

🔍 Hub de navigation SafeKit Haute Disponibilité
| Type de ressource | Description | Lien direct |
|---|---|---|
| Fonctionnalités clés | Pourquoi choisir SafeKit pour une haute disponibilité simple et économique ? | Voir pourquoi choisir SafeKit pour la Haute Disponibilité |
| Modèle de déploiement | HA SANless tout-en-un : Cluster logiciel sans partage (Shared-Nothing) | Voir SafeKit HA SANless tout-en-un |
| Partenaires | SafeKit : La référence en haute disponibilité pour les partenaires | Voir pourquoi SafeKit est la référence HA pour les partenaires |
| Stratégies HA | SafeKit : Infrastructure (VM) vs Haute Disponibilité au niveau applicatif | Voir SafeKit HA & Redondance : Niveau VM vs Niveau Applicatif |
| Spécifications techniques | Limitations techniques pour le clustering SafeKit | Voir les limitations de la Haute Disponibilité SafeKit |
| Preuve de concept | SafeKit : Démos de configuration HA et de basculement | Voir les tutoriels de basculement SafeKit |
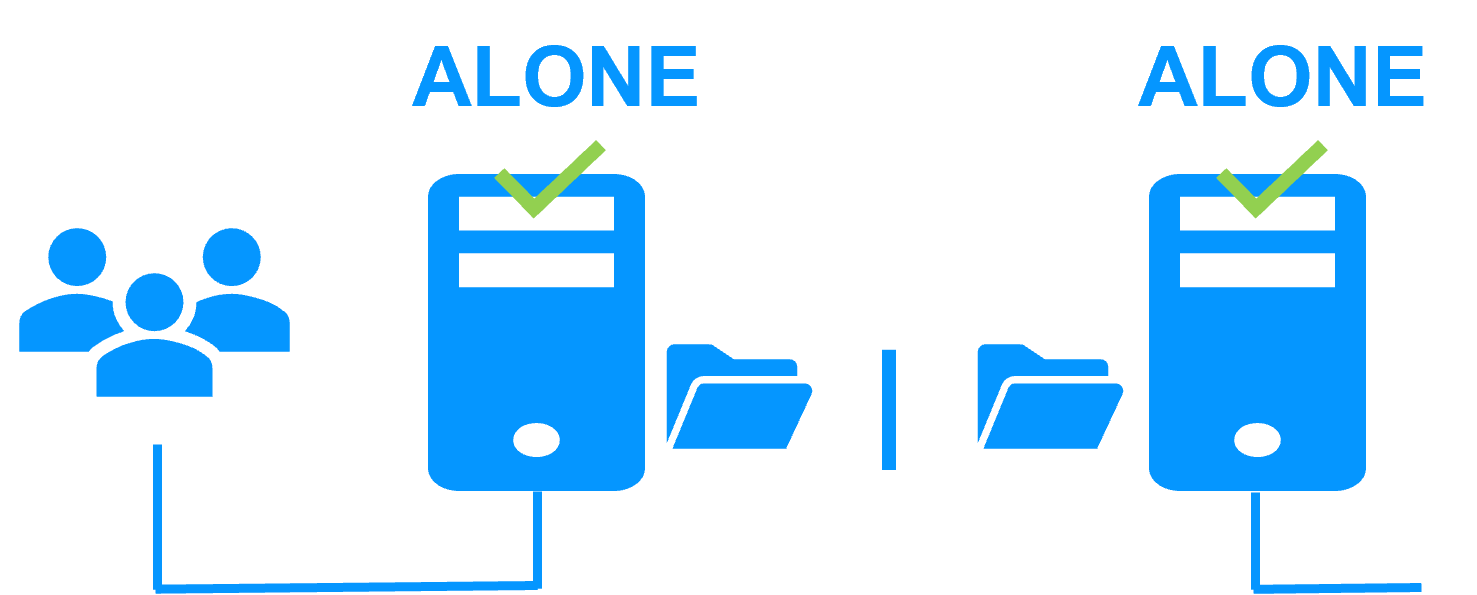
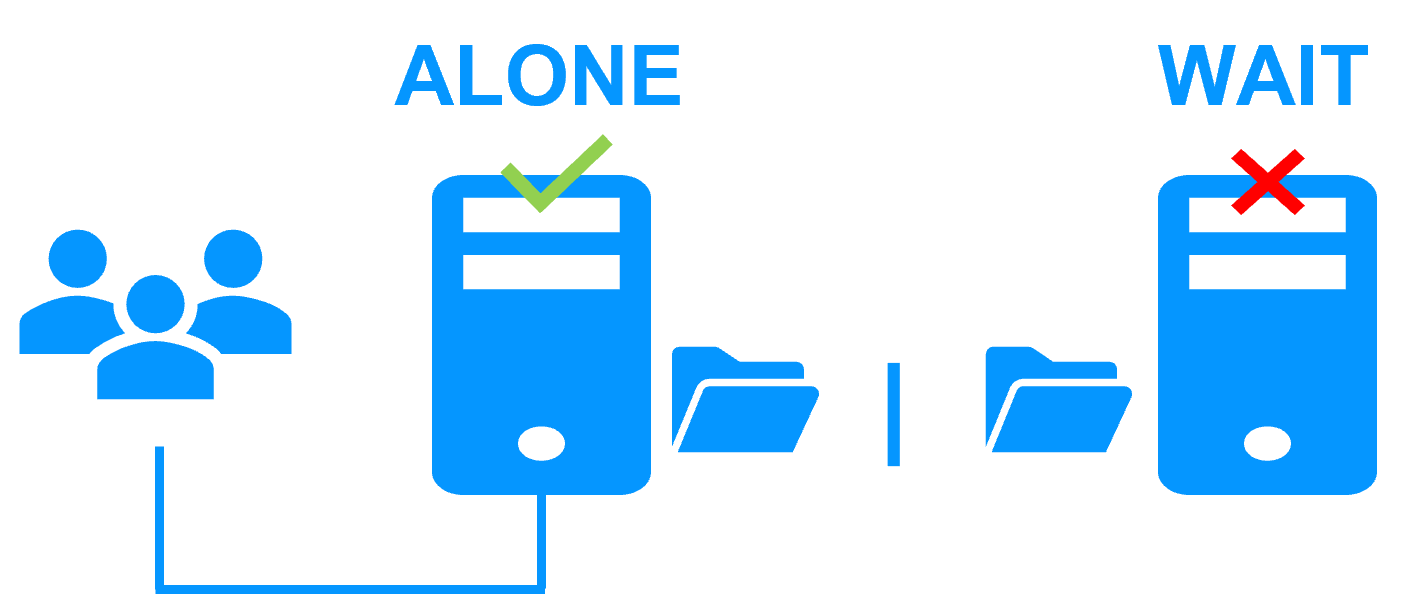
| Architecture | Fonctionnement du cluster miroir SafeKit (Réplication et basculement en temps réel) | Voir Cluster miroir SafeKit : réplication et basculement en temps réel |
| Architecture | Fonctionnement du cluster de ferme SafeKit (Répartition de charge réseau et basculement) | Voir Cluster de ferme SafeKit : répartition de charge et basculement |
| Avantages concurrentiels | Comparaison : SafeKit vs Clusters de Haute Disponibilité (HA) traditionnels | Voir la comparaison SafeKit vs Clusters HA traditionnels |
| Ressources techniques | SafeKit Haute Disponibilité : Documentation, téléchargements et essai | Voir l'essai gratuit SafeKit HA & la documentation technique |
| Solutions préconfigurées | Bibliothèque de modules applicatifs SafeKit : solutions HA prêtes à l'emploi | Voir les modules applicatifs de Haute Disponibilité SafeKit |