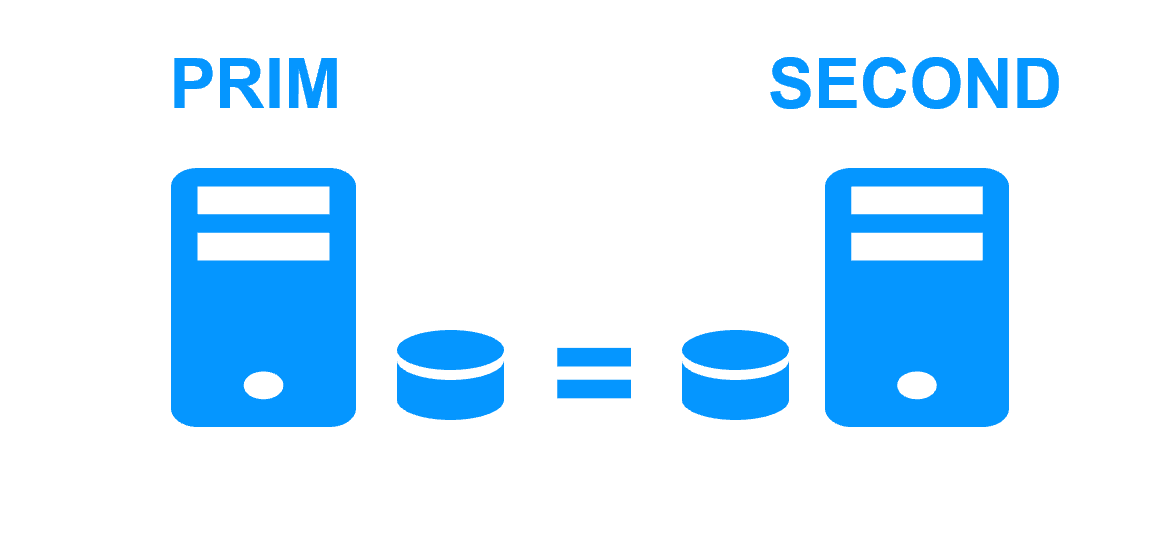
Step 1. Real-time replication
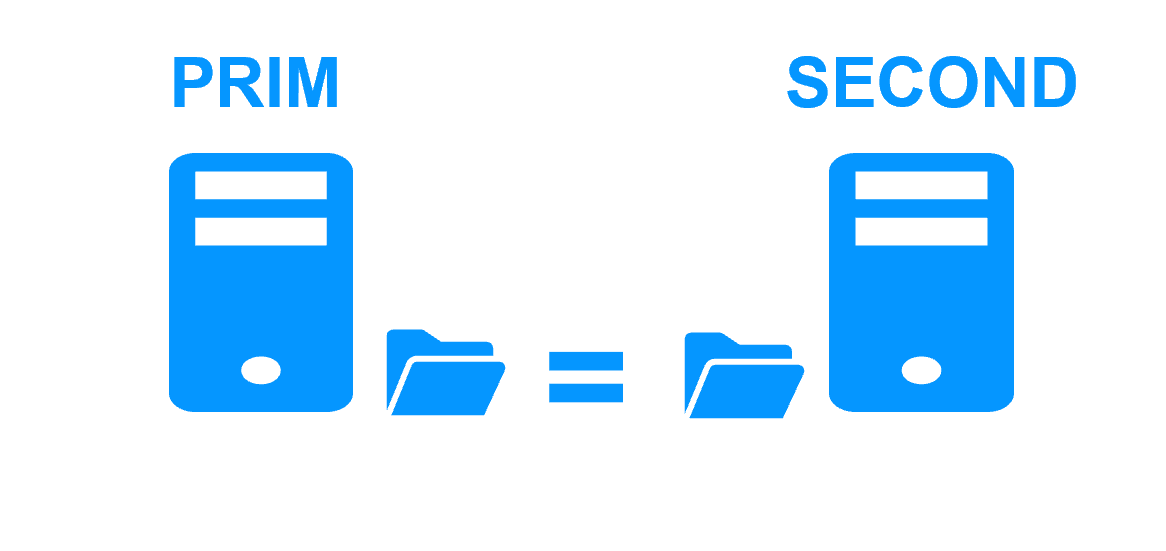
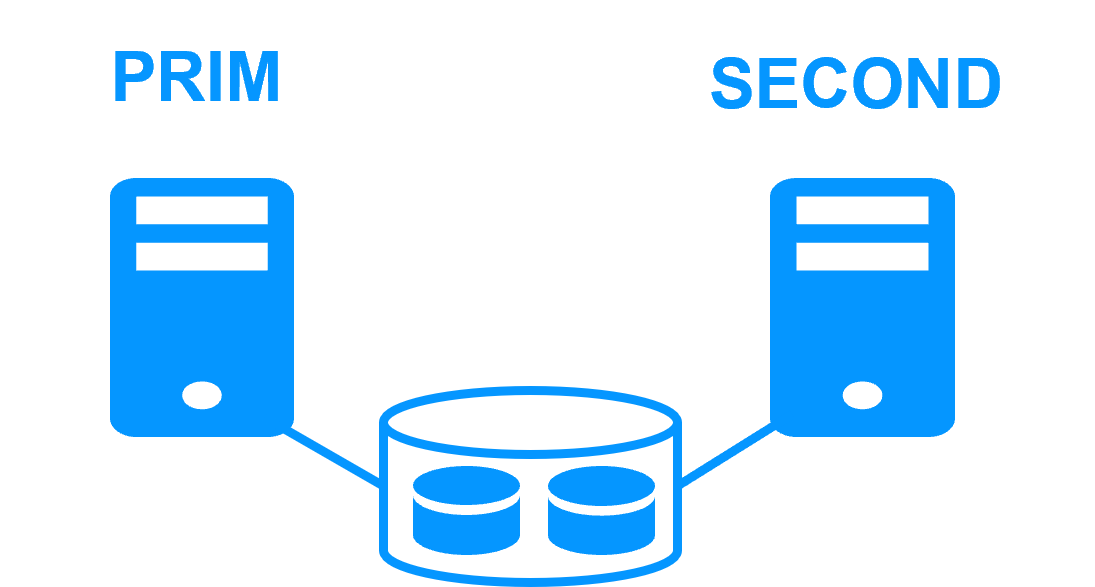
Server 1 (PRIM) runs the Windows or Linux application. Clients are connected to a virtual IP address. SafeKit replicates in real time modifications made inside files through the network.
The replication is synchronous with no data loss on failure contrary to asynchronous replication.
You just have to configure the names of directories to replicate in SafeKit. There are no pre-requisites on disk organization. Directories may be located in the system disk.
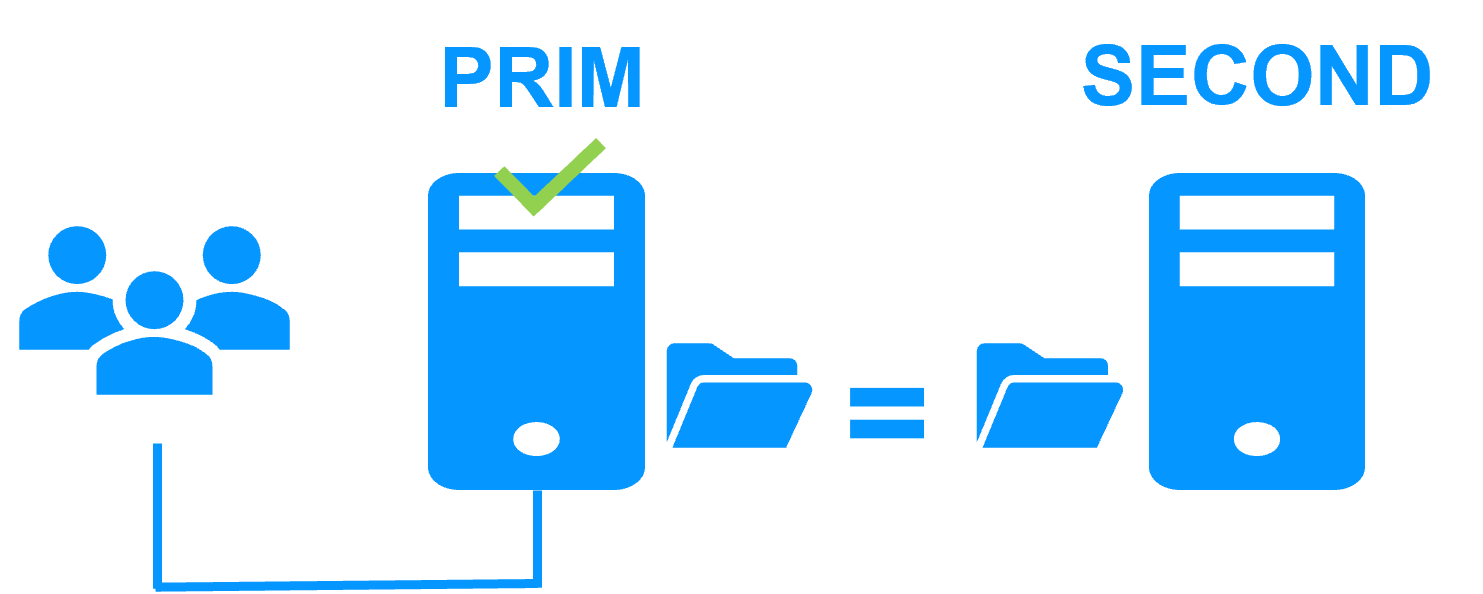
Step 2. Automatic failover
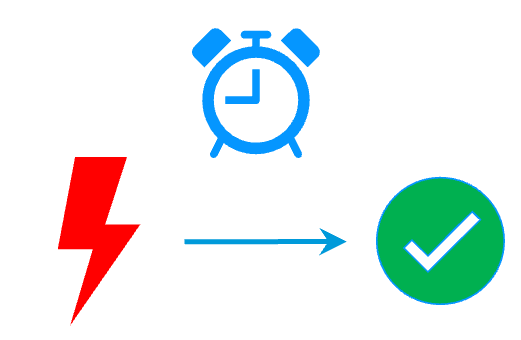
When Server 1 fails, Server 2 takes over. SafeKit switches the virtual IP address and restarts the Windows or Linux application automatically on Server 2.
The application finds the files replicated by SafeKit uptodate on Server 2. The application continues to run on Server 2 by locally modifying its files that are no longer replicated to Server 1.
The failover time is equal to the fault-detection time (30 seconds by default) plus the application start-up time.
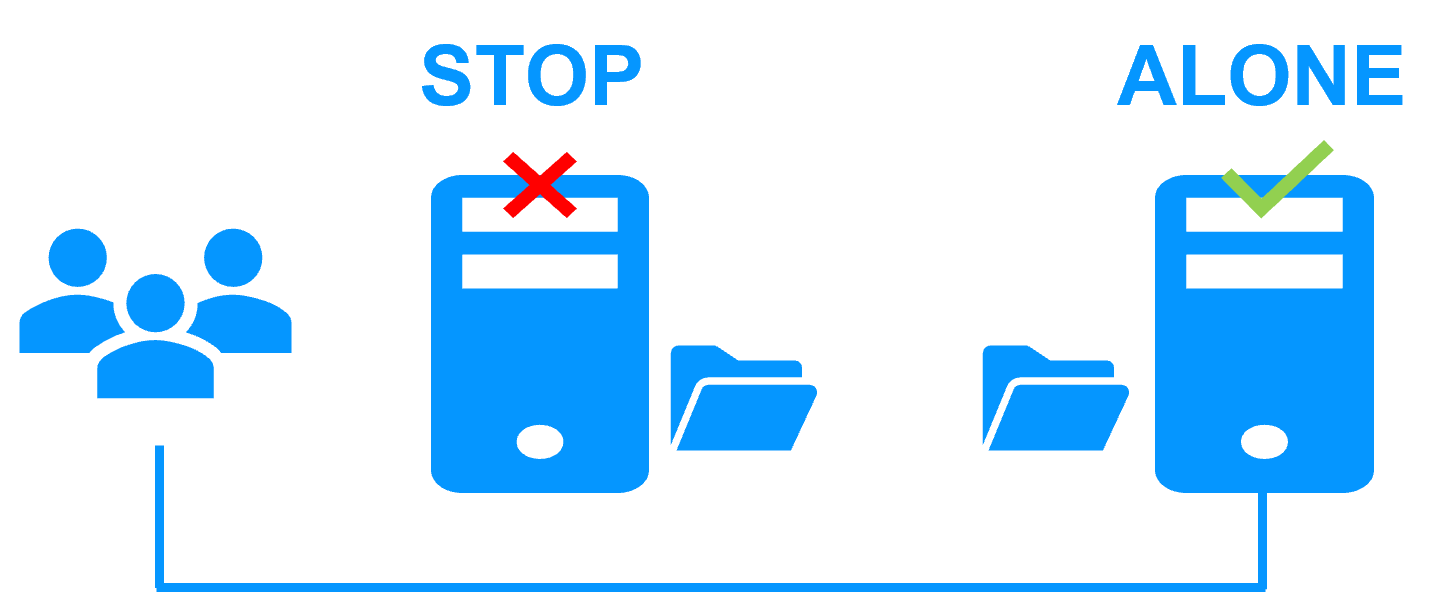
Step 3. Automatic failback
Failback involves restarting Server 1 after fixing the problem that caused it to fail.
SafeKit automatically resynchronizes the files, updating only the files modified on Server 2 while Server 1 was halted.
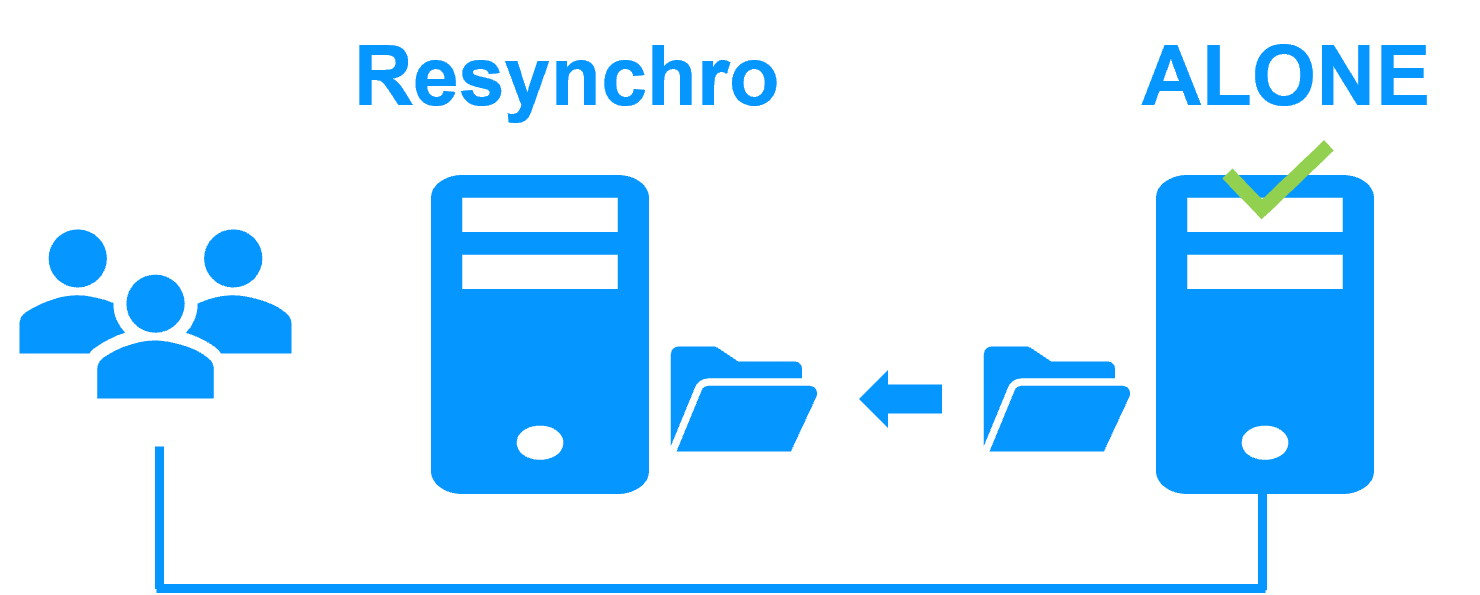
Failback takes place without disturbing the Windows or Linux application, which can continue running on Server 2.
Step 4. Back to normal
After reintegration, the files are once again in mirror mode, as in step 1. The system is back in high-availability mode, with the Windows or Linux application running on Server 2 and SafeKit replicating file updates to Server 1.
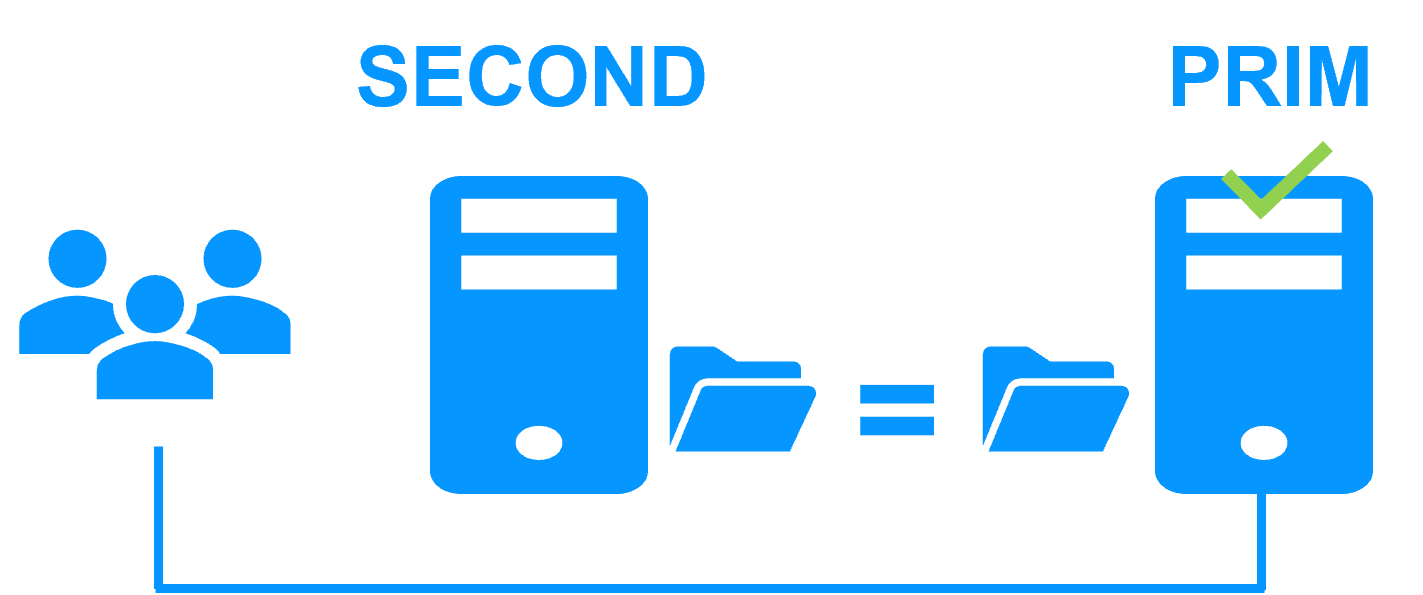
If the administrator wishes the application to run on Server 1, he/she can execute a "swap" command either manually at an appropriate time, or automatically through configuration.









Redundancy at the application level
In this type of solution, only application data are replicated. And only the application is restared in case of failure.
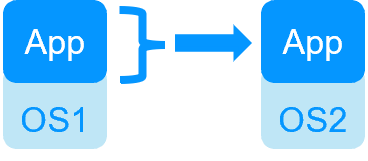
With this solution, restart scripts must be written to restart the application.
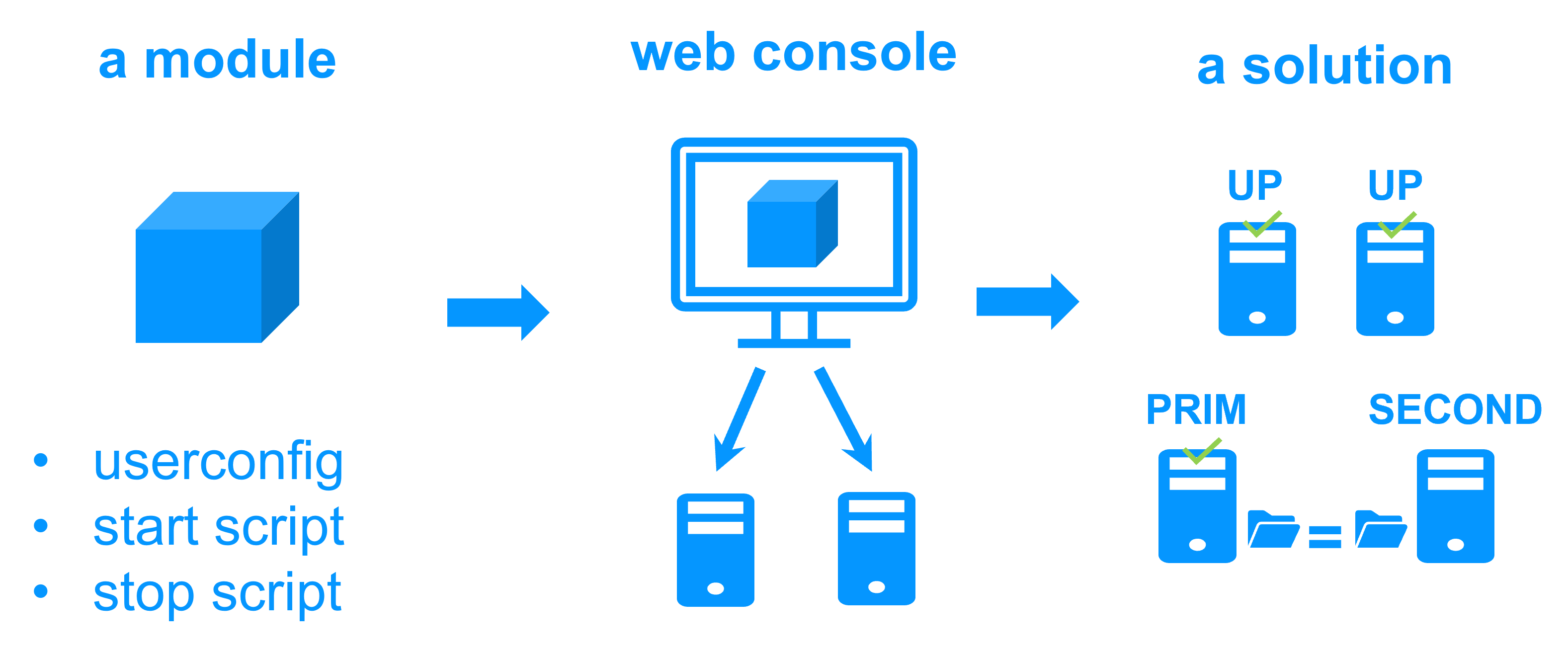
We deliver application modules to implement redundancy at the application level (like the mirror module provided in the free trial below). They are preconfigured for well known applications and databases. You can customize them with your own services, data to replicate, application checkers. And you can combine application modules to build advanced multi-level architectures.
This solution is platform agnostic and works with applications inside physical machines, virtual machines, in the Cloud. Any hypervisor is supported (VMware, Hyper-V...).
Redundancy at the virtual machine level
In this type of solution, the full Virtual Machine (VM) is replicated (Application + OS). And the full VM is restarted in case of failure.
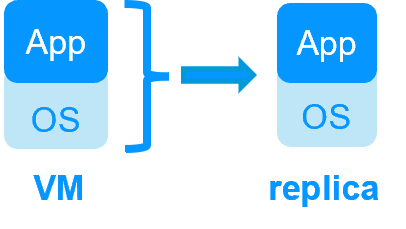
The advantage is that there is no restart scripts to write per application and no virtual IP address to define. If you do not know how the application works, this is the best solution.
This solution works with Windows/Hyper-V and Linux/KVM but not with VMware. This is an active/active solution with several virtual machines replicated and restarted between two nodes.
- Solution for a new application (no restart script to write): Windows/Hyper-V, Linux/KVM
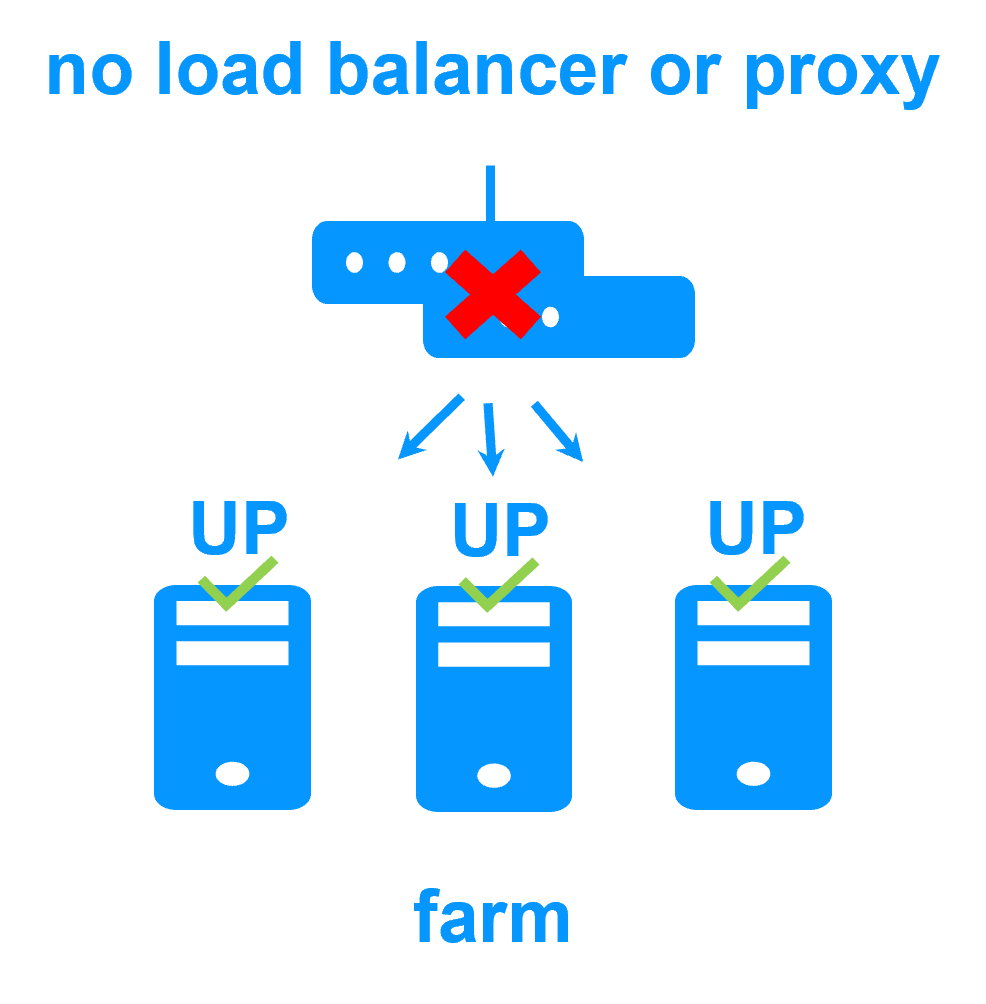
Network load balancing and failover |
|
| Windows farm | Linux farm |
| Generic Windows farm > | Generic Linux farm > |
| Microsoft IIS > | - |
| NGINX > | |
| Apache > | |
| Amazon AWS farm > | |
| Microsoft Azure farm > | |
| Google GCP farm > | |
| Other cloud > | |