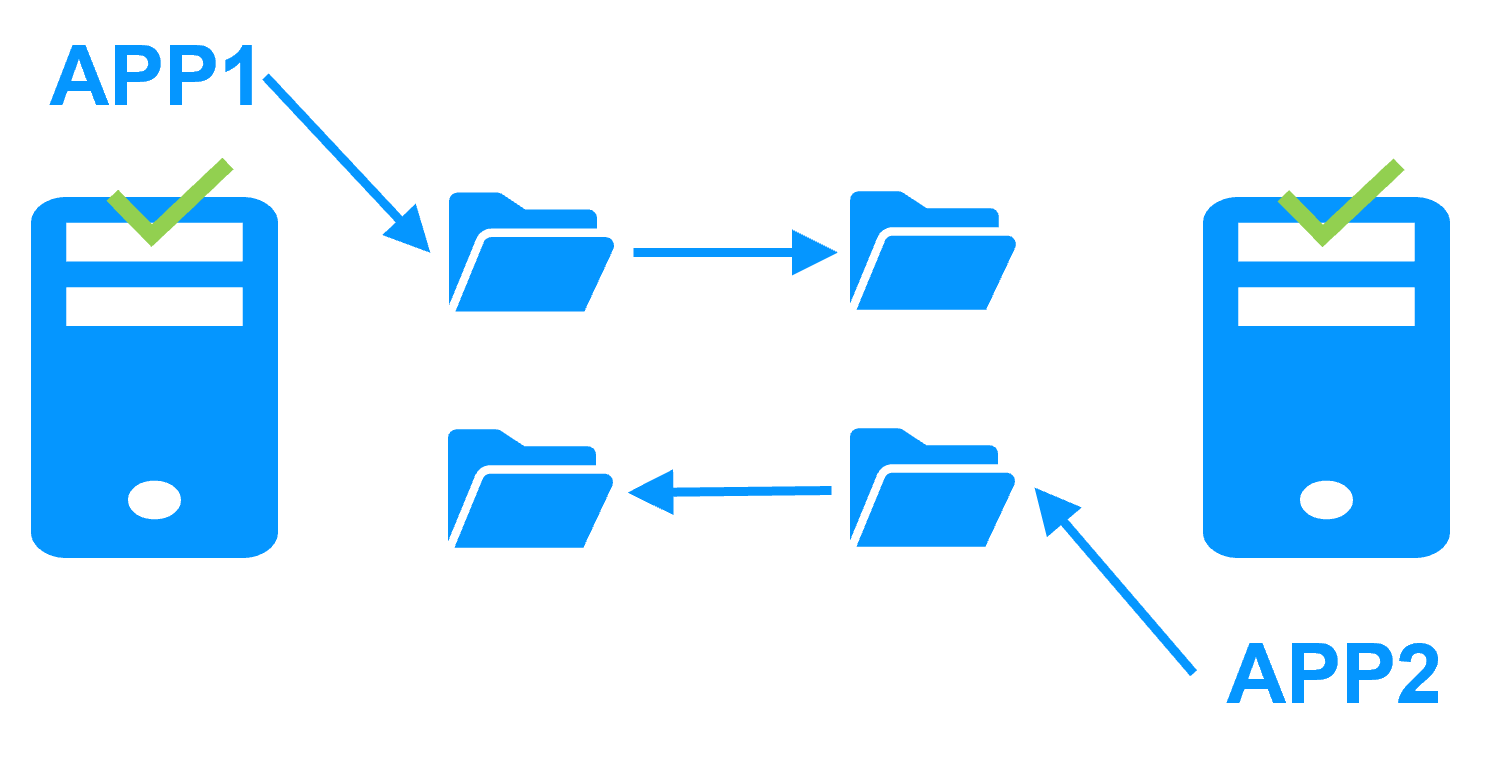
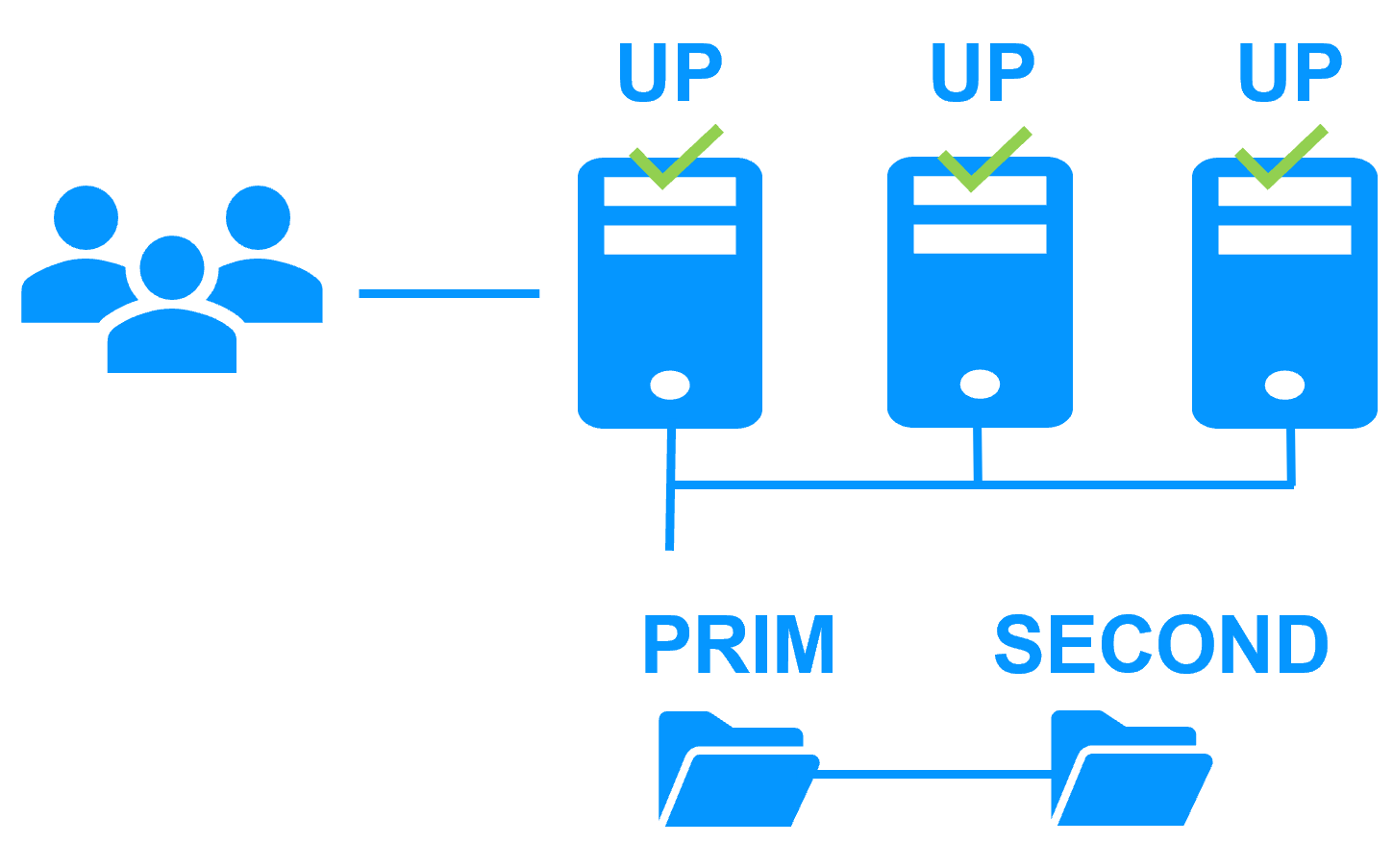
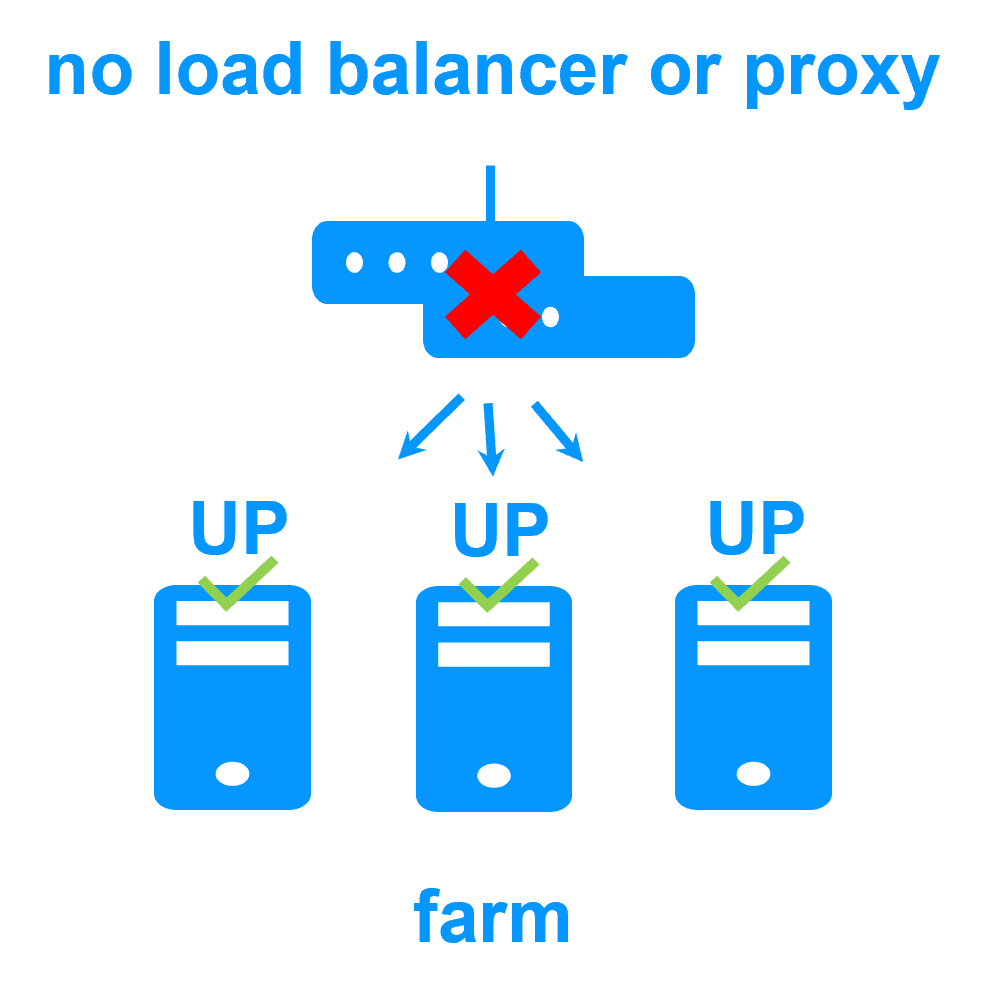
Equilibrio de Carga de Red y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga en Windows |
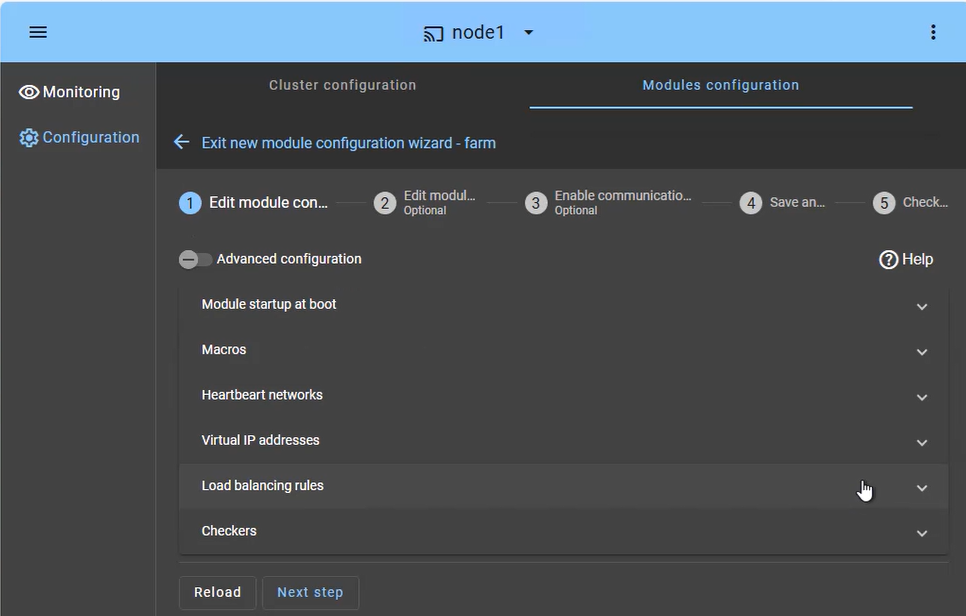
Guía de instalación de farm.safe para Windows |
| Nuevas Aplicaciones |
Equilibrio de Carga de Red y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga en Linux |
Guía de instalación de farm.safe para Linux |
| Bases de Datos |
Replicación y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de Microsoft SQL Server |
Guía de instalación de sqlserver.safe para Microsoft SQL Server |
| Bases de Datos |
Replicación y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de PostgreSQL |
Guía de instalación de postgresql.safe para PostgreSQL |
| Bases de Datos |
Replicación y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de MySQL |
Guía de instalación de mysql.safe para MySQL |
| Bases de Datos |
Replicación y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de MariaDB |
Guía de instalación de mysql.safe para MariaDB |
| Bases de Datos |
Replicación y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de Oracle |
Guía de instalación de oracle.safe para Oracle |
| Bases de Datos |
Replicación y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de Firebird |
Guía de instalación de firebird.safe para Firebird |
| Servidores Web |
Equilibrio de Carga y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga de Apache |
Guía de instalación de apache_farm.safe para Apache |
| Servidores Web |
Equilibrio de Carga y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga de IIS |
Guía de instalación de iis_farm.safe para IIS |
| Servidores Web |
Equilibrio de Carga y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga de NGINX |
Guía de instalación de farm.safe para NGINX |
| VMs y Contenedores |
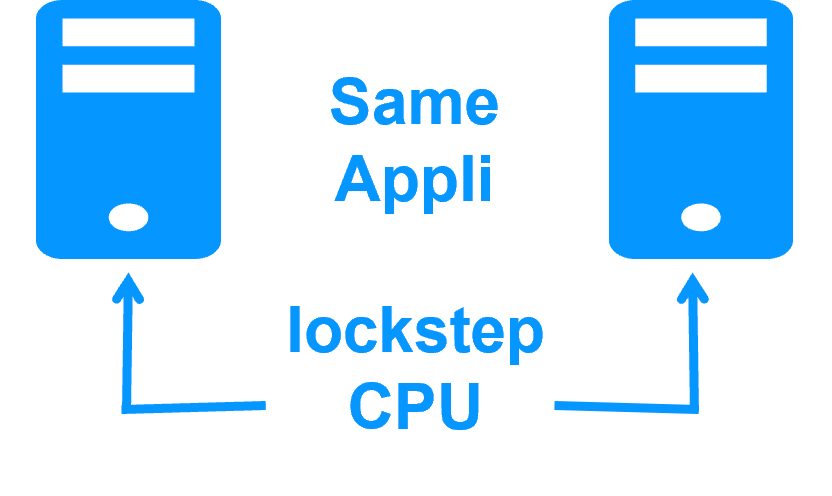
Replicación y Failover de VMs |
Arquitectura de HA para VM Hyper-V |
Guía de instalación de hyperv.safe para Hyper-V |
| VMs y Contenedores |
Replicación y Failover de VMs |
Arquitectura de HA para VM KVM |
Guía de instalación de kvm.safe para KVM |
| VMs y Contenedores |
Replicación y Failover de Aplicaciones |
Arquitectura de HA para Contenedores Docker |
Guía de instalación de mirror.safe para Docker |
| VMs y Contenedores |
Replicación y Failover de Aplicaciones |
Arquitectura de HA para Contenedores Podman |
Guía de instalación de mirror.safe para Podman |
| VMs y Contenedores |
Replicación y Failover de Aplicaciones |
Arquitectura de Clúster de Kubernetes K3S |
Guía de instalación de k3s.safe para Kubernetes K3S |
| Nube AWS |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo en AWS |
Guía de instalación de mirror.safe para AWS |
| Nube AWS |
Equilibrio de Carga de Red y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga en AWS |
Guía de instalación de farm.safe para AWS |
| Nube GCP |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo en GCP |
Guía de instalación de mirror.safe para GCP |
| Nube GCP |
Equilibrio de Carga de Red y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga en GCP |
Guía de instalación de farm.safe para GCP |
| Nube Azure |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo en Azure |
Guía de instalación de mirror.safe para Azure |
| Nube Azure |
Equilibrio de Carga de Red y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga en Azure |
Guía de instalación de farm.safe para Azure |
| Nube |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo en la Nube |
Guía de instalación de mirror.safe para la Nube |
| Nube |
Equilibrio de Carga de Red y Failover de Aplicaciones |
Arquitectura de Equilibrio de Carga en la Nube |
Guía de instalación de farm.safe para la Nube |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de Milestone XProtect |
Guía de instalación de milestone.safe para Milestone XProtect |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de Nedap AEOS |
Guía de instalación de nedap.safe para Nedap AEOS |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de Genetec SQL |
Guía de instalación de sqlserver.safe para Genetec (SQL Server) |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Bosch AMS |
Guía de instalación de hyperv.safe para Bosch AMS |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Bosch BIS |
Guía de instalación de hyperv.safe para Bosch BIS |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Bosch BVMS |
Guía de instalación de hyperv.safe para Bosch BVMS |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Hanwha Vision |
Guía de instalación de hyperv.safe para Hanwha Vision |
| Seguridad Física / VMS |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Hanwha Wisenet |
Guía de instalación de hyperv.safe para Hanwha Wisenet |
| Productos Siemens |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Siemens Siveillance |
Guía de instalación de hyperv.safe para la suite Siemens Siveillance |
| Productos Siemens |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Siemens Desigo CC |
Guía de instalación de hyperv.safe para Siemens Desigo CC |
| Productos Siemens |
Replicación en Tiempo Real y Failover de Aplicaciones |
Arquitectura de Clúster de Espejo de Siemens Siveillance |
Guía de instalación de SiveillanceVMS.safe para Siemens Siveillance VMS |
| Productos Siemens |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Siemens SiPass |
Guía de instalación de hyperv.safe para Siemens SiPass |
| Productos Siemens |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de Siemens SIPORT |
Guía de instalación de hyperv.safe para Siemens SIPORT |
| Productos Siemens |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de SIMATIC PCS 7 |
Guía de instalación de hyperv.safe para Siemens SIMATIC PCS 7 |
| Productos Siemens |
Replicación en Tiempo Real y Failover de VMs |
Arquitectura de HA para VM de SIMATIC WinCC |
Guía de instalación de hyperv.safe para Siemens SIMATIC WinCC |